本文主要是介绍1.29学习总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
并查集
1.并查集
2.亲戚
3.朋友(STL+并查集)
4.集合(质数筛+并查集)
5.修复公路(并查集+结构体排序)
搜索
1.机器人搬重物(BFS)
树状数组
1.树状数组1(单点修改,区间查询)
2.树状数组 2(区间修改,单点查询)
并查集
并查集的效率很高,复杂度在O(logn),操作简短,主要是初始化,寻找函数find,合并函数union
并查集https://www.luogu.com.cn/problem/P3367
题目描述
如题,现在有一个并查集,你需要完成合并和查询操作。
输入格式
第一行包含两个整数 �,�N,M ,表示共有 �N 个元素和 �M 个操作。
接下来 �M 行,每行包含三个整数 ��,��,��Zi,Xi,Yi 。
当 ��=1Zi=1 时,将 ��Xi 与 ��Yi 所在的集合合并。
当 ��=2Zi=2 时,输出 ��Xi 与 ��Yi 是否在同一集合内,是的输出 Y ;否则输出 N 。
输出格式
对于每一个 ��=2Zi=2 的操作,都有一行输出,每行包含一个大写字母,为 Y 或者 N 。
输入输出样例
输入 #1复制
4 7 2 1 2 1 1 2 2 1 2 1 3 4 2 1 4 1 2 3 2 1 4
输出 #1复制
N Y N Y
说明/提示
对于 30%30% 的数据,�≤10N≤10,�≤20M≤20。
对于 70%70% 的数据,�≤100N≤100,�≤103M≤103。
对于 100%100% 的数据,1≤�≤1041≤N≤104,1≤�≤2×1051≤M≤2×105,1≤��,��≤�1≤Xi,Yi≤N,��∈{1,2}Zi∈{1,2}。
思路:函数写出来,关系带进去就可以了
#include <bits/stdc++.h>
using namespace std;
int f[200005];
int n,m;
void init(int n)
{for (int i=1;i<=n;++i)f[i]=i;
}
int find(int x)
{if (f[x]==x)return x;else {f[x]=find(f[x]);return f[x];}
}
void unions(int i,int j)
{int f_i=find(i);int f_j=find(j);f[f_i]=f_j;
}
int main()
{cin>>n>>m;init(n);for (int i=0;i<m;++i){int a,b,c;cin>>a>>b>>c;if (a==1){unions(b,c);}else if (a==2){if (find(b)==find(c))cout<<"Y"<<endl;else cout<<"N"<<endl;}}
}亲戚https://www.luogu.com.cn/problem/P1551
题目背景
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。
题目描述
