本文主要是介绍uniCloud ---- JQL语法 连表查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
JQL数据库操作
JQL流程图解
JQL的限制
单表查询
联表查询
新增
修改
删除
联表查询
例子
字段过滤field
字段别名as
限制查询记录的条数limit
只查一条记录getone
JQL数据库操作
JQL,全称 javascript query language,是一种js方式操作数据库的规范。
JQL大幅降低了js工程师操作数据库的难度,比SQL和传统MongoDB API更清晰、易掌握。JQL支持强大的DB Schema,内置数据规则和权限。DB Schema 支持uni-id,可直接使用其角色和权限。无需再开发各种数据合法性校验和鉴权代码。JQL利用json数据库的嵌套特点,极大的简化了联表查询和树查询的复杂度,并支持更加灵活的虚拟表。
const db = uniCloud.database()// 使用`jql`查询list表内`name`字段值为`hello-uni-app`的记录
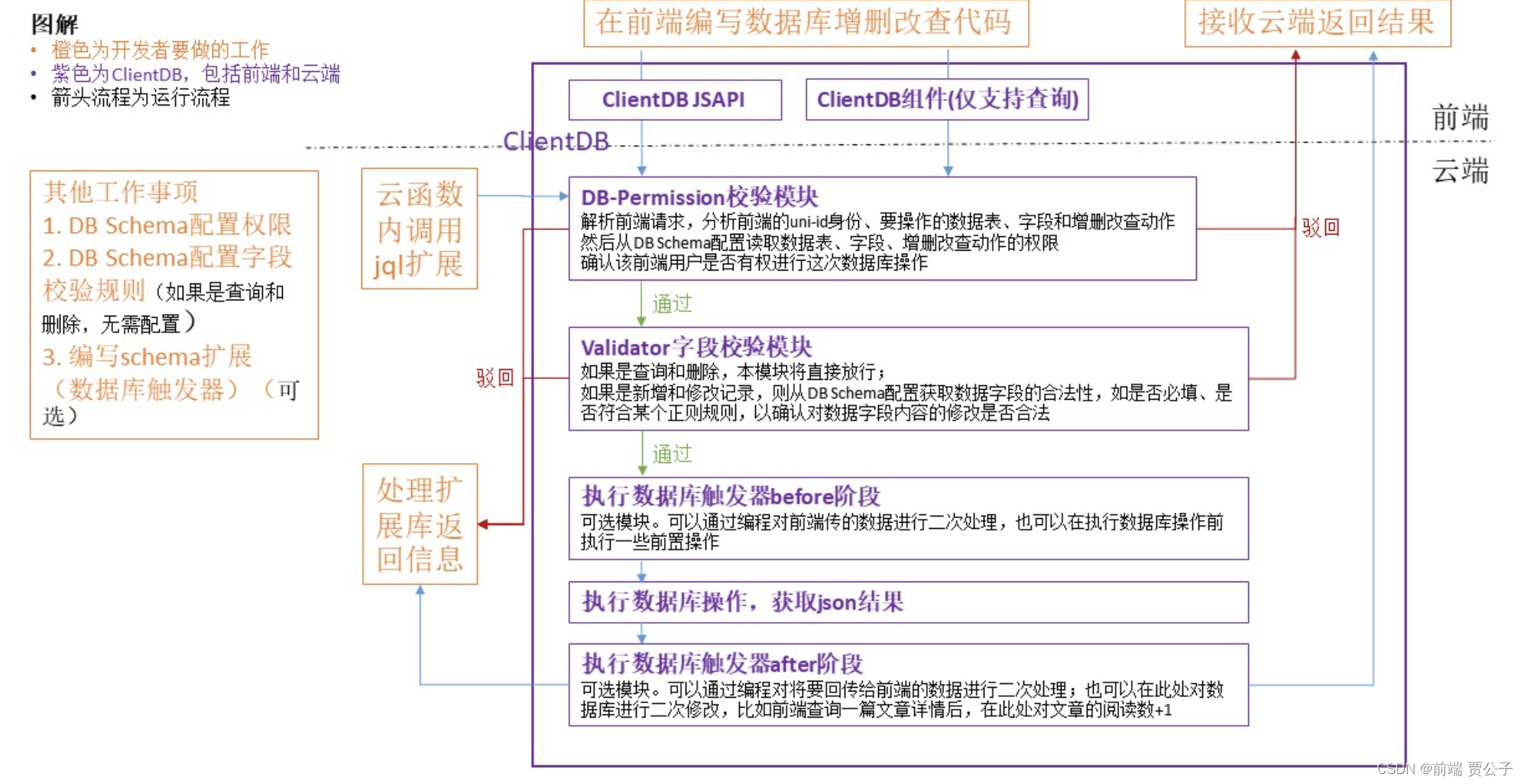
db.collection('list').where('name == "hello-uni-app"').get().then((res)=>{// res 为数据库查询结果}).catch((err)=>{// err.message 错误信息// err.code 错误码})JQL流程图解
下图包括clientDB及云函数内使用jql扩展库的调用流程
前端编写数据库增删改查代码接收云端返回结果橙色为开发者要做的工作紫色为clientDB,包括前端和云端箭头流程为运行流程ClientDBJSAPIClientDB组件(仅支持查询)前端ClientDB云端其他工作事项云函数DB-Permission校验模块
1.DBSchema配置权限解析前端请求,分析前端的uni-id身份、要操作的数据表、字段和增删改查动作内调用驳回然后从DBSchema配置读取数据表、字段、增删改查动作的权限
2.DBSchema配置字段jql扩展确认该前端用户是否有权进行这次数据库操作校验规则(如果是查询和通过删除,无需配置)Validator字段校验模块
3.编写schema扩展驳回如果是查询和删除,本模块将直接放行;(数据库触发器)(可如果是新增和修改记录,则从DBSchema配置获取数据字段的合法性,如是否必填、是选)否符合某个正则规则,以确认对数据字段内容的修改是否合法通过处理扩执行数据库触发器before阶段展库返可选模块。
可以通过编程对前端传的数据进行二次处理,也可以在执行数据库操作前执行一些前置操作回信息执行数据库操作,获取json结果执行数据库触发器after阶段可选模块。可以通过编程对将要回传给前端的数据进行二次处理;也可以在此处对数据库进行二次修改,比如前端查询一篇文章详情后,在此处对文章的阅读数+1
JQL的限制
- 会对数据库操作进行序列化,除Date类型、RegExp之外的所有不可JSON序列化的参数类型均不支持(例如:undefined)
- 为了严格控制权限,禁止使用set方法
- 为了数据校验能严格限制,更新数据库时不可使用更新操作符
db.command.inc等 - 更新数据时键值不可使用
{'a.b.c': 1}的形式,需要写成{a:{b:{c:1}}}形式
单表查询
下面这些方法必须严格按照下面的顺序进行调用,其他方法需要在这些方法之后调用(不限制顺序)
collection
aggregate
geoNear // 新增于 HBuilderX 3.6.10
doc
where
field
groupBy
groupField
联表查询
临时表可以使用以下方法(需按照下面的顺序调用)
collection
geoNear // 新增于 HBuilderX 3.6.10
where
field
orderBy
skip
limit
getTemp
虚拟联表可以使用以下方法(需按照下面的顺序调用)
collection
foreignKey
where
field
groupBy
groupField
distinct
orderBy
skip
limit
get
新增
仅允许collection().add()这样的形式
修改
仅允许以下两种形式
