本文主要是介绍Kafka 记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
推荐资源
| 官网 | http://kafka.apache.org/ |
| Github | https://github.com/apache/kafka |
| 书籍 | 《深入理解Kafka 核心设计与实践原理》 |
Kafka 架构
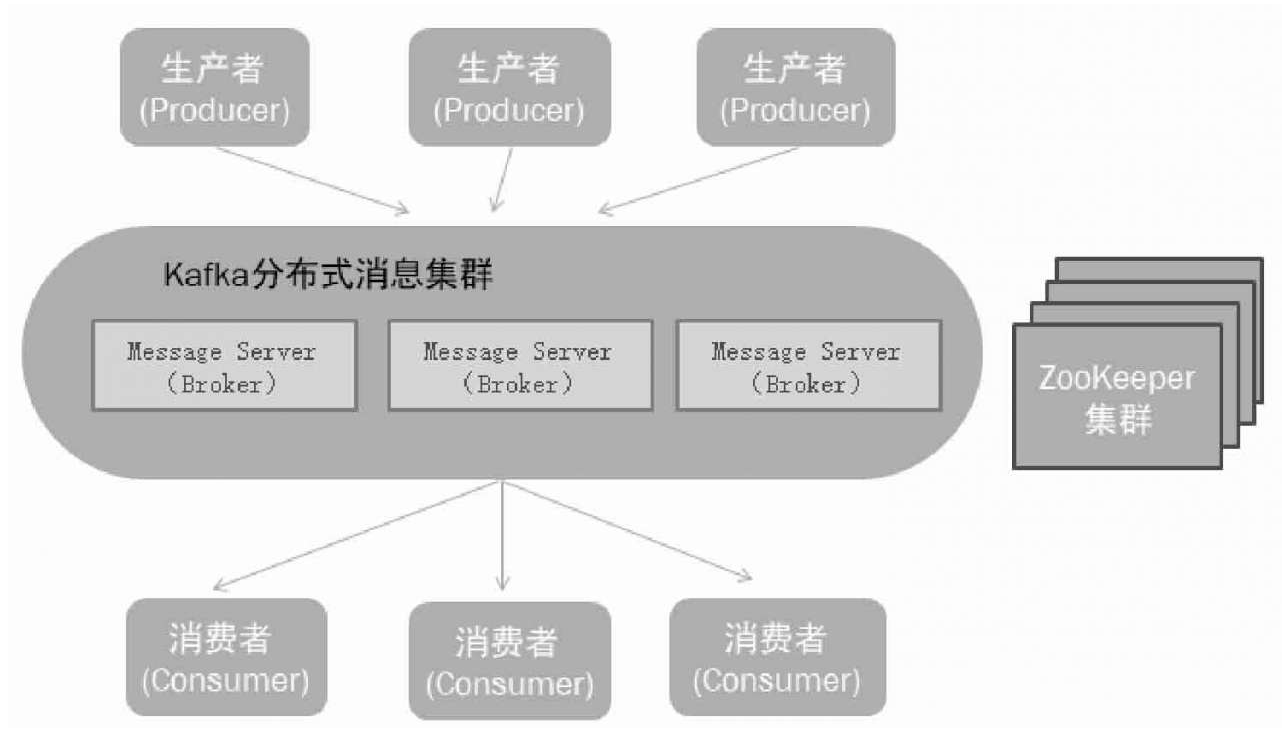
Kafka使用ZooKeeper作为其分布式协调框架,其动态扩容是通过ZooKeeper来实现的。Kafka使用Zookeeper保存broker的元数据和消费者信息。Kafka元数据信息包括如代理节点信息、Kafka集群信息、旧版消费者信息及其消费偏移量信息、主题信息、分区状态信息、分区副本分配方案信息、动态配置信息等。Kafka在启动或运行过程当中会在ZooKeeper上创建相应节点来保存元数据信息,Kafka通过监听机制在这些节点注册相应监听器来监听节点元数据的变化,从而由ZooKeeper负责管理维护Kafka集群,同时通过ZooKeeper我们能够很方便地对Kafka集群进行水平扩展及数据迁移。