本文主要是介绍Domino NSD日志诊断/分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着Domino服务器在生产环境中的长时间运行,用户量增多,数据量增大后,会带来一系列的问题;如宕机频繁、运行效率低下、系统资源消耗大等现象。本身Domino属于文档型数据库,在数据库中的文档数量越多,数据库越大;访问效率就会越低。大多数项目初期:
程序员为了完成任务或赶工,编写过程中并不会考虑程序运行效率、容错等问题;
在布署运行环境的时候,一般不会全面考虑服务器的运行状况,不会对服务器进行相应的性能优化和调整;所以在数据量增大和用户数增大时,出现性能低下等问题。
基于以上现象,客户满意度达不到,有可能造成项目失败的可能性。
遇到这类情况后,Domino管理员就有必要通过一系列手段来评估目前环境的问题在哪?性能瓶颈在哪?主要什么原因引起的?应该如何进行调整?
在我眼中Domino管理员工作是非常复杂和繁锁的,Domino管理工作可以细分从服务器管理、数据库管理、邮件管理、人员管理、安全管理、复制管理、策略管理等,这些工作你可以一人完成(这个人要相当牛B了,对Domino运行机制,邮件路由机制,复制机制,Internet协议等都要有比较深层次的了解),也可以一个小组来完成。
如果做为一个合格Domino管理员,不懂得如何编写程序,可以说根本算不上一个真正的系统管理员。就像二流黑客拿一些专门的黑客工具黑网站,黑QQ号一样,只知道机械化的做,并不知道为什么要这么做,基础原理是什么。
当你的Domino服务器宕机后,向IBM800电话支持,他们都会要求你提供NSD日志给他们进行分析,经他们分析后,会告诉你宕机原因,是由什么由于引起宕机。
言归正传,我们先讲讲如何分析NSD日志,并从中找出服务器目前的问题所在,宕机目要是由什么引起的。
NSD日志存放于%DominoData%/IBM_TECHNICAL_SUPPORT目录下,文件格式:
nsd_ _ _<日志生成日志(YYYY_MM_DD)>@<日志生成时间(HH_MM_SS)>.log
例:
- nsd_all_AIX_as2_2008_04_03@17_32_40.log
- nsd_W32I_as5_2008_07_18@11_07_24.log
以文件名能很快清楚服务器的基本信息。
NSD分析工具有两种(目前我所知道的,也许还有其他的)Laza和Lotus Notes Diagnostic(简称:LND)两种,大致功能是相同的,Laza因为有SPR库和PMR库支持,可以快速的找出服务器宕机的解释和解决办法,但是SPR库和PMR库,IBM是不对外开放;所以我们使用的话Laza或LND是没区别的。我推荐大家使用LND足够了,简单方便,配合Google查询足够完成NSD分析工作。
如何分析?很简单,安装完LND后,启动Lotus Notes客户端,打开LND库(LND缺省会将lnd.nsf安装在你%NotesData%/LND目录下),如下图:
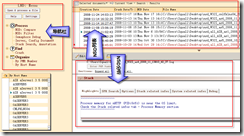
单击"Open & Process a file",打开一个NSD文件,则会将一个NSD进行分析,并将结果保存在Notes文档中。NSD分析结果文档分为以下部分:
- Stack:记录引起宕机的主要Stack片断信息
- HighLights:主要强调的错误信息,包括出错任务名称、进程号或内存地址等
- SPR Search:SPR查询关键字,使用这些关键字,在IBM Support网站上能查询相关信息;(这个是最有效的解决办法之一)
- Options:设置信息,可以不管
- Stack related infos:记录详细的Stack信息,分为以下几个部分,其中观察红色加粗部分就可以定位宕机主要原因以及所由哪个用户在使用哪个数据库中哪个文档(文档中调用了哪段程序)所引起的:
- open database(s) by the process:进程打开的数据库
- Possible file name(s) in stack frames:可能涉及到的数据库文件名
- Process Associated Collection(s)&View(s):进程所涉及到的集合和视图
- Process Handle Table Info:进程所涉及到的Handle Table信息
- Process Memory:进程使用内存情况
- Process Memory Mapping:进程使用内存地址映射表
- Process Top 10 Memory block usage:进程中前10个内存块使用情况
- Shared OS Fields:共享OS区(此处记录了宕机的主要原因)