规定:�x 和 �y 是亲戚,�y 和 �z 是亲戚,那么 �x 和 �z 也是亲戚。如果 �x,�y 是亲戚,那么 �x 的亲戚都是 �y 的亲戚,�y 的亲戚也都是 �x 的亲戚。
输入格式
第一行:三个整数 �,�,�n,m,p,(�,�,�≤5000n,m,p≤5000),分别表示有 �n 个人,�m 个亲戚关系,询问 �p 对亲戚关系。
以下 �m 行:每行两个数 ��Mi,��Mj,1≤��, ��≤�1≤Mi, Mj≤n,表示 ��Mi 和 ��Mj 具有亲戚关系。
接下来 �p 行:每行两个数 ��,��Pi,Pj,询问 ��Pi 和 ��Pj 是否具有亲戚关系。
输出格式
�p 行,每行一个 Yes 或 No。表示第 �i 个询问的答案为“具有”或“不具有”亲戚关系。
输入输出样例
输入 #1复制
6 5 3 1 2 1 5 3 4 5 2 1 3 1 4 2 3 5 6
输出 #1复制
Yes Yes No
思路:同样的模版题
#include <bits/stdc++.h>
using namespace std;
int f[200005];
int n,m,q;
void init(int n)
{for (int i=1;i<=n;++i)f[i]=i;
}
int find(int x)
{if (f[x]==x)return x;else {f[x]=find(f[x]);return f[x];}
}
void unions(int i,int j)
{int f_i=find(i);int f_j=find(j);f[f_i]=f_j;
}
int main()
{cin>>n>>m>>q;init(n);for (int i=0;i<m;++i){int a,b;cin>>a>>b;unions(a,b);}for (int i=0;i<q;++i){int a,b;cin>>a>>b;if (find(a)==find(b))cout<<"Yes"<<endl;else cout<<"No"<<endl;}
}朋友https://www.luogu.com.cn/problem/P2078
题目背景
小明在 A 公司工作,小红在 B 公司工作。
题目描述
这两个公司的员工有一个特点:一个公司的员工都是同性。
A 公司有 �N 名员工,其中有 �P 对朋友关系。B 公司有 �M 名员工,其中有 �Q 对朋友关系。朋友的朋友一定还是朋友。
每对朋友关系用两个整数 (��,��)(Xi,Yi) 组成,表示朋友的编号分别为 ��,��Xi,Yi。男人的编号是正数,女人的编号是负数。小明的编号是 11,小红的编号是 −1−1。
大家都知道,小明和小红是朋友,那么,请你写一个程序求出两公司之间,通过小明和小红认识的人最多一共能配成多少对情侣(包括他们自己)。
输入格式
输入的第一行,包含 44 个空格隔开的正整数 �,�,�,�N,M,P,Q。
之后 �P 行,每行两个正整数 ��,��Xi,Yi。
之后 �Q 行,每行两个负整数 ��,��Xi,Yi。
输出格式
输出一行一个正整数,表示通过小明和小红认识的人最多一共能配成多少对情侣(包括他们自己)。
输入输出样例
输入 #1复制
4 3 4 2 1 1 1 2 2 3 1 3 -1 -2 -3 -3