后面新版本有KRaft(Kafka Raft)代替Zookeeper。
Kafka Ecosystem 生态系统
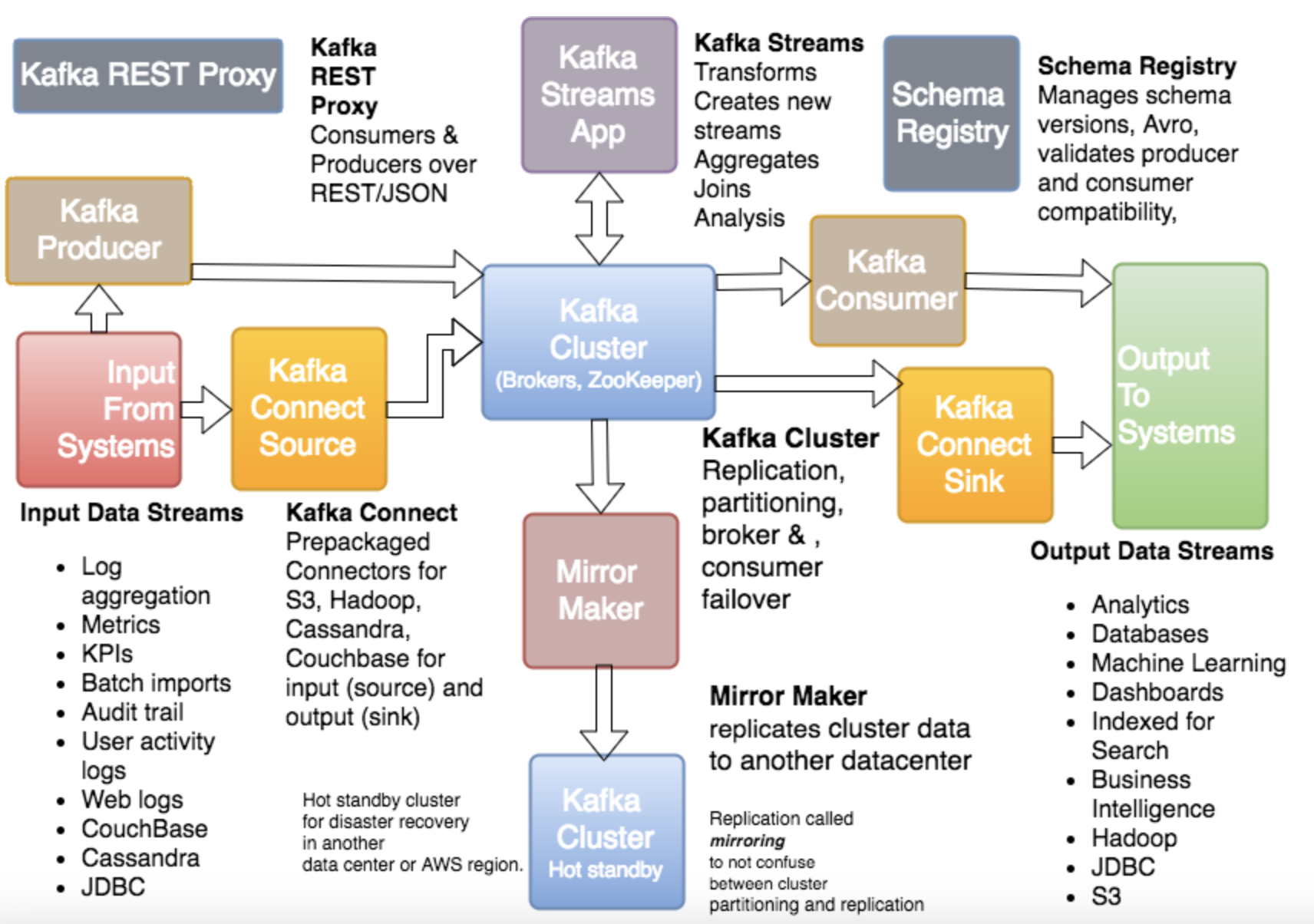
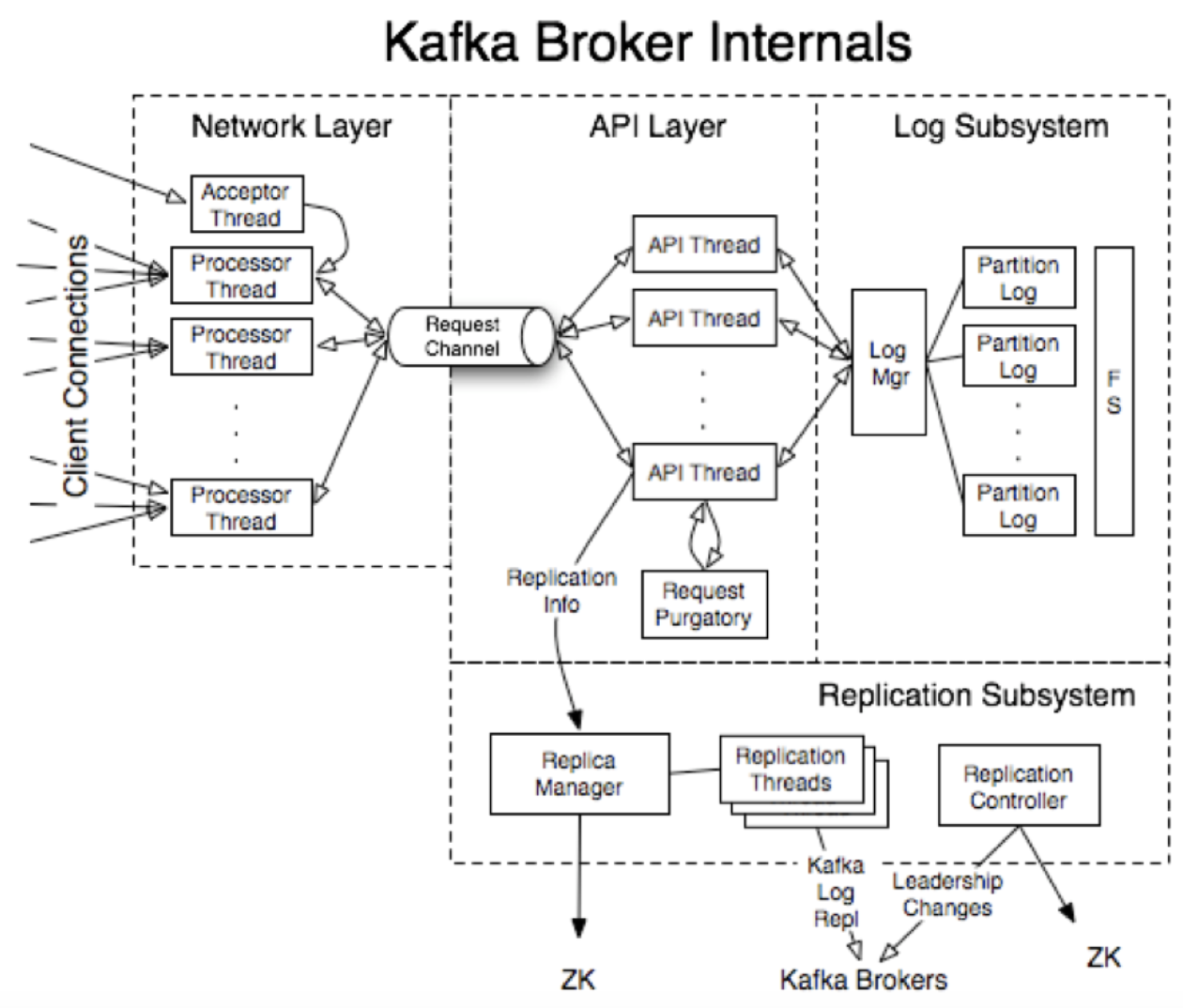
Kafka 核心概念
Topic
Topic:特指Kafka处理的消息源的不同分类。
Kafka的消息通过主题进行分类。(主题好比数据库中的表,或者文件系统里的文件夹)主题可以被分为若干个分区。一个分区就是一个提交日志。一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序,消息以追加的方式写入分区,然后以先入先出(消息队列)的顺序读取。为了提高效率,消息被分批次写入Kafka。批次就是一组消息,这些消息属于同一个主题(topic)和分区(Partition)。消息由字节数组组成。
Partition
