本文主要是介绍基于Python的微博热点李佳琦忒网友话题的评论采集和情感分析的方法,利用情感分析技术对评论进行情感倾向性判断,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 引言
介绍了基于Python的微博热点李佳琦忒网友话题的评论采集和情感分析的方法。首先,使用Python编写程序实现微博评论的采集,通过API或爬虫方式获取相关话题下的评论数据。然后,对采集到的评论数据进行预处理,包括分词、去除停用词等操作,以准备进行情感分析。
接下来,利用情感分析技术对评论进行情感倾向性判断。可以使用自然语言处理库(如cnsenti)进行情感分析。情感分析的结果可以将评论划分为积极、消极或中立的类别,或者给出情感得分。这样可以更好地了解网友对于李佳琦的看法和态度。
最后,根据情感分析的结果,可以进一步进行统计分析和可视化呈现。可以统计不同情感类别的评论数量,并生成折线图等可视化图表,以直观展示网友对李佳琦的情感态度。
通过以上方法,可以系统地收集和分析微博热点李佳琦的话题下的评论,并从情感的角度了解网友的观点和情感倾向。这对于了解公众的反馈和情感态度,以及品牌或个人形象的管理都具有重要的参考价值。
基于Python的微博热点李佳琦忒网友话题的评论采集和情感分析具有重要意义。首先,这种方法可以帮助了解公众对李佳琦的态度和看法,包括积极、消极或中立的情感倾向。这对于品牌或个人形象管理非常重要,可以及时了解公众的反馈和情感态度,为决策提供参考。
其次,通过评论的采集和情感分析,可以发现用户需求和关注点,从而改进产品或服务。根据分析结果,可以识别出用户的喜好、痛点和期望,为品牌或个人提供改进和创新的方向。
此外,微博热点评论采集和情感分析还可以用于舆情监测和危机管理。通过实时收集和分析评论,可以快速掌握公众对于李佳琦事件的态度和情感动向,及时回应和应对负面信息,避免危机的进一步扩大。
最后,基于Python的评论采集和情感分析技术具备高效、灵活和可定制的优势。使用Python编程语言,可以自动化地收集和处理大量评论数据,并利用现有的自然语言处理库和深度学习模型进行情感分析。这为研究者、营销人员和舆情分析师提供了强大的工具,帮助他们更好地理解公众意见,并作出相应的决策和行动。
- Python爬虫技术:requests、Beatifuisoup、re、json