输出 #1复制
2
说明/提示
对于 30%30% 的数据,�,�≤100N,M≤100,�,�≤200P,Q≤200;
对于 80%80% 的数据,�,�≤4×103N,M≤4×103,�,�≤104P,Q≤104;
对于 100%100% 的数据,�,�≤104N,M≤104,�,�≤2×104P,Q≤2×104。
思路:用map容器,把他们放到一个并查集里面,然后寻找两个公司里面最少的关系,因为1和-1是有关系的,所以就看两个公司那个公司关系的人更少了
#include <bits/stdc++.h>
using namespace std;
map<int,int>f;
int find(int x)
{if (f[x]==x)return x;else {f[x]=find(f[x]);return f[x];}
}
void unionn(int i,int j)
{int s_i=find(i);int s_j=find(j);f[s_i]=s_j;
}
int main()
{int n,m,p,q;cin>>n>>m>>p>>q;for (int i=-m;i<=n;++i){if (i==0)continue;f[i]=i;}for (int i=0;i<p+q;++i){int a,b;cin>>a>>b;unionn(a,b);}int cnt1=0,cnt2=0;for (int i=1;i<=n;++i){if (find(i)==find(1))cnt1++;}for (int i=-m;i<=-1;++i){if (find(i)==find(-1))cnt2++;}cout<<min(cnt1,cnt2);
}集合https://www.luogu.com.cn/problem/P1621
题目描述
Caima 给你了所有 [�,�][a,b] 范围内的整数。一开始每个整数都属于各自的集合。每次你需要选择两个属于不同集合的整数,如果这两个整数拥有大于等于 �p 的公共质因数,那么把它们所在的集合合并。
重复如上操作,直到没有可以合并的集合为止。
现在 Caima 想知道,最后有多少个集合。
输入格式
一行,共三个整数 �,�,�a,b,p,用空格隔开。
输出格式
一个数,表示最终集合的个数。
输入输出样例
输入 #1复制
10 20 3
输出 #1复制
7
说明/提示
样例 1 解释
对于样例给定的数据,最后有 {10,20,12,15,18},{13},{14},{16},{17},{19},{11}{10,20,12,15,18},{13},{14},{16},{17},{19},{11} 共 77 个集合,所以输出应该为 77。
数据规模与约定
- 对于 80%80% 的数据,1≤�≤�≤1031≤a≤b≤103。
- 对于 100100 的数据,1≤�≤�≤105,2≤�≤�1≤a≤b≤105,2≤p≤b。
思路:主要用了质数筛法和并查集,
#include <bits/stdc++.h>
using namespace std;
const int N=1e5+5;
int a,b,p;
int f[N];
int flag[N];
int vis[N],minprime[N];
