本文主要是介绍Nanopore宏基因组分析永久冻土融化过程中微生物群落,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


Devin Drown和他在美国阿拉斯加大学费尔班克斯分校(University of Alaska Fairbanks)的团队一直在利用OxfordNanopore纳米孔技术带来的长读长测序的优势,致力于研究永久冻土的融化对土壤微生物群落造成的影响1。永久冻土是土壤、砾石和沙子的永久冻结层,位于地球表面或地表以下。
永久冻土指的是至少连续冻结两年的地区,而大多数的永久冻土已经冻结了数百甚至数千年。在地球上高纬度或高海拔的寒冷气候地区,永久冻土覆盖着大片区域。永久冻土的上层是一层薄薄的土壤,称为活动层。Devin和他的团队想了解由气候变化引起的永久冻土融化会如何影响活动层中的微生物群落,继而又会如何影响土壤中生长的作物。微生物和植物之间的相互作用对养分的获取和循环至关重要,即使是土壤微生物群落的微小变化也会扰乱植物-微生物的相互作用2。
“为应对气候变化,土壤微生物具有改变植物的生长的能力”1
该研究团队位于阿拉斯加,团队应用纳米孔宏基因组测序,研究了北方森林(也称为雪林)不同冻土环境土壤中发现的微生物群落。这些森林是阿拉斯加土著居民饮食中不可或缺的多种植物的家园。用宏基因组学测序意味着无需培养微生物。Devin和他的团队选择了纳米孔技术,快速全面地对活动层中复杂的微生物群落进行了表征。无需PCR扩增的长纳米孔测序读长能够检测传统短读长测序技术难以测序的区域,有助于从复杂的微生物群落中组装出精确的微生物基因组。可以对原始DNA进行实时测序,以便于精简制库流程并加快周转时间。
在60多年前建造的阿拉斯加费尔班克斯永久冻土实验站(FPES),该团队通过人工诱导永久冻土融化,用在北方森林发现的五种植物物种:越桔(Vaccinium vitis-idaea)、笃斯越桔(Vaccinium uliginosum)、黑云杉(Picea mariana)、加茶杜香(Ledum groenlandicum)和柳兰(Chamerion angustifolium)开展了植物生长实验。这些植物所生长的土壤是融化程度不同的永久冻土,被称为“未扰动”、“半扰动”和“扰动最大”(图1)。