Partition:Topic物理上的分组,一个Topic可以分为多个Partition,每个Partition是一个有序的队列。Partition中的每条消息都会被分配一个有序的id。
每个主题对应的分区数可以在Kafka启动时所加载的配置文件中配置,也可以在创建主题时指定。当然,客户端还可以在主题创建后修改主题的分区数。
分区使得Kafka在并发处理上变得更加容易,理论上来说,分区数越多吞吐量越高,但这要根据集群实际环境及业务场景而定。同时,分区也是Kafka保证消息被顺序消费以及对消息进行负载均衡的基础。
Kafka只能保证一个分区之内消息的有序性,并不能保证跨分区消息的有序性。每条消息被追加到相应的分区中,是顺序写磁盘,因此效率非常高,这是Kafka高吞吐率的一个重要保证。同时与传统消息系统不同的是,Kafka并不会立即删除已被消费的消息,由于磁盘的限制消息也不会一直被存储(事实上这也是没有必要的),因此Kafka提供两种删除老数据的策略,一是基于消息已存储的时间长度,二是基于分区的大小。
由于Kafka副本的存在,就需要保证一个分区的多个副本之间数据的一致性,Kafka会选择该分区的一个副本作为Leader副本,而该分区其他副本即为Follower副本,只有Leader副本才负责处理客户端读/写请求,Follower副本从Leader副本同步数据。如果没有Leader副本,那就需要所有的副本都同时负责读/写请求处理,同时还得保证这些副本之间数据的一致性,
Message
Message:消息,是通信的基本单位。每个Producer可以向一个Topic(主题)发布一些消息。
Kafka的数据单元被称为消息。(可以把消息看成是数据库里的一个“数据行”或“记录”)
Producer
Producer:消息和数据生产者。向Kafka的一个Topic发布消息的过程叫作Producer。
Consumer
Consumer:消息和数据消费者。订阅Topics并处理其发布的消息的过程叫作Consumer。
Broker
Broker:缓存代理。Kafka集群中的一台或多台服务器统称为Broker。一台Kafka服务器就是一个Broker。一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