db.collection('xx').doc('xxx').update({})
db.collection('xx').where('xxxx').update({})
删除
仅允许以下两种形式
db.collection('xx').doc('xxx').remove()
db.collection('xx').where('xxxx').remove()
联表查询
为方便文档描述定义以下两个概念:
- 临时表:getTemp方法返回的结果,例:
const article = db.collection('article').getTemp(),此处 article 就是一个临时表 - 虚拟联表:主表与副表联表产生的表,例:
db.collection(article, 'comment').get()
JQL于2021年4月28日优化了联表查询策略,详情参考:联表查询策略调整
JQL提供了更简单的联表查询方案。不需要学习join、lookup等复杂方法。
只需在db schema中,将两个表的关联字段建立映射关系,就可以把2个表当做一个虚拟联表来直接查询。
JQL联表查询有以下两种写法:
// 直接关联多个表为虚拟联表再进行查询,旧写法,目前更推荐使用getTemp进行联表查询
const res = await db.collection('order,book').where('_id=="1"').get() // 直接关联order和book之后再过滤// 使用getTemp先过滤处理获取临时表再联表查询,推荐用法
const order = db.collection('order').where('_id=="1"').getTemp() // 注意结尾的方法是getTemp,对order表过滤得到临时表
const res = await db.collection(order, 'book').get() // 将获取的order表的临时表和book表进行联表查询
上面两种写法最终结果一致,但是第二种写法性能更好。第一种写法会先将所有数据进行关联,如果数据量很大这一步会消耗很多时间。详细示例见下方说明
关联查询后的返回结果数据结构如下:
通过HBuilderX提供的JQL数据库管理功能方便的查看联表查询时返回数据的结构
主表某字段foreignKey指向副表时
{"主表字段名1": "xxx","主表字段名2": "xxx","主表内foreignKey指向副表的字段名": [{"副表字段名1": "xxx","副表字段名2": "xxx",}]
}副表某字段foreignKey指向主表时
{"主表字段名1": "xxx","主表字段名2": "xxx","主表内被副表foreignKey指向的字段名": {"副表1表名": [{ // 一个主表字段可能对应多个副表字段的foreignKey"副表1字段名1": "xxx","副表1字段名2": "xxx",}],"副表2表名": [{ // 一个主表字段可能对应多个副表字段的foreignKey"副表2字段名1": "xxx","副表2字段名2": "xxx",}],"_value": "主表字段原始值" // 使用副表foreignKey查询时会在关联的主表字段内以_value存储该字段的原始值,新增于HBuilderX 3.1.16}
}
例子
比如有以下两个表,book表,存放书籍商品;order表存放书籍销售订单记录。
book表内有以下数据,title为书名、author为作者:(副表)
{"_id": "1","title": "西游记","author": "吴承恩"
}
{"_id": "2","title": "水浒传","author": "施耐庵"
}
{"_id": "3","title": "三国演义","author": "罗贯中"
}
{"_id": "4","title": "红楼梦","author": "曹雪芹"
}
order表内有以下数据,book_id字段为book表的书籍_id,quantity为该订单销售了多少本书:(主表)
{"book_id": "1","quantity": 111
}
{"book_id": "2","quantity": 222
}
{"book_id": "3","quantity": 333
}
{"book_id": "4","quantity": 444