- 数据分析技术:pandas
- 情感分析技术:cnsenti
- 可视化技术:pyecharts
2实现
- 安装Python 3.7编译器
- 安装pycharm代码编辑器
- 使用cmd命令安装所需要的库,安装命令为:pip install -i Simple Index +库名,所需要的库包括:requests/lxml/bs4/pandas/pyecharts/cnsenti,安装好库之后,需要降低urllib3的库版本为1.26.15,使用pip安装即可。
- 打开pycharm,创建一个项目,命名为data
- 点greate即可

首先打开微博,定位所需要爬取的内容。搜索话题‘李佳琦带货怼网友’
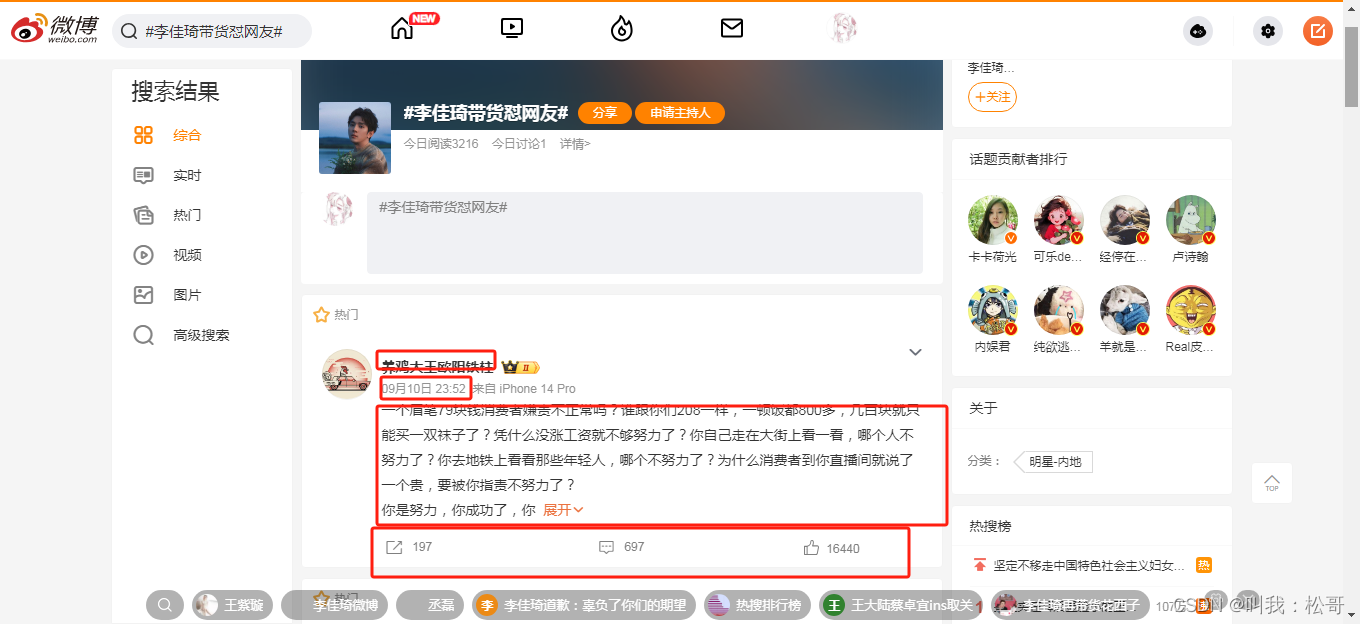
由下图可知,我们需要爬的数据包括图中框中地方:
通过右键--审查元素,可以定位到博文的内容信息和网页地址
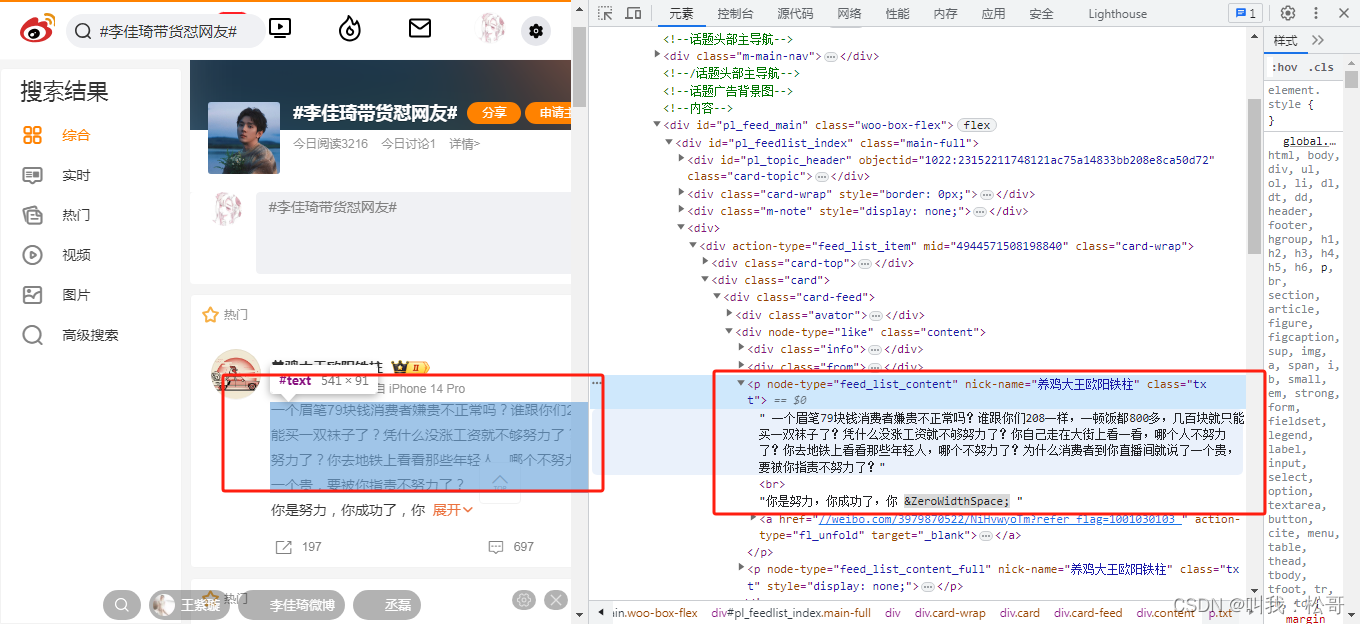
可以使用Beatifulsoup库解析网页数据,定位爬取对应的博文内容。
具体代码为:

其中需要添加headers和cookies,以及设置ip代理,防止网站反爬:
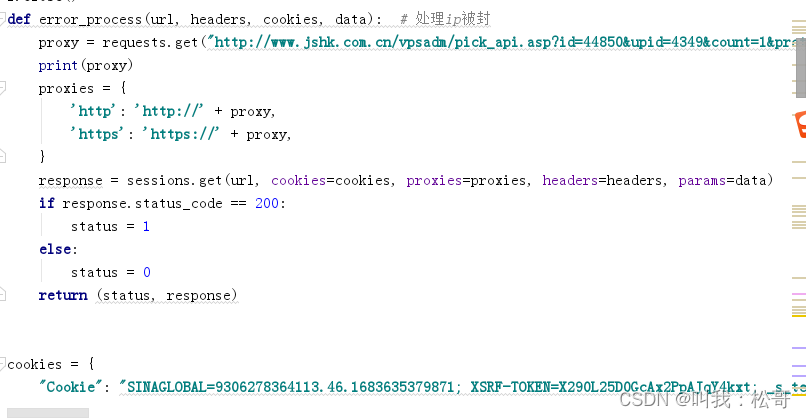
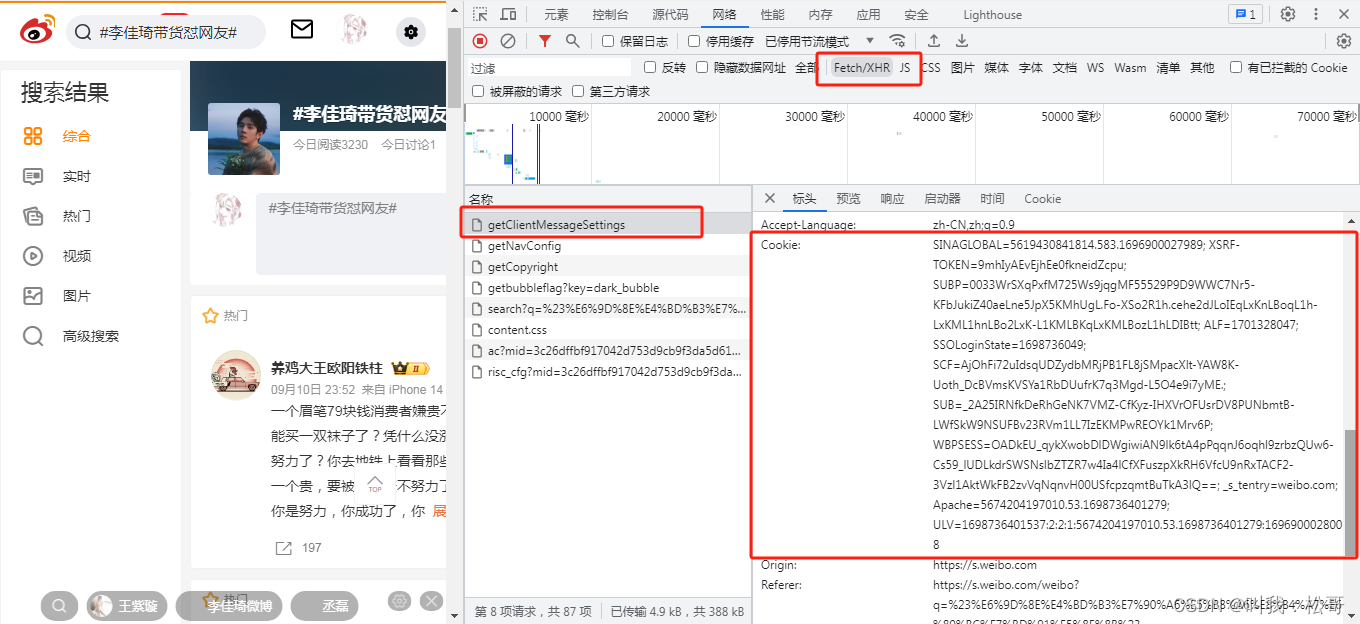
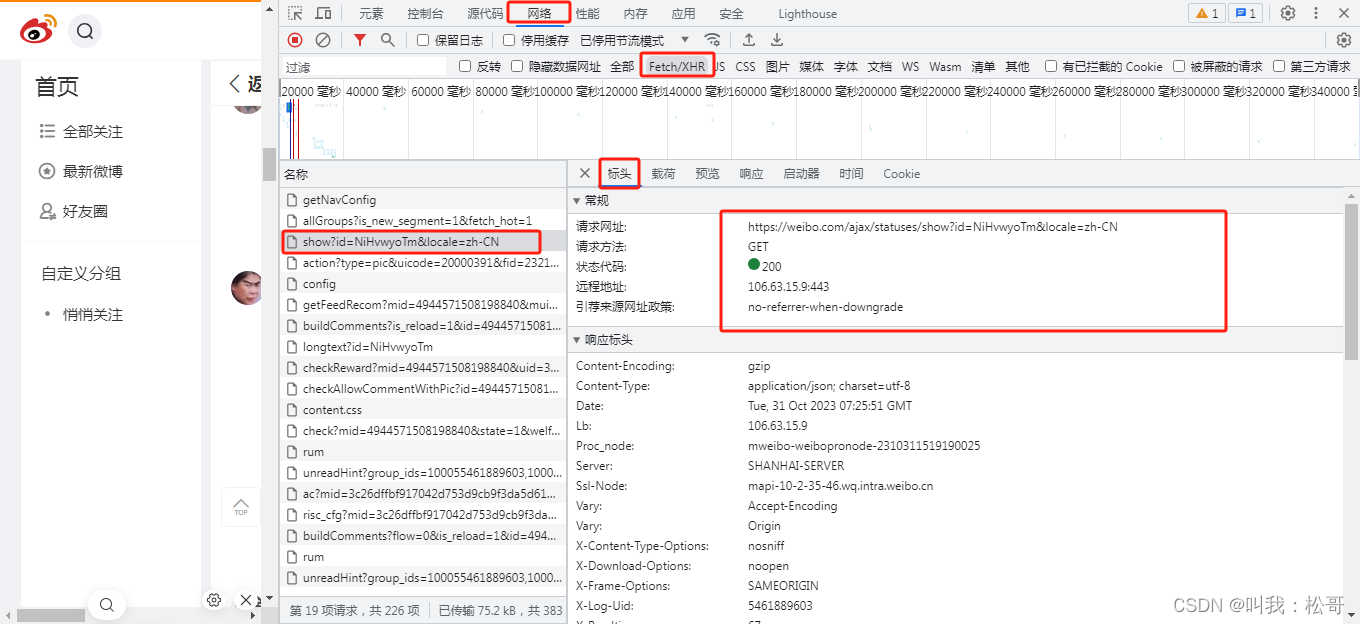
其中cookie和headers可以在浏览器中的网络---xhr---选择一个链接---标头中找到,按F12即可打开查看,如下图:
博文采集即可完成。
采集完博文,需要对每一条博文的评论进行采集,需要定位找到每一条博文的评论内容,具体步骤如下:
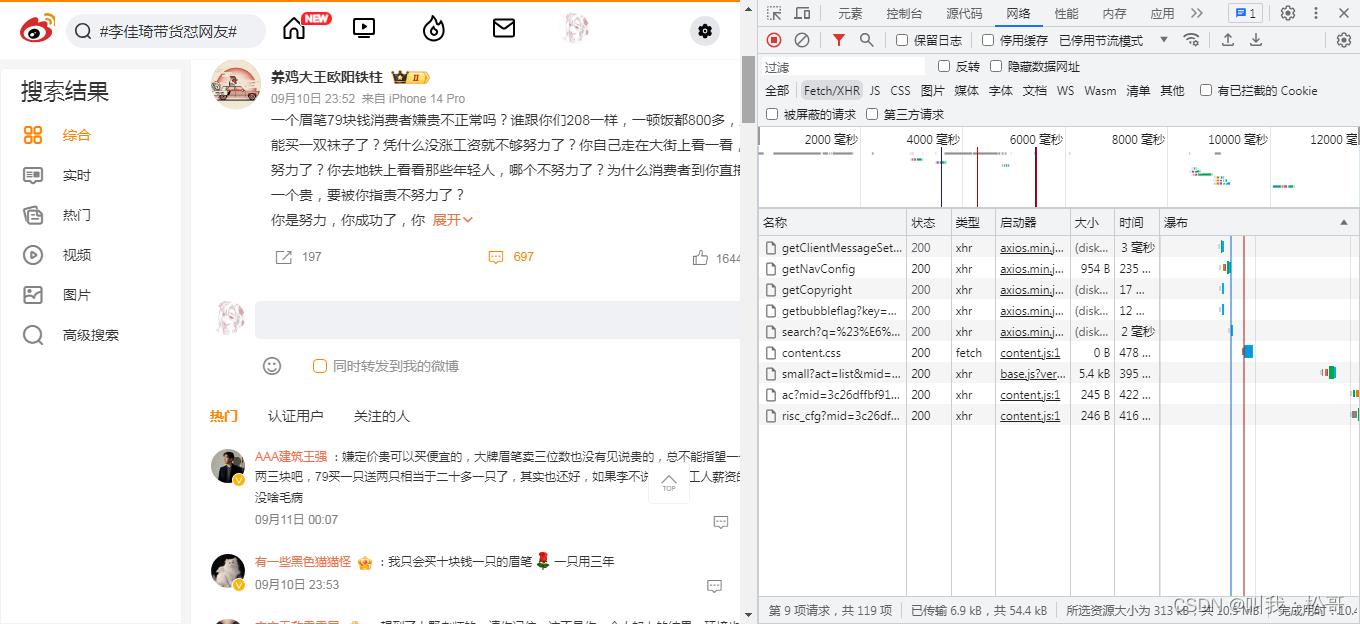
- 点击某一条博文评论展开,点击查看更多评论,如下图
注意下图网址中两个框的位置,一个是发布的博文的用户id一个是这个用户的微博编码,这两个是后面构造爬取评论内容的关键。
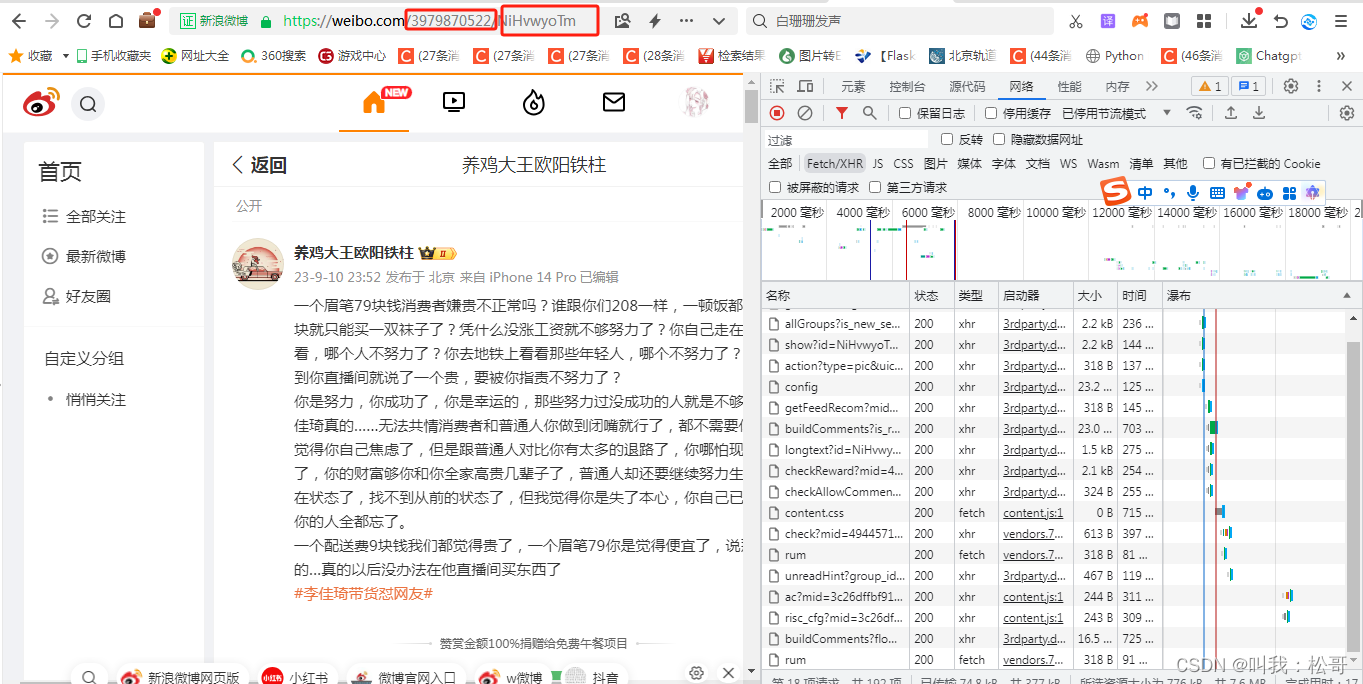
找到这个网址,即可发现这个网址存放完整的博文内容信息,包括博文内容、发布时间、地址、用户名等信息,详细可以点击预览查看。
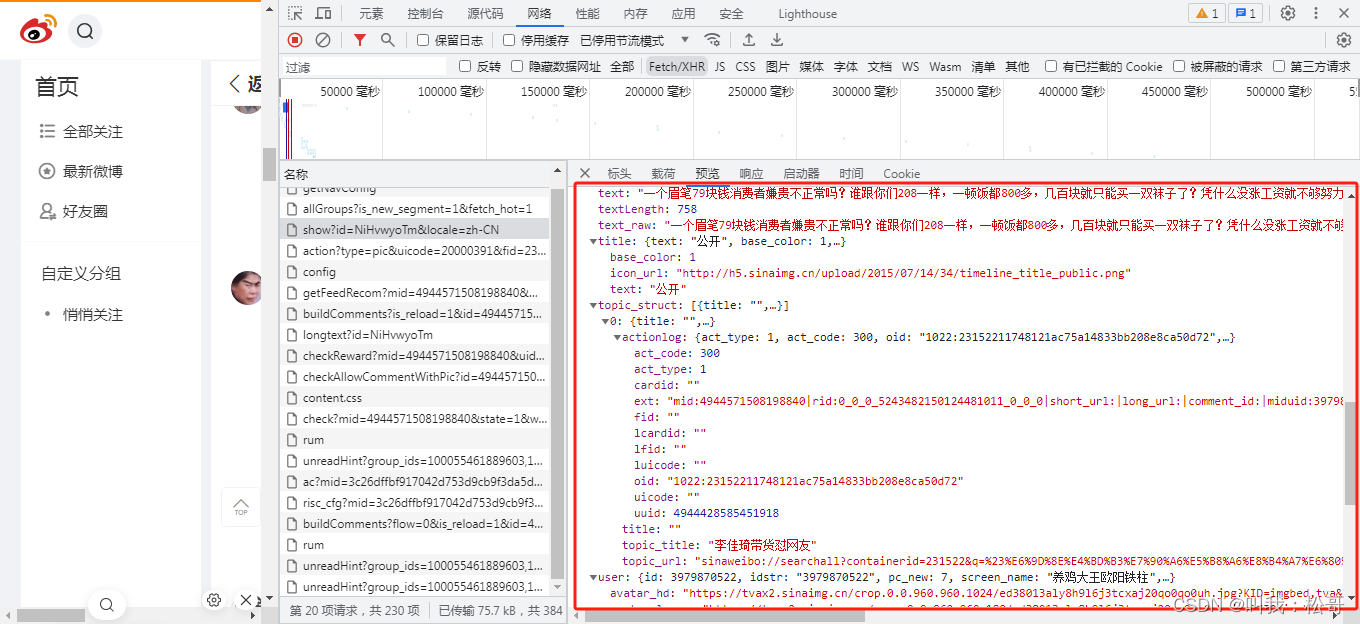