Kafka集群就是由一个或多个Kafka实例构成,我们将每一个Kafka实例称为代理(Broker),通常也称代理为Kafka服务器(KafkaServer)。在生产环境中Kafka集群一般包括一台或多台服务器,我们可以在一台服务器上配置一个或多个代理。每一个代理都有唯一的标识id,这个id是一个非负整数。在一个Kafka集群中,每增加一个代理就需要为这个代理配置一个与该集群中其他代理不同的id, id值可以选择任意非负整数即可,只要保证它在整个Kafka集群中唯一,这个id就是代理的名字,也就是在启动代理时配置的broker.id对应的值。发布与订阅系统一般有一个broker,也就是发布消息的中心点。
Broker默认的消息保留策略是这样的:要么保留一段时间(比如7天),要么保留到消息达到一定大小的字节数(比如1GB)。
Relationship Overview for Broker, Producer, Consumer, Topic, Topic Partition, Replicas, Leader and Follower


ISR & OSR
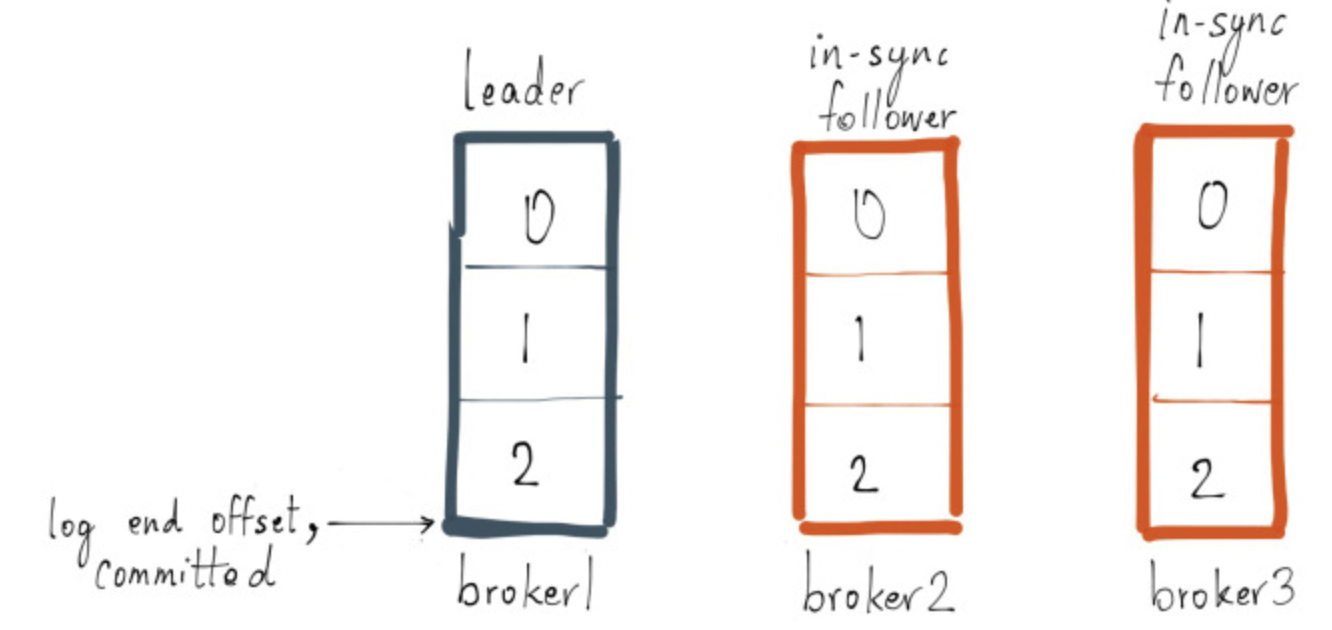

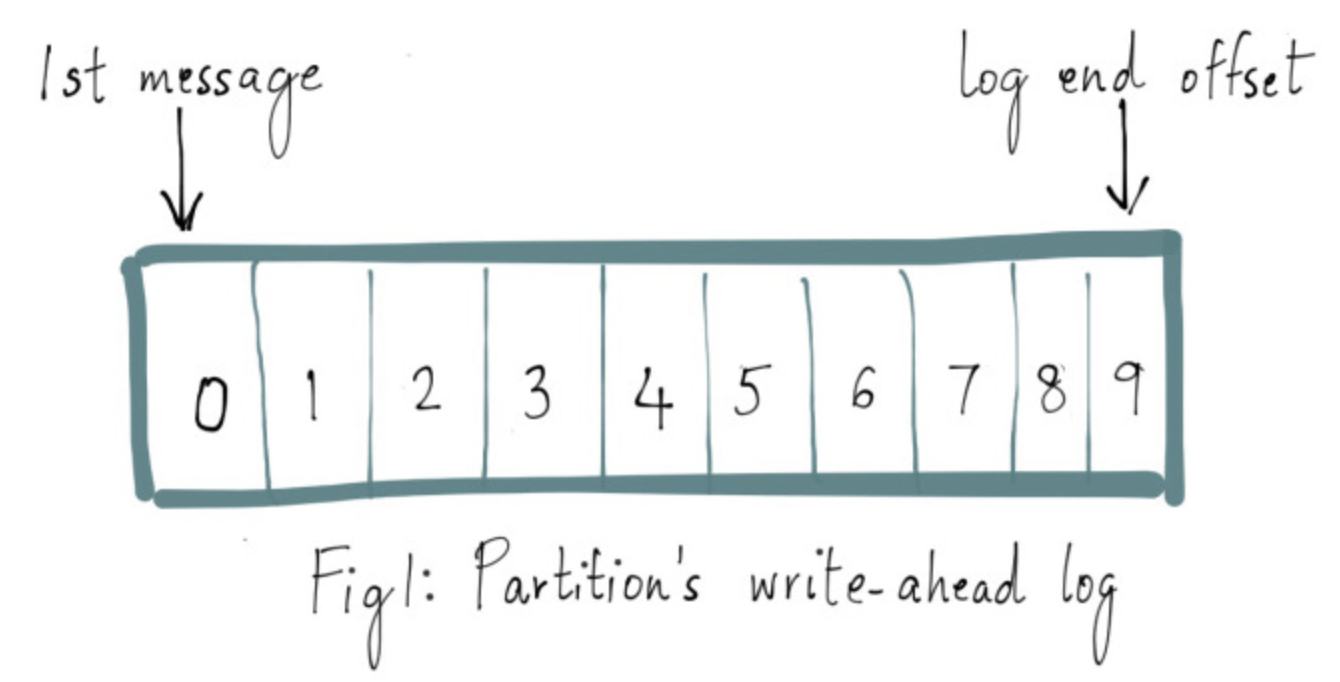
Log End Offset & WAL
ack
There are two settings here that affect the producer:
- acks - this is a producer-level setting
- min.insync.replicas - this is a topic-level setting
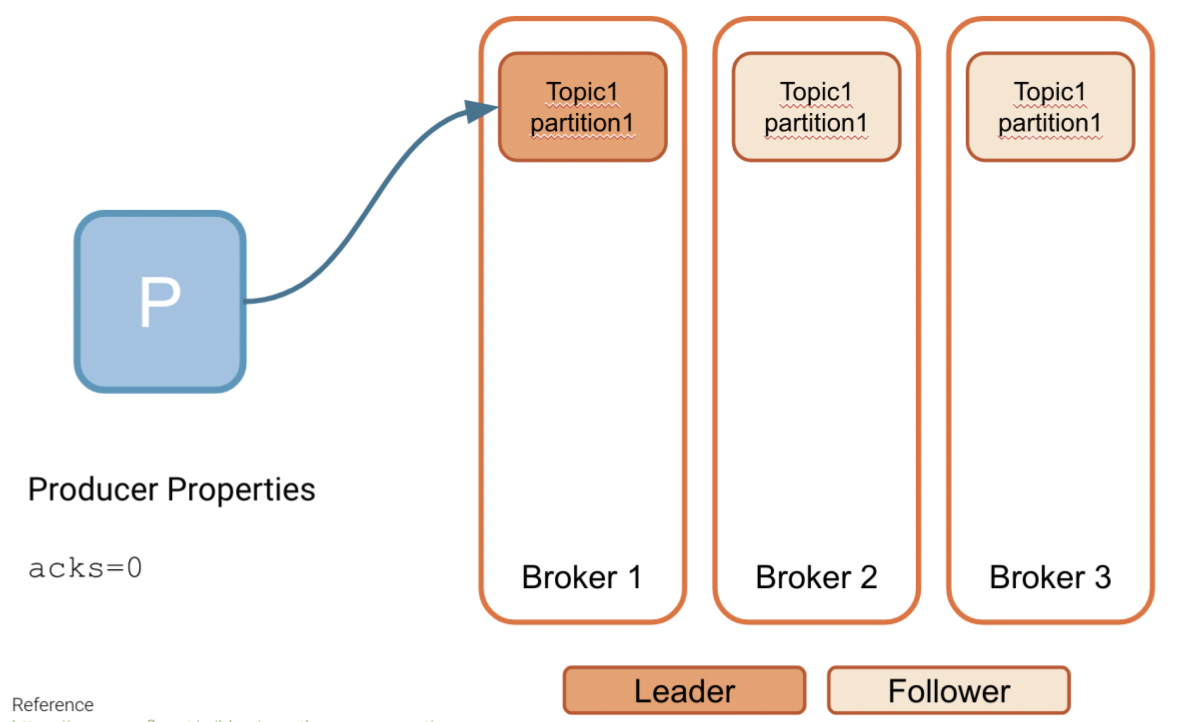
The acks property determines how you want to handle writing to kafka:
acks=0 - I don't care about receiving acknowledgment of receipt
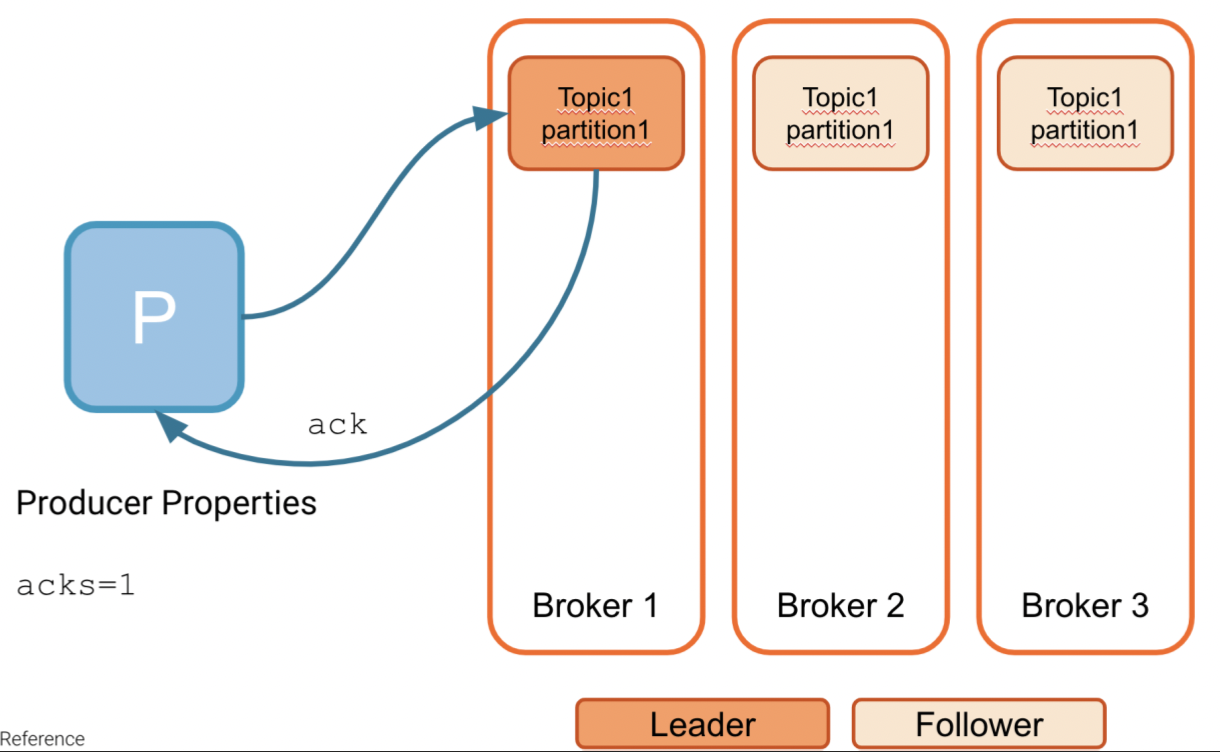