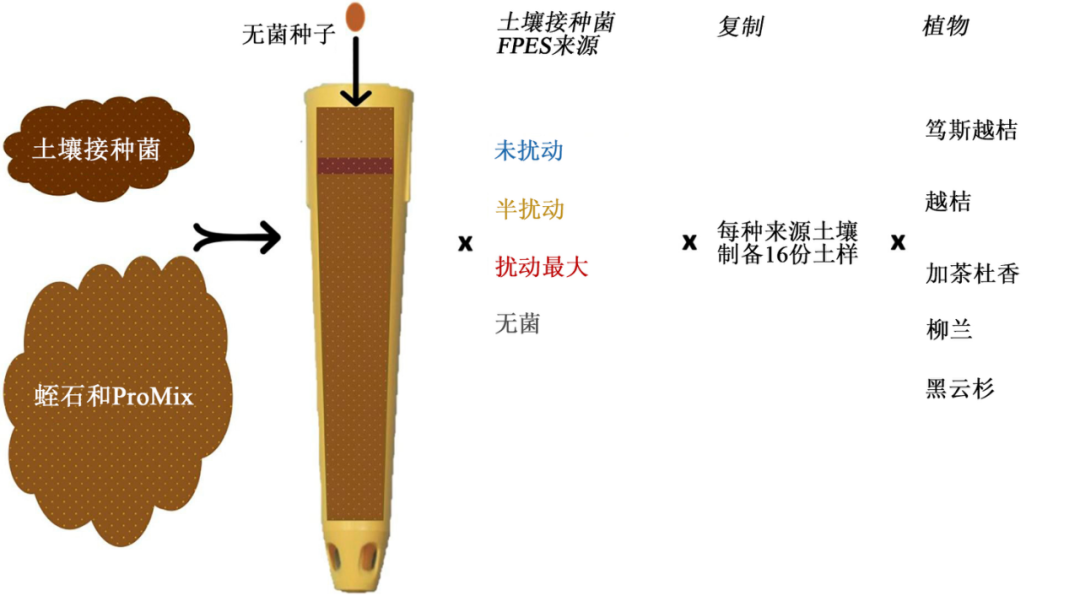
图1:植物生长实验设计。图片来自Seitz等人1,可在知识共享许可协议(creativecommons.org/licenses/by/4.0)许可的情况下使用。
与接种永久冻土中未扰动活动层微生物群落相比,接种融化活动层微生物群落的大部分植物繁殖能力下降。为了分析不同活动层中的微生物群落,研究团队使用测序连接试剂盒对四张MinION测序芯片上的48个宏基因组进行测序。组合数据集的平均测序读长为2594 bp,读长N50为5531 bp。再通过Kraken3和Bracken4分析读长,分别检测分类群和估算丰度。团队在微生物群落中共识别了24种细菌类群。可视化数据显示,不同类型土壤的微生物群落种群存在差异,其中在未扰动活动层和扰动最大活动层之间观察到的差异最大。
我们已经知道,有益的土壤微生物可以提高植物的养分利用率,促进植物的生长并提高繁殖能力2。通过分析影响植物健康生长的生物标志物,研究团队发现与扰动最大土壤样本相比,促进植物繁殖能力的微生物,如酸杆菌科(Acidobacteriaceae)和芽孢杆菌目(Bacillales),在未扰动土壤样本中占比更高。然而,与未扰动的土壤相比,对多种植物具有致病作用的丛毛单胞菌科(Comamonadaceae)在扰动最大土壤中的丰度更高(图2)。研究小组假设,在扰动最大土壤中发现的已知植物病原体扰乱了养分的循环,直接改变了植物根围(围绕植物根系的区域),从而导致植物生长减少。
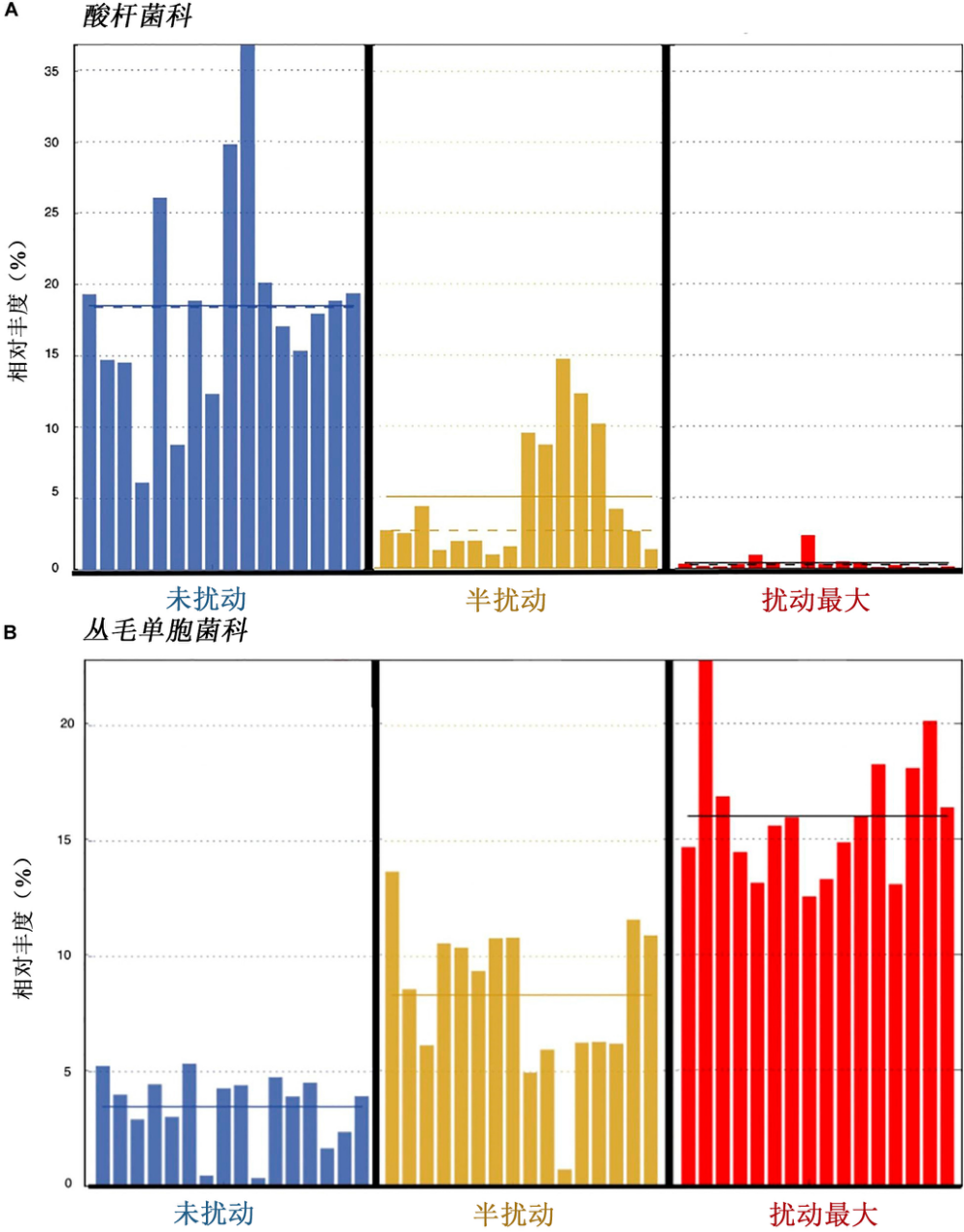
图2:不同类型土壤中不同科细菌的相对丰度。实线代表平均相对丰度。图片来自Seitz等人1,可在知识共享许可协议(creativecommons.org/licenses/by/4.0)许可的情况下使用。