- 每一条博文评论采集,点开所有评论。
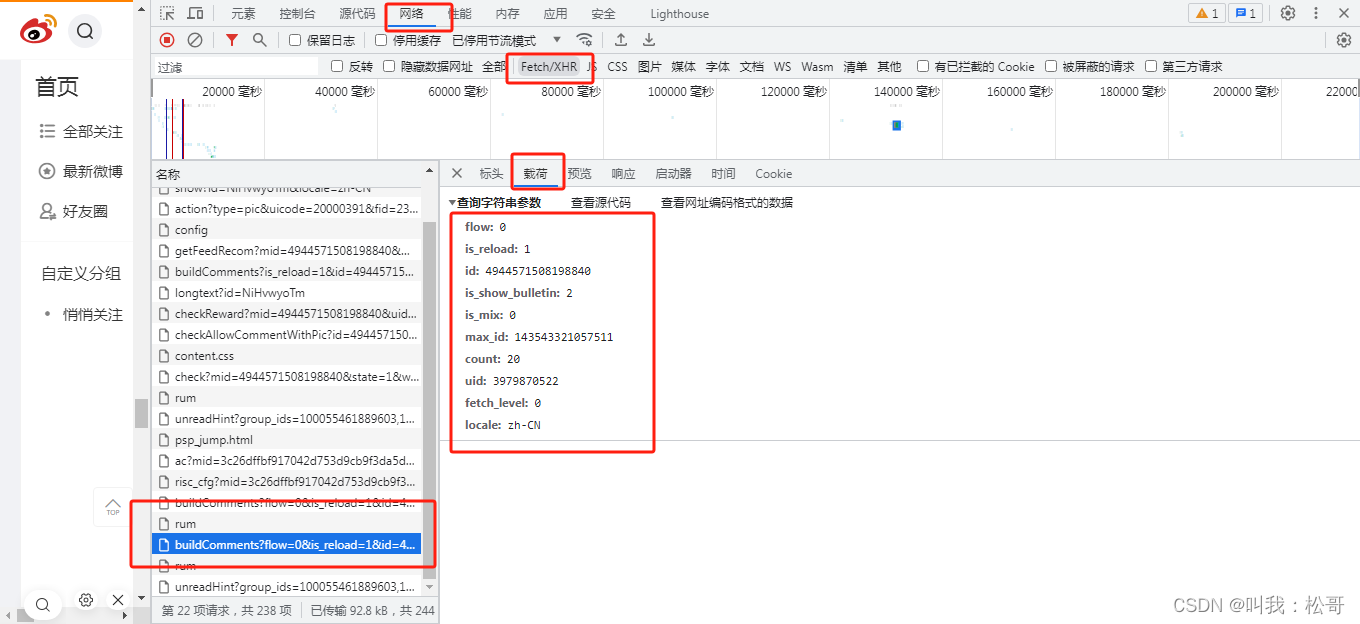
其中max_id: 143543321057511是最新页码,uid: 3979870522是用户ID,只有有这两样东西就能采集所有评论。
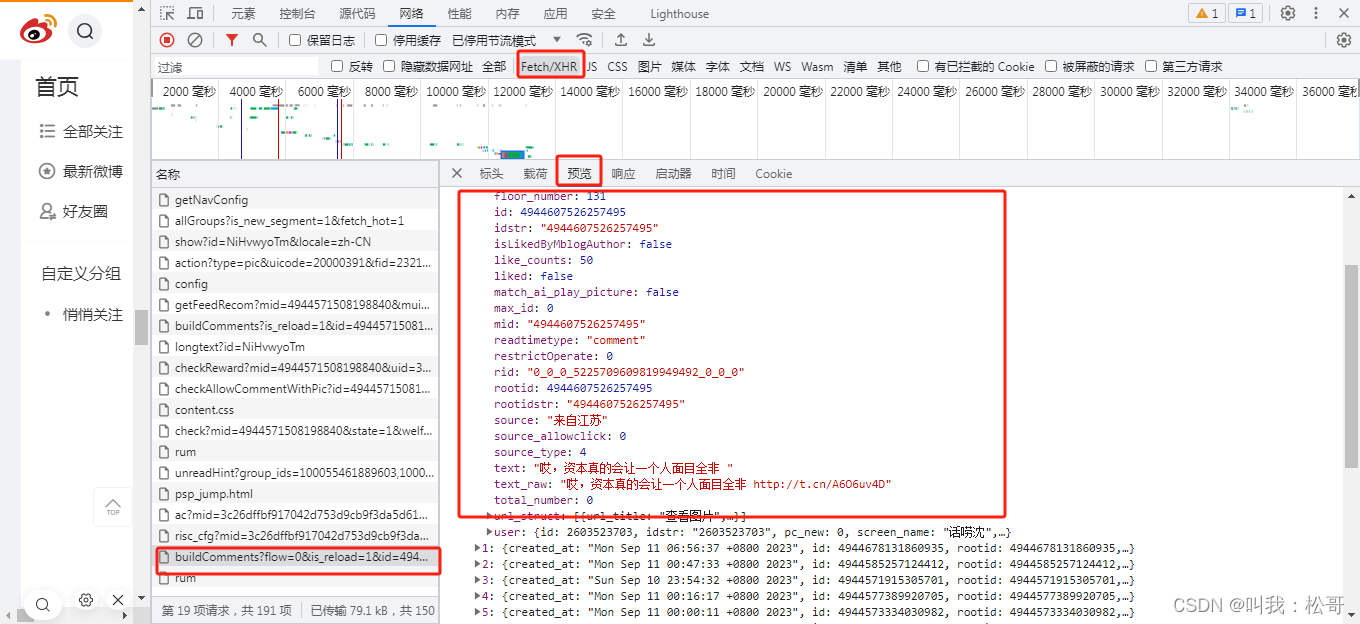
采集评论通过字典键值对获取。
致此,爬取某个话题下所有博文及评论的实现就此完成,最后将数据存储为csv,存储代码为:

采集结果为:
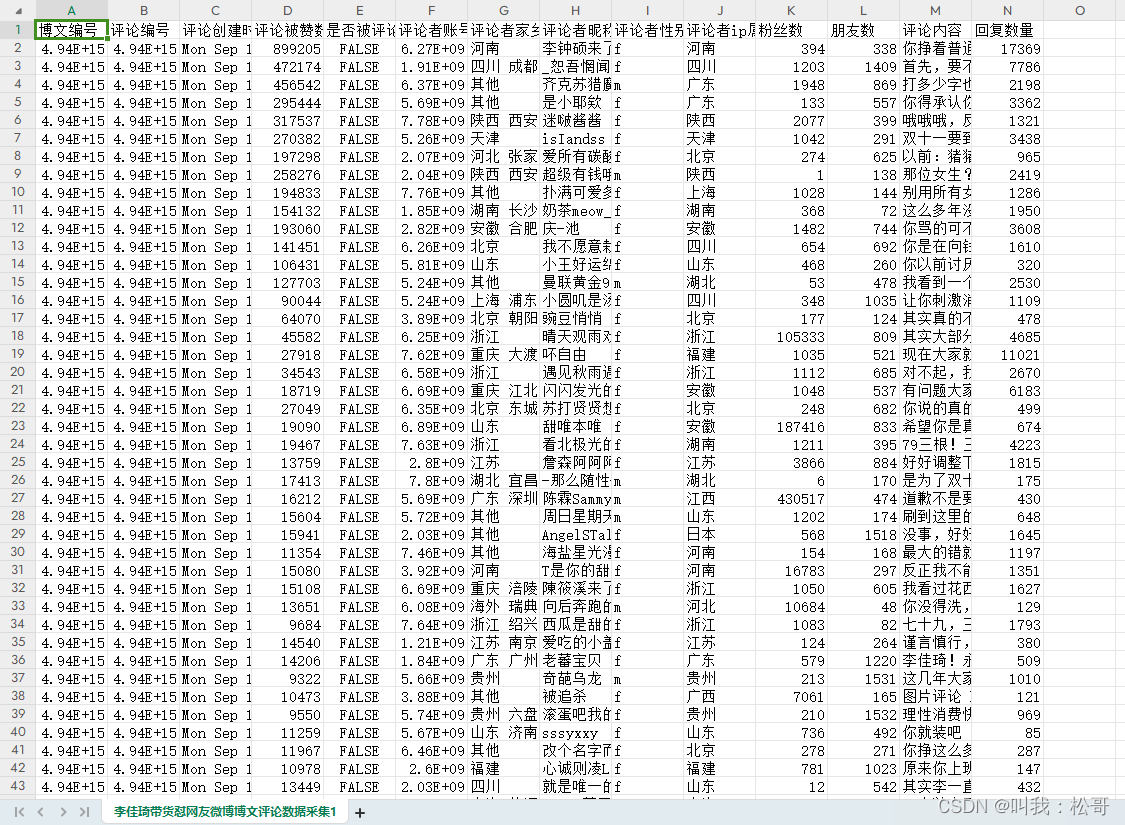
致采集好评论和博文数据,我们要对博文和评论进行整合,将他们中一些话题标志清洗掉,最后融合成一张表。首先对DataFrame中的'微博全文'、'评论内容'列进行了正则表达式替换操作,去除了字符串中的'#.*?#'部分。然后,通过重命名列名的方式,将'发帖人昵称'改为'昵称','微博全文'改为'内容','发文时间'改为'时间',并生成了一个新的DataFrame df1。