acks=1 - Send an acknowledgment when the leader partition has received the batch in memory
all/-1 - Wait for all replicas to receive the batch before sending an acknowledgment 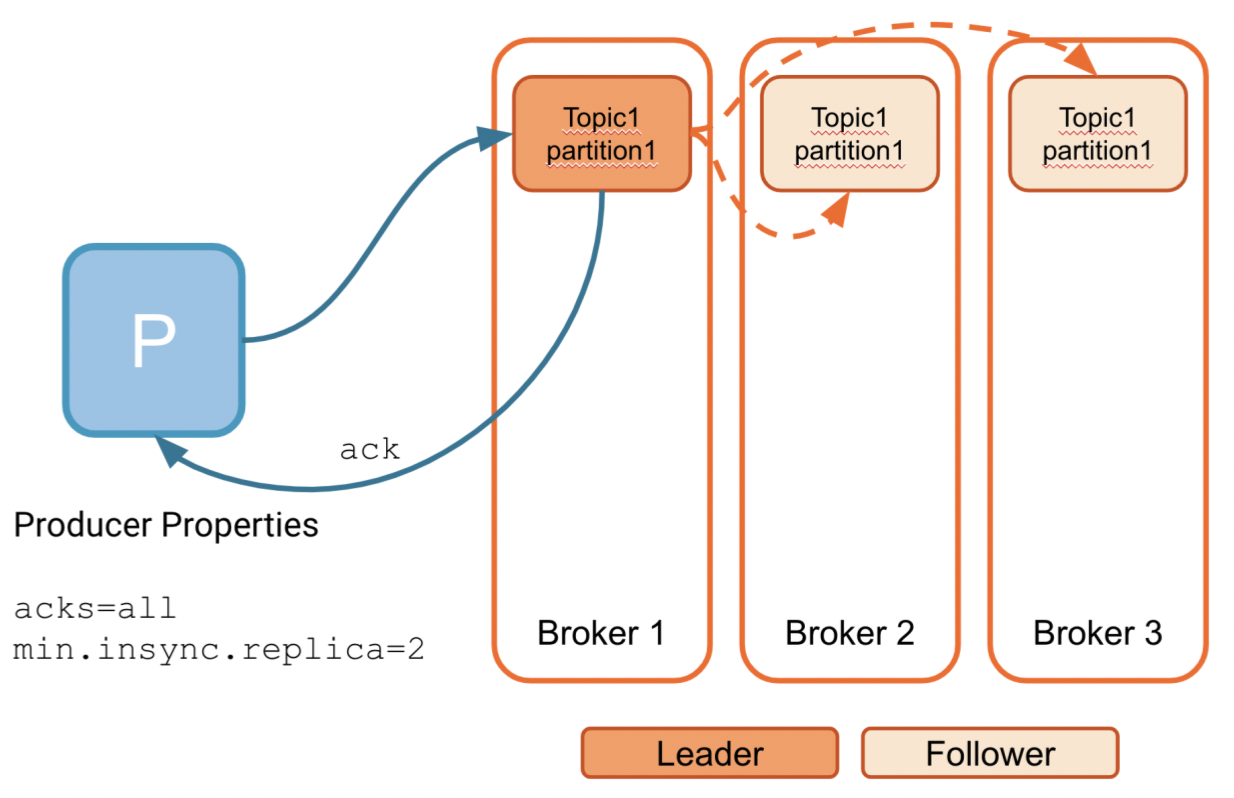
Kafka Producer Architecture and Workflow

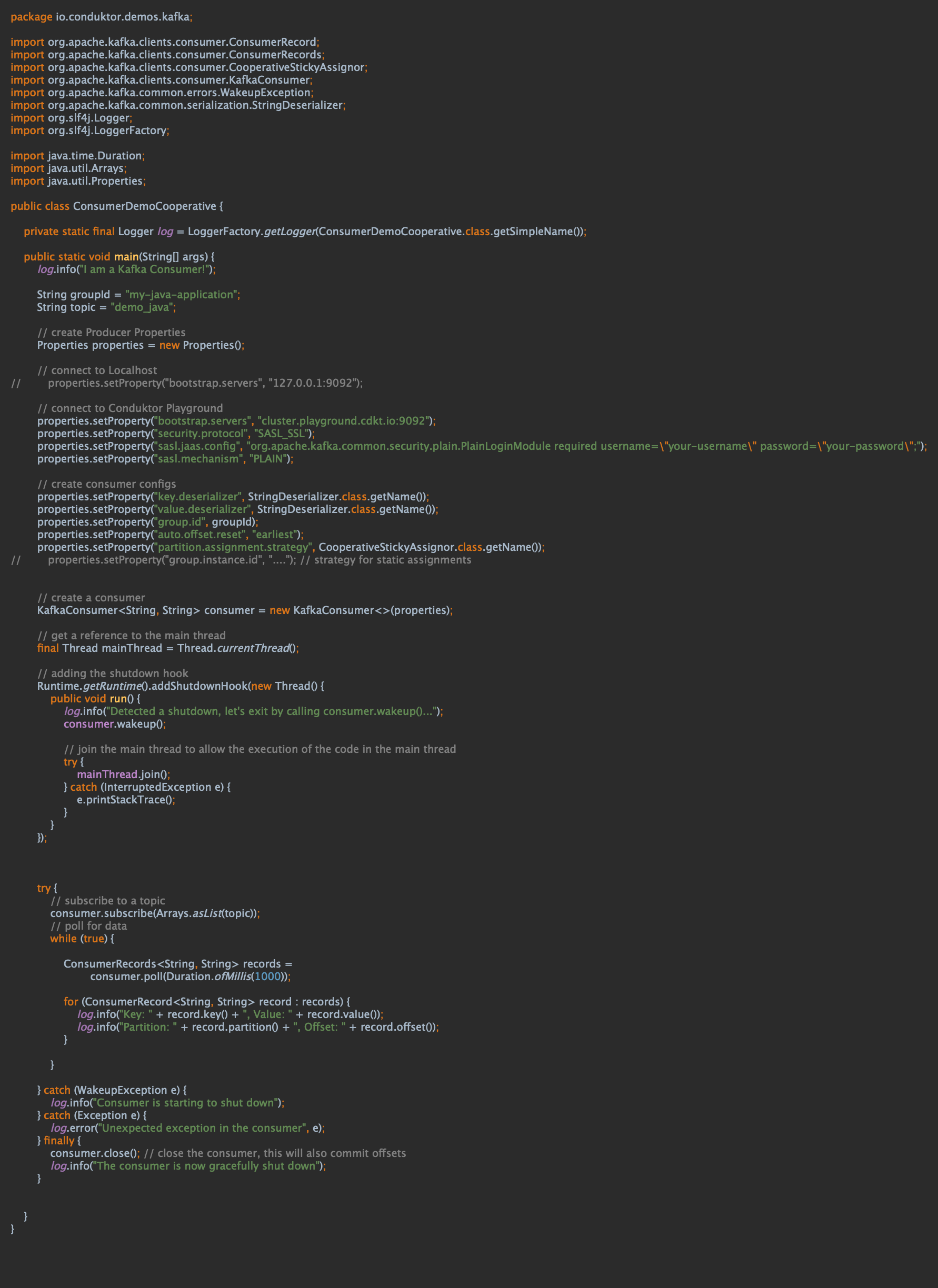
Java code
Producer:

Consumer:
如果处理重复消息
幂等处理重复消息
幂等是数学上的概念,我们就理解为同样的参数多次调用同一个接口和调用一次产生的结果是一致的。例如这条 SQL:update t1 set money = 150 where id = 1 and money = 100; 执行多少遍 money 都是150,这就叫幂等。
因此需要改造业务处理逻辑,使得在重复消息的情况下也不会影响最终的结果。
1. 前置条件判断
可以通过像上面 SQL 一样,做个前置条件判断,即 money = 100,并且直接修改;更通用的是做个 version 即版本号控制,对比消息中的版本号和数据库中的版本号。
2. 通过数据库的约束例如唯一键,例如 insert into update on duplicate key ...
3. 记录关键的key,例如处理订单,记录订单ID,假如有重复的消息过来,先判断下这个ID是否已经被处理过了,如果没处理再进行下一步。当然也可以用全局唯一ID等。
基本上就这么几个方式,真正应用到实际中还是得看具体业务细节。
如何保证消息不丢失
如何保证消息的有序性
消息队列的推拉模式
Kafka Admin (Setup, Operation, Monitoring)
(后续再整理)
这篇关于Kafka 记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