这项环境宏基因组学研究正式确定了气候变化、永久冻土融化、微生物群落变化、植物健康和更广泛的细菌群落健康2之间的联系。
“我们的研究结果表明,植物生长的减少可能与微生物群落分类构成的变化有关”1
本案例研究摘自微生物学白皮书。下载白皮书,了解更多案例研究以及研究人员如何使用纳米孔测序更好地了解微生物基因组和群落的详细信息。
扫描下方二维码
下载纳米孔测序植物研究:

1. Seitz, T.J. et al. Frontiers in Microbiology 12:619711 (2022).
2. Devin Drown. https://nanoporetech.com/resource-centre/video/lc21/evaluating-the-effects-of-the-changing-permafrost-ecosystem-through-the-lens-of-genomics [Accessed 24 August 2022]
3. Wood, D.E., Lu, J. & Langmead, B. Genome Biol. 20:257 (2019).
4. Lu, J. et al. PeerJ Comp. Sci. 3:e104 (2017).

相关阅读
以不变应万变:开发一个可以对任何病原体进行表征的简单工作流程
保护项目ORG.one成功完成50种极危物种的基因组测序试点工作
【2月23-24日】OxfordNanopore与您相约#A6展位@第六届国际肿瘤精准医疗大会(P4-China)
Oxford Nanopore与UPS Healthcare合作,加速向亚太地区的更多客户交付新一代DNA测序技术
这篇关于Nanopore宏基因组分析永久冻土融化过程中微生物群落的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