void is_prime(int a)
{memset(vis,1,sizeof(vis));vis[0]=0,vis[1]=0;for (int i=2;i*i<=a;++i){if (vis[i]){for (int j=i*i;j<a;j+=i){vis[j]=0;}}}
}
bool is_true(int a,int b)
{int minx=min(a,b);for (int i=p;i<=minx;++i){if (a%i==0 && b%i==0 && vis[i])return true;}return false;
}
int find(int x)
{if (f[x]==x)return x;else {f[x]=find(f[x]);return f[x];}
}
void unionn(int i,int j)
{f[find(f[i])]=find(j);
}
int main()
{cin>>a>>b>>p;int l=max(a,b);is_prime(l);//初始化for (int i=a;i<=b;++i)f[i]=i;for (int i = p; i <= b; ++i) {if (vis[i]) {int firstMultiple = ((a + i - 1) / i) * i; // 第一个大于等于a的i的倍数for (int j = firstMultiple; j <= b; j += i) {unionn(firstMultiple, j);}}}int cnt=0;for (int i=a;i<=b;++i){if (flag[find(i)]==0){flag[find(i)]++;cnt++;}else flag[find(i)]++;}cout<<cnt;
} 修复公路https://www.luogu.com.cn/problem/P1111
题目背景
A 地区在地震过后,连接所有村庄的公路都造成了损坏而无法通车。政府派人修复这些公路。
题目描述
给出 A 地区的村庄数 �N,和公路数 �M,公路是双向的。并告诉你每条公路的连着哪两个村庄,并告诉你什么时候能修完这条公路。问最早什么时候任意两个村庄能够通车,即最早什么时候任意两条村庄都存在至少一条修复完成的道路(可以由多条公路连成一条道路)。
输入格式
第 11 行两个正整数 �,�N,M。
下面 �M 行,每行 33 个正整数 �,�,�x,y,t,告诉你这条公路连着 �,�x,y 两个村庄,在时间t时能修复完成这条公路。
输出格式
如果全部公路修复完毕仍然存在两个村庄无法通车,则输出 −1−1,否则输出最早什么时候任意两个村庄能够通车。
输入输出样例
输入 #1复制
4 4 1 2 6 1 3 4 1 4 5 4 2 3
输出 #1复制
5
说明/提示
1≤�,�≤�≤1031≤x,y≤N≤103,1≤�,�≤1051≤M,t≤105。
思路:用了并查集和结构体排序,把数据按照时间的顺序排,然后一个一个进并查集里面,直到可以连接所有的村庄
#include <bits/stdc++.h>
using namespace std;
struct node{int x;int y;int t;