- Stack frames Dump:Stack结构回收信息
- Virtual Thread(s):所涉及的虚拟线程(此处记录了宕机时所涉及到的数据库、文档以及Domino设计元素)
- System related infos:系统相关信息,如果你对服务器的软/硬件环境非常了解,可不关注此部分,
- Debug:调试方法,当出现宕机后,可以使用这里提供的方法对Domino服务器进行调试。如果前面的Stack related infos定位不到宕机的真正原因,才使用这里面介绍的方法进行调试;不过大部分错误能在Stack related infos找得到,并配合IBM Support网站或官方论坛找到相应的解决办法。
NSD分析思路
1.通过LND解析NSD后,首先查看Stack信息,如下图:
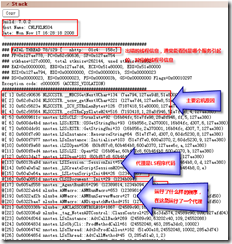
2.从上图不难看出主上宕机原因,然后在SPR Search标签中可得到相关的查询关键字,如下图:
![]()
通过这些关键字,你能在IBM Support网站上或官方论坛上找到相关的信息或解决方案。找到这些答案基本上分析工作就完成了。根椐IBM Support网站上提供的解决方案,对服务器做出相应的调整即可解决宕机问题。但如果SPR Search标签中并未提供查询关键字(有些NSD并未提供这些,这说明并不是Domino本身BUG所引起的,是由于你写的程序引起了宕机),所以我们得进一步分析是哪个数据库中哪段程序引起这个原因的,HEHE。
3.打开Stack Related Infos标签,展开Shared OS Fields区段,如下图:

从上图我们可以看出宕机的原因和引起宕机的服务和相关线程。在某些宕机情况下FaultRecovery中会记录明显的错误,而不是内存地址信息;如:PANIC:XXXXXXXX等,你可以以此为关键字去IBM Support网站上查询相关信息,帮助你分析宕机原因,也可以直接得到答案。^_*
4.从上面示例中,我们得到了引起宕机的线程号,展开Virtual Thread(s)区段,通过比较相关线程号,就能定位到是由哪个数据库中哪个设计元素引起的宕机。如下图:
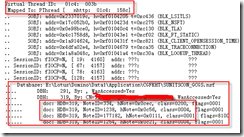
通过相关线程号与VThread ID的对应,我们找到了是由哪个用户操作哪个数据库引起的宕机。其中也记录了用户操作的文档所引起的宕机。其中NoteID为Domino数据库元素(名括设计元素和文档)标识,Class为元素类别。元素类别如下:
| Note Class | 描述 |
| 0x0001 | 文档 |
| 0x0004 | 表单 |
| 0x0008 | 视图 |
| 0x0040 | ACL |
| 0x0200 | 代理 |
| 0x0800 | 公式 |
5.得到NoteID后,如何定位至元素呢?NSD中NoteID是以10进制方式表示的,如果要在Domino环境中查找相应的元素时,先将NoteID转成16进制再进行查询。
打开Domino Administrator,在“File”标签中选中相应的数据库,在右边工具栏选“Find Note”,输入NoteID,即可找到相应的元素,如下图:
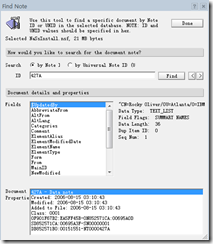
通过以上方法对NSD分析,能快速有效的找到服务器宕机的真正原因在哪,并有针对性的提出解决方案;也能找到是由于哪段程序引起了Domino服务器宕机,为什么会引起宕机,可快速的修正代码错误。
以上方法主要通过LND工具进行分析。LND工具并不能100%从NSD中找到问题所在,这时你就得使用LND工具分析+手工分析方式。手工分析方法请参考Hands On NSD。Hands on NSD介绍了NSD文件的组成,分析方法,步骤等。
从项目角度上来说,造成大部分宕机的原因80%以上都是程序代码所造成的。所以开发人员在实施项目或开发产品时应该充分关注自己编写代码的质量,容错,性能,扩展等问题,不要为了完成任务而不注重质量。如果只是为了完成任务,客户满意度达不到,项目不能验收,将来返工,同样也耗费了大量的时间,也给以后的维护人员带来了很大的维护工作量,更重要的是不利于产品构架的扩展和性能高的应用。这年头客户不是傻子,好不好用人家说了算,验不验收人家说了算,不要涂一时快活给整个团队带来麻烦。
现在大家都会说,规范能说出一整套一整套的,但真正做到的没几个。从点滴做起,从自己做起,规范自己就是提高自己。
这篇关于Domino NSD日志诊断/分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