}
{"book_id": "3","quantity": 555
}
如果我们要对这2个表联表查询,在订单记录中同时显示书籍名称和作者,那么首先要建立两个表中关联字段book的映射关系。
即,在order表的db schema中,配置字段 book_id 的foreignKey,指向 book 表的 _id 字段,如下
// order表schema
{"bsonType": "object","required": [],"permission": {"read": true},"properties": {"book_id": {"bsonType": "string","foreignKey": "book._id" // 使用foreignKey表示,此字段关联book表的_id。},"quantity": {"bsonType": "int"}}
}
book表的DB Schema也要保持正确
// book表schema
{"bsonType": "object","required": [],"permission": {"read": true},"properties": {"title": {"bsonType": "string"},"author": {"bsonType": "string"}}
}
schema保存后,即使用JQL查询。查询表设为order和book这2个表名后,即可自动按照一个合并虚拟联表来查询,field、where等设置均按合并虚拟联表来设置。
// 客户端联表查询
const db = uniCloud.database()
const order = db.collection('order').field('book_id,quantity').getTemp() // 临时表field方法内需要包含关联字段,否则无法建立关联关系
const book = db.collection('book').field('_id,title,author').getTemp() // 临时表field方法内需要包含关联字段,否则无法建立关联关系
db.collection(order, book) // 注意collection方法内需要传入所有用到的表名,用逗号分隔,主表需要放在第一位.where('book_id.title == "三国演义"') // 查询order表内书名为“三国演义”的订单.get().then(res => {console.log(res);}).catch(err => {console.error(err)})
字段过滤field
一定要加上关联的id
查询时可以使用field方法指定返回字段。不使用field方法时会返回所有字段
field可以指定字符串,也可以指定一个对象。
field中可以使用所有数据库运算方法
- 字符串写法:列出字段名称,多个字段以半角逗号做分隔符。比如
db.collection('book').field("title,author"),查询结果会返回_id、title、author3个字段的数据。字符串写法,_id是一定会返回的
复杂嵌套json数据过滤
如果数据库里的数据结构是嵌套json,比如book表有个价格字段,包括普通价格和vip用户价格,数据如下:
{"_id": "1","title": "西游记","author": "吴承恩","price":{"normal":10,"vip":8}
}
那么使用db.collection('book').field("price.vip").get(),就可以只返回vip价格,而不返回普通价格。查询结果如下:
{"_id": "1","price":{"vip":8}
}
对于联表查询,副表的数据嵌入到了主表的关联字段下面,此时在filed里通过{}来定义副表字段。比如之前联表查询章节举过的例子,book表和order表联表查询:
// 联表查询
db.collection('order,book') // 注意collection方法内需要传入所有用到的表名,用逗号分隔,主表需要放在第一位.field('book_id{title,author},quantity') // 这里联表查询book表返回book表内的title、book表内的author、order表内的quantity.get()
不使用{}过滤副表字段