}p[100005];
int f[100005];
bool cmp(node& a,node& b)
{return a.t<b.t;
}
int find(int x)
{return f[x]==x?x:f[x]=find(f[x]);
}
void unionn(int i,int j)
{f[find(i)]=find(j);
}
int main()
{int n,m;cin>>n>>m;for (int i=1;i<=n;++i)f[i]=i;for (int i=0;i<m;++i){cin>>p[i].x>>p[i].y>>p[i].t;}sort(p,p+m,cmp);int tot=0;for (int i=0;i<m;++i){unionn(p[i].x,p[i].y);tot=p[i].t;int flag=1;for(int j=1;j<=n;++j){if (find(j)!=find(n)){flag=0;break;}}if (flag){cout<<tot;return 0;}}cout<<-1;
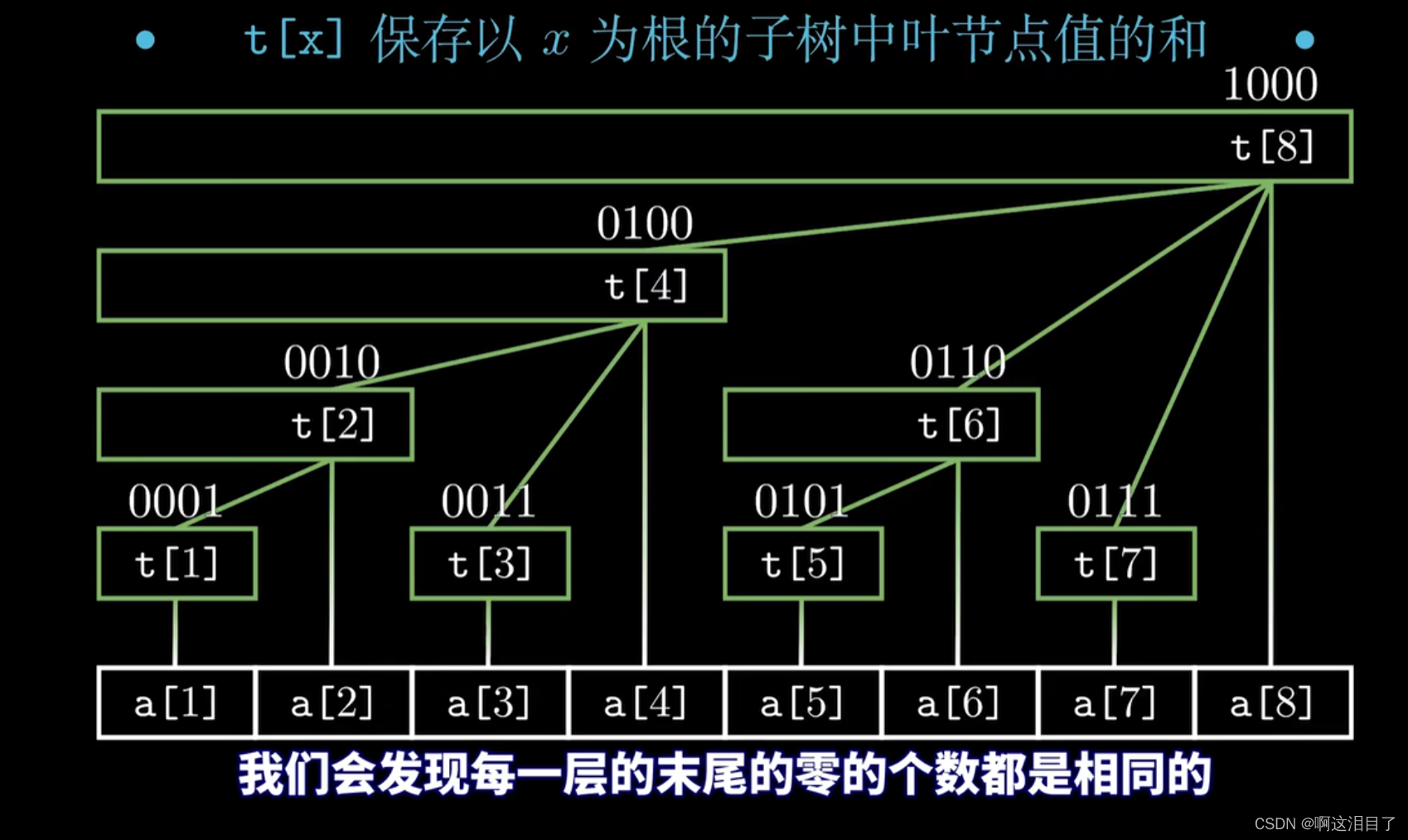
}树状数组
主要解决的是区间查询,单点查询,区间修改,单点修改的问题
相比前缀和而言更加的高效:
在前缀和中查询一个区间和的复杂度是O(1),计算所有前缀和需要n次,所以总共的复杂度是O(n),但是前缀和只能解决静态数组的区间和问题,而树状数组可以解决动态的数组区间和问题,由于是基于的树的思想,所以在创建前缀和时的复杂度是O(nlongn),计算前缀和的复杂度是O(logn),修改一次数据的复杂度也是O(logn),查询一次的复杂度也是O(logn),所以总复杂度是O(nlogn)
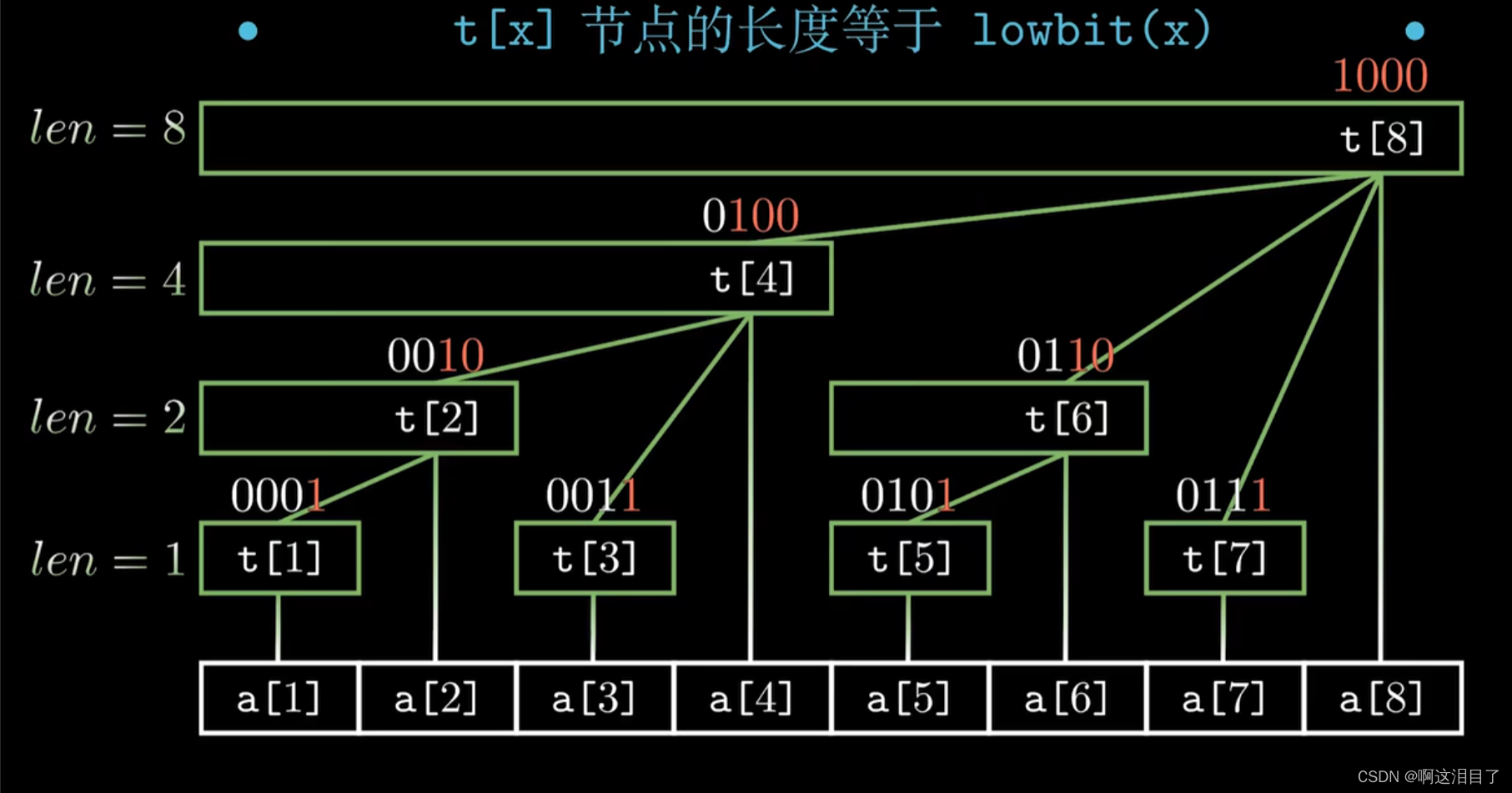
树状数组主要有lowbit(),update(),sum()三个函数组成简短高效
树状数组 1https://www.luogu.com.cn/problem/P3374
题目描述
如题,已知一个数列,你需要进行下面两种操作:
-
将某一个数加上 �x
-
求出某区间每一个数的和
输入格式
第一行包含两个正整数 �,�n,m,分别表示该数列数字的个数和操作的总个数。
第二行包含 �n 个用空格分隔的整数,其中第 �i 个数字表示数列第 �i 项的初始值。
接下来 �m 行每行包含 33 个整数,表示一个操作,具体如下:
-
1 x k含义:将第 �x 个数加上 �k -
2 x y含义:输出区间 [�,�][x,y] 内每个数的和
输出格式
输出包含若干行整数,即为所有操作 22 的结果。
输入输出样例
输入 #1复制
5 5 1 5 4 2 3 1 1 3 2 2 5 1 3 -1 1 4 2 2 1 4
输出 #1复制
14 16
说明/提示
【数据范围】
对于 30%30% 的数据,1≤�≤81≤n≤8,1≤�≤101≤m≤10;
对于 70%70% 的数据,1≤�,�≤1041≤n,m≤104;
对于 100%100% 的数据,1≤�,�≤5×1051≤n,m≤5×105。
思路:是一道典型的单点修改,和区间查询的题
关于单点修改:
每个子节点的修改都需要把它的父节点,和父节点的父节点.....都修改了而子节点和父节点的规律也很好找,父节点就等于子节点x+lowbit(x),树状数组就相当于是前缀和,其中有一个树加了k那么后面的数也需要加k
void update(int x,int k)
{while(x<=n){tree[x]+=k;x+=lowbit(x);//子节点+k,父节点都要+k }
}区间查询:
就相当于在前缀和和里面求L---R,想法就很简单是R的前缀和减去L-1的前缀和
int sum(int x)
{int res=0;while (x>0){res+=tree[x];x-=lowbit(x);//求的是1---x的区间和 }return res;
}以下是AC码
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N=5e5+5;
#define lowbit(x) (x& (-x))
int tree[N],a[N];
int n;
void update(int x,int k)
{while(x<=n){tree[x]+=k;x+=lowbit(x);//子节点+k,父节点都要+k }
}
int sum(int x)
{int res=0;while (x>0){res+=tree[x];x-=lowbit(x);//求的是1---x的区间和 }return res;
}
signed main()
{int q;cin>>n>>q;for (int i=1;i<=n;++i){cin>>a[i];update(i,a[i]);}for (int i=0;i<q;++i){int a,b,c;cin>>a>>b>>c;if (a==1){update(b,c);}else if (a==2){int ans=0;ans=sum(c)-sum(b-1);cout<<ans<<endl;}}
}树状数组 2https://www.luogu.com.cn/problem/P3368
题目描述
如题,已知一个数列,你需要进行下面两种操作:
-
将某区间每一个数加上 �x;
-
求出某一个数的值。
输入格式
第一行包含两个整数 �N、�M,分别表示该数列数字的个数和操作的总个数。
第二行包含 �N 个用空格分隔的整数,其中第 �i 个数字表示数列第 �i 项的初始值。
接下来 �M 行每行包含 22 或 44个整数,表示一个操作,具体如下:
操作 11: 格式:1 x y k 含义:将区间 [�,�][x,y] 内每个数加上 �k;
操作 22: 格式:2 x 含义:输出第 �x 个数的值。
输出格式
输出包含若干行整数,即为所有操作 22 的结果。
输入输出样例
输入 #1复制
5 5 1 5 4 2 3 1 2 4 2 2 3 1 1 5 -1 1 3 5 7 2 4
输出 #1复制
6 10
思路:这道题是典型的区间修改,和单点搜索
那么可以利用差分数组的性质,引入一个差分数组,在树状数组里面放差分数组的元素,那么树状数组就相当于存了原数组
初始化:
for (int i=1;i<=n;++i){cin>>a[i];d[i]=a[i]-a[i-1];update(i,d[i]);//放的是差分数组的值,这样树状数组保存的就是差分数组的前缀和 }如果要进行区间L---R修改,那就相当于在差分数组L处+c,在R+1处-c,然后更新数组,单点查询就是对差分数组求前缀和
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N=5e5+5;
#define lowbit(x) (x& (-x))
int tree[N],a[N],d[N];
int n,q;
void update(int x,int k)
{while (x<=n){tree[x]+=k;x+=lowbit(x);}
}
int sum(int x)
{int res=0;while (x>0){res+=tree[x];x-=lowbit(x);}return res;
}
signed main()
{cin>>n>>q;for (int i=1;i<=n;++i){cin>>a[i];d[i]=a[i]-a[i-1];update(i,d[i]);//放的是差分数组的值,这样树状数组保存的就是差分数组的前缀和 }for (int i=0;i<q;++i){int op;cin>>op;if (op==1){int a,b,c;cin>>a>>b>>c;update(a,c);update(b+1,-c);}if (op==2){int a;cin>>a;int res=sum(a);cout<<res<<endl;}}}搜索:BFS
机器人搬重物https://www.luogu.com.cn/problem/P1126
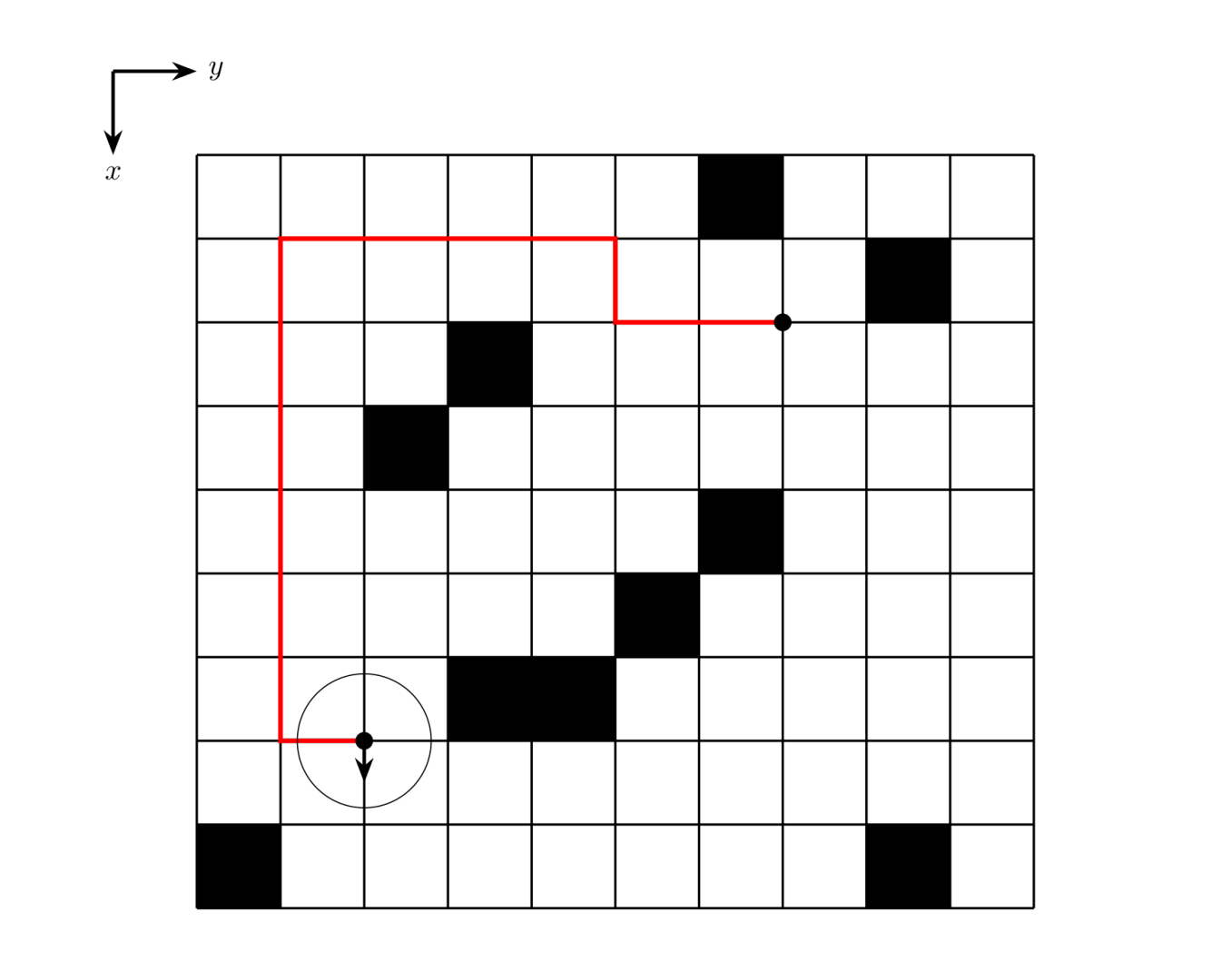
题目描述
机器人移动学会(RMI)现在正尝试用机器人搬运物品。机器人的形状是一个直径 1.61.6 米的球。在试验阶段,机器人被用于在一个储藏室中搬运货物。储藏室是一个 �×�N×M 的网格,有些格子为不可移动的障碍。机器人的中心总是在格点上,当然,机器人必须在最短的时间内把物品搬运到指定的地方。机器人接受的指令有:
- 向前移动 11 步(
Creep); - 向前移动 22 步(
Walk); - 向前移动 33 步(
Run); - 向左转(
Left); - 向右转(
Right)。
每个指令所需要的时间为 11 秒。请你计算一下机器人完成任务所需的最少时间。
输入格式
第一行为两个正整数 �,� (1≤�,�≤50)N,M (1≤N,M≤50),下面 �N 行是储藏室的构造,00 表示无障碍,11 表示有障碍,数字之间用一个空格隔开。接着一行有 44 个整数和 11 个大写字母,分别为起始点和目标点左上角网格的行与列,起始时的面对方向(东 �E,南 �S,西 �W,北 �N),数与数,数与字母之间均用一个空格隔开。终点的面向方向是任意的。
输出格式
一个整数,表示机器人完成任务所需的最少时间。如果无法到达,输出 −1−1。
输入输出样例
输入 #1复制
9 10 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 7 2 2 7 S
输出 #1复制
12