同样地,对data DataFrame中的'评论者昵称'、'评论内容'、'评论创建时间'列进行了正则表达式替换和列名重命名操作,生成了一个新的DataFrame data1。
最后,将df1和data1两个DataFrame按行合并,得到一个新的DataFrame li。接着,将li和da1按行合并,得到最终的DataFrame li1,并打印出来。具体代码为:

最后处理后运行结果为下图,得到5155条数据,3列的数据集:

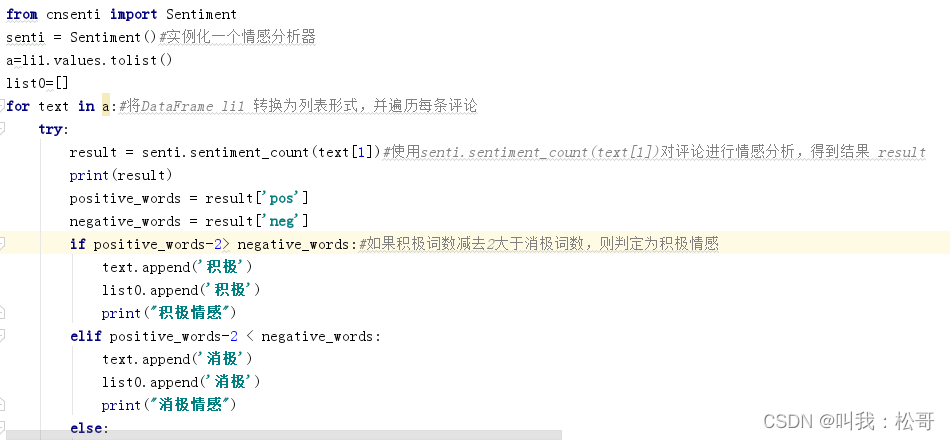
接下来就是对这数据集,也就是所有评论和博文进行情感分析。导入了cnsenti库中的Sentiment类。然后,通过senti = Sentiment()实例化一个情感分析器。
接下来,将DataFrame li1 转换为列表形式,并遍历每条评论。在循环中,使用senti.sentiment_count(text[1])对评论进行情感分析,得到结果 result。然后,根据积极词和消极词的数量判断情感倾向,如果积极词数减去2大于消极词数,则判定为积极情感;如果积极词数减去2小于消极词数,则判定为消极情感;否则判定为中性情感。
