本文主要是介绍RocksDB是如何实现存算分离的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
核心参考文献: Dong, S., P, S. S., Pan, S., Ananthabhotla, A., Ekambaram, D., Sharma, A., Dayal, S., Parikh, N. V., Jin, Y., Kim, A., Patil, S., Zhuang, J., Dunster, S., Mahajan, A., Chelluri, A., Datye, C., Santana, L. V., Garg, N., & Gawde, O. (2023). Disaggregating RocksDB: A Production Experience. Proceedings of the ACM on Management of Data, 1(2), 1–24. https://doi.org/10.1145/3589772
动机
为什么RocksDB要做存算分离?
单机的磁盘(存储能力)和CPU(计算能力)的配比常常不均衡,有时计算能力会有富裕,有时存储能力会有富裕。而且每个服务都需要预留一些存储空间。积少成多就会导致存储空间或计算能力的浪费。如果能把磁盘放在一个池子里,就能减少要预留的空间(100个服务,各预留1TB,vs 100个服务,总共预留10TB),避免空间浪费
为什么基于RocksDB改造而不是从头开发?
- 即使是在存算分离的场景,大部分用例也是受限于存储空间,而非IO吞吐量,RocksDB在存储时需要多占用的空间较少
- 方便用户迁移,几乎没有学习成本
- 维护一个引擎比维护两个引擎的工作量更小
- LSM tree很适合拉远存储(disaggregated storage)。
什么时候不要用存算分离?
- 对时延和吞吐量有极高要求的场景(笔者注:通过合理的设计,充分利用本地缓存,事实上存算分离的架构可以满足极致时延和极高吞吐量场景的需求)
- 要求简单可靠的场景。例如OBS的元信息管理就很难再使用一套存算分离的元信息存储系统。
挑战和对策
挑战1:如何在存算分离的条件下提供令人满意的性能?
对策1.1 优化IO时延
- 如果第一个IO请求在一定时间内没有返回,就立即发出第二个(相同的)IO请求
- hedged quorum full block wirtes
对策1.2 缓存元信息
- 缓存目录结构到本地。列出目录结构是高频操作,并且目录结构只能由一个进程修改,因此可以对目录结构进行缓存。
对策1.3 在本地磁盘缓存脏的block(secondary cache),效果如图
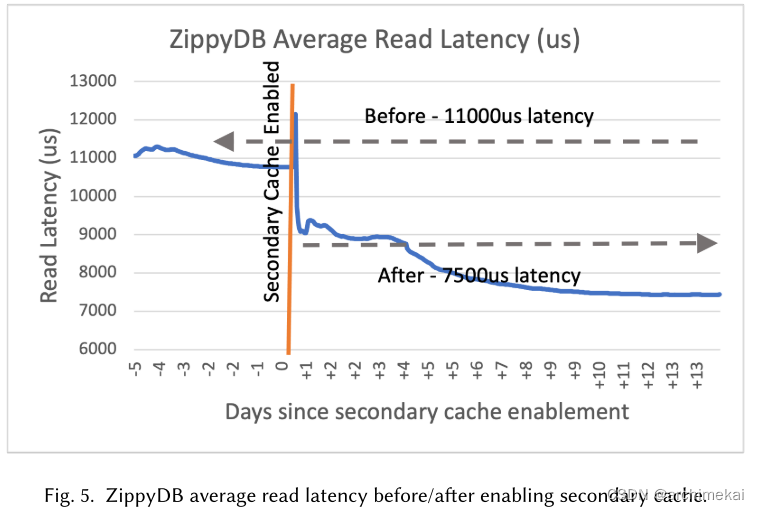
对策1.4 RocksDB IO调优
- 增大compaction read size 到4MB或8MB,增大compaction write buffer到64MB或更大
- 从拉远存储中预读取更多的数据(可以基于历史情况预测要预读的数据大小)
对策1.5 同时发出多个IO请求以降低MultiGet时延
挑战2:如何以较低的开销支持多副本?
- SST数据文件需要同时具备高可靠(高持久性)和低开销,使用Facebook Tectonic文件系统提供的 [12,8] encoding ,即可仅使用1.5倍的空间和写入贷款,同时能够达到SLA要求
- WAL和其他日志文件需要支持低时延的写入。使用5路副本。
挑战3:存在多副本时,如何确保只有一个进程能修改(写)同一份数据?
对zookeeper或etcd,paxos或raft有一定了解的读者能发现,这一问题是经典的分布式共识问题。要达成共识的对象是当前哪个进程能够修改数据。
RocksDB使用了IO Fencing技术来实现。该技术类似于一种基于单调递增时间戳的分布式锁。
其他修改
允许远程IO操作和本地IO操作使用不同的时延,从而降低远程操作超时的可能性
区分哪些远程操作的错误可以重试,避免出错后rocksdb立即进入只读状态
这篇关于RocksDB是如何实现存算分离的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