思路:这道题细节很多,由于我们在坐标系中是一个点,然而他的障碍物是一个格子,所以这是一个易错点,我们需要排除,其次我们的指令是可以一步,两步,三步,换方向,所以我们的标记数组需要时三维的,最后需要记录当前的方向,其次在搜索的时候,我们不能把标记数组和越界放在一起,如果越界或者遇到障碍物,那就可以直接退出,因为后面的路也走不了,如果是走过的还可以继续扩展
#include <bits/stdc++.h>
using namespace std;struct node {int x, y, d, t;
};int check(char c) {if (c == 'S') return 1;else if (c == 'N') return 3;else if (c == 'E') return 0;else if (c == 'W') return 2;
}int dx[] = {0, 1, 0, -1};
int dy[] = {1, 0, -1, 0};
queue<node> q;
int a[55][55], vis[55][55][4];
int main() {int m, n;cin >> m >> n;for (int i = 1; i <= m; ++i) {for (int j = 1; j <= n; ++j){int b;cin>>b;if (b) {a[i][j] = 1;a[i-1][j-1]=1;a[i-1][j]=1;a[i][j-1]=1;}}}int ex, ey, sx, sy;char fd;cin >> sx >> sy >> ex >> ey >> fd;if (ex == sx && ey == sy) {cout << 0;return 0;}int op = check(fd);q.push(node{sx, sy, op, 0});vis[sx][sy][op] = 1;while (!q.empty()) {node news = q.front();q.pop();if (news.x == ex && news.y == ey) {cout << news.t;return 0;}int x = news.x, y = news.y, t = news.t, d = news.d;for (int i = 1; i <= 3; ++i) {int tx = x + i * dx[d], ty = y + i * dy[d];if (tx<1 || ty<1 || tx>=m || ty>=n ||a[tx][ty]==1)break;if (vis[tx][ty][d]) continue;q.push(node{tx, ty, d, t + 1});vis[tx][ty][d] = 1;}for (int i = -1; i <= 1; i += 2) {op = (d + 4 + i) % 4;if (!vis[x][y][op]){q.push(node{x, y, op, t + 1});vis[x][y][op] = 1;}}}cout << -1;return 0;
}
这篇关于1.29学习总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