将判断结果添加到text列表中,并将情感标签存储在list0列表中。最后,将list0赋值给li1['情感分析']列,并打印出最终的DataFrame li1。
运行结果为,其中words为分词数量,sentences为句子数量,pos为积极词数量,neg为消极词数量:

完成情感分析后,接下来就是可视化,需要筛选日期进行分析,查看不同时间下的情感变化趋势。
首先使用pd.to_datetime()将DataFrame li1中的时间列转换为日期时间类型。
然后,筛选出9月10日至9月14日之间的数据,通过设置起始日期和结束日期,并利用条件筛选生成新的DataFrame filtered_df。接着,打印出筛选后的结果。
接下来,对于特定日期进行筛选。使用pd.Timestamp()指定目标日期,例如9月24日和10月24日,并通过比较日期部分筛选出相应日期的数据,生成新的DataFrame filtered_df1和filtered_df2。打印出筛选后的结果。
最后,对filtered_df进行处理,将时间列转换为字符串类型并截取日期部分。然后,按情感分析和时间进行分组计数,并通过.reset_index()重置索引,得到聚合后的DataFrame filtered_df3。打印出最终的结果。
运行结果为:
10月24日情感分析结果:

9月24日情感分析结果:

9月10日到9月14日情感分析结果

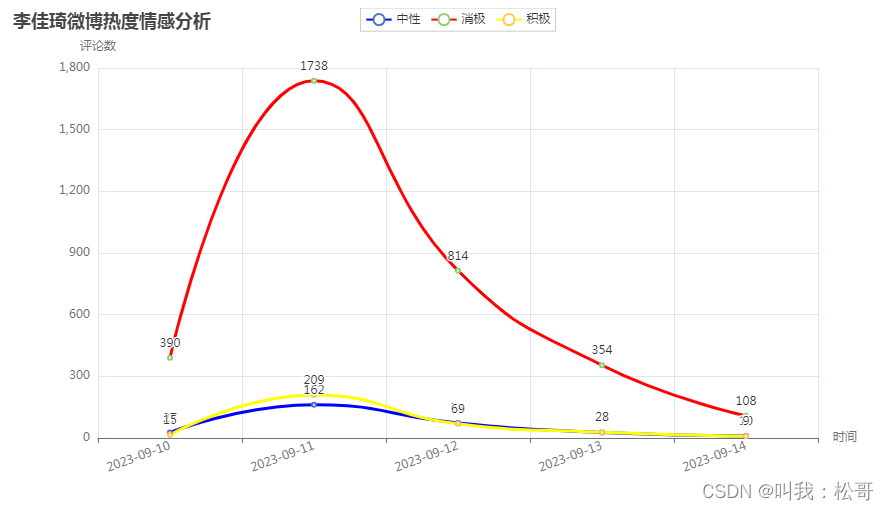
最后,使用pyecharts库中的Line类创建了一个折线图,并设置了x轴和y轴的数据。
在折线图中,通过.add_xaxis()方法设置x轴数据为筛选后的中性情感评论的时间列表。然后,使用.add_yaxis()方法分别添加中性、消极和积极情感评论的数量数据,并设置平滑曲线、线条样式和颜色。
接下来,通过.set_global_opts()方法设置全局配置,包括标题、x轴和y轴的名称。
最后,使用.render()方法将折线图渲染为HTML文件,并保存为"line_chart.html"。
运行结果为:
主要代码如下:

这篇关于基于Python的微博热点李佳琦忒网友话题的评论采集和情感分析的方法,利用情感分析技术对评论进行情感倾向性判断的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