此写法于2021年4月28日起支持
field方法内可以不使用{}进行副表字段过滤,以上面示例为例可以写为
const db = uniCloud.database()
db.collection('order,book').where('book_id.title == "三国演义"').field('book_id.title,book_id.author,quantity as order_quantity') // book_id.title、book_id.author为副表字段,使用别名时效果和上一个示例不同,请见下方说明.orderBy('order_quantity desc') // 按照order_quantity降序排列.get().then(res => {console.log(res);}).catch(err => {console.error(err)})
字段别名as
自2020-11-20起JQL支持字段别名,主要用于在前端需要的字段名和数据库字段名称不一致的情况下对字段进行重命名。
用法形如:author as book_author,意思是将数据库的author字段重命名为book_author。
仍以上面的order表和book表为例
// 客户端联表查询
const db = uniCloud.database()
db.collection('book').where('title == "三国演义"').field('title as book_title,author as book_author').get().then(res => {console.log(res);}).catch(err => {console.error(err)})
上述查询返回结果如下
{"code": "","message": "","data": [{"_id": "3","book_author": "罗贯中","book_title": "三国演义"}]
}
_id是比较特殊的字段,如果对_id设置别名会同时返回_id和设置的别名字段
注意
- as后面的别名,不可以和表schema中已经存在的字段重名
- mongoDB查询指令中,上一阶段处理完毕将结果输出到下一阶段。在上面的例子中表现为where中使用的是原名,orderBy中使用的是别名
- 目前不支持对联表查询的关联字段使用别名,即上述示例中的book_id不可设置别名
限制查询记录的条数limit
使用limit方法,可以查询有限条数的数据记录。
比如查询销量top10的书籍,或者查价格最高的一本书。
// 这以上面的book表数据为例,查价格最高的一本书db.collection('book').orderBy('price desc').limit(1).get()
、
limit默认值是100,即不设置的情况下,默认返回100条数据。limit最大值为1000。
一般情况下不应该给前端一次性返回过多数据,数据库查询也慢、网络返回也慢。可以通过分页的方式分批返回数据。
在查询的result里,有一个affectedDocs。但affectedDocs和limit略有区别。affectedDocs小于等于limit。
比如book表里只有2本书,limit虽然设了10,但查询结果只能返回2条记录,affectedDocs为2。
只查一条记录getone
使用JQL的API方式时,可以在get方法内传入参数getOne:true来返回一条数据。
getOne其实等价于上一节的limit(1)。
一般getOne和orderBy搭配。
// 这以上面的book表数据为例
const db = uniCloud.database()db.collection('book').where({title: '西游记'}).get({getOne:true}).then(res => {console.log(res);}).catch(err => {console.error(err)})
返回结果为
{"code": "","message": "","data": {"_id": "1","title": "西游记","author": "吴承恩"}
}
这篇关于uniCloud ---- JQL语法 连表查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




