本文主要是介绍使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理优化实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文首发于 NVIDIA
一、概述
CodeFuse(https://github.com/codefuse-ai)是由蚂蚁集团开发的代码语言大模型,旨在支持整个软件开发生命周期,涵盖设计、需求、编码、测试、部署、运维等关键阶段。
为了在下游任务上获得更好的精度,CodeFuse 提出了多任务微调框架(MFTCoder),能够解决数据不平衡和不同收敛速度的问题。
通过对比多个预训练基座模型的精度表现,我们发现利用 MFTCoder [1,2] 微调后的模型显著优于原始基座模型。其中,尤为值得关注的是采用了 MFTCoder 框架,并利用多任务数据集进行微调的 CodeFuse-CodeLlama-34B [3] 模型,在 HumanEval 评估数据集中取得了当时的最好结果。具体来说,基于 CodeLlama-34b-Python 模型进行微调的 CodeFuse-CodeLlama-34B 在 HumanEval-python 上实现了 74.4% 的 pass@1(贪婪解码)。以下是完整的代码能力评估结果 :
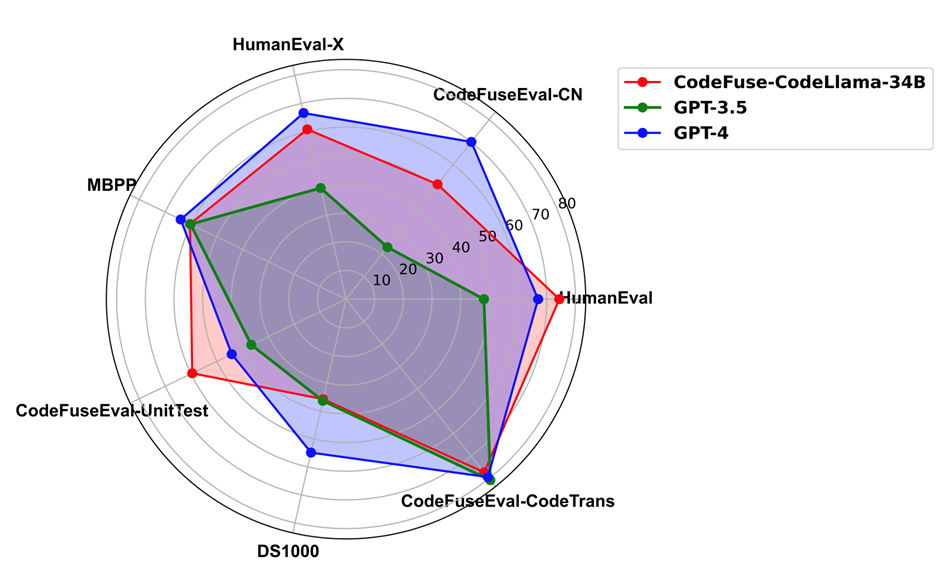
在代码补全、text2code、代码翻译、单测生成以及代码生成任务上,CodeFuse-CodeLlama-34B 全面超过 GPT-3.5;CodeFuse-CodeLlama-34B 能够在单测生成和代码补全(HumanEval )任务上超过 GPT-4。同时,上述微调模型、MFTCoder 训练框架和高质量代码数据集已经开源(github: https://github.com/codefuse-ai)。
然而,CodeFuse-CodeLlama-34B 的部署遇到了如下两个挑战:
1)数据类型为 fp16 的 34B 模型,显存占用为 68 GB,至少需要 3 张 A10 才能加载模型,部署成本很高;
2)在模型推理的生成阶段,通常伴随着长条形的矩阵运算,此时计算量较小,不足以掩盖 GPU 的访存延迟,即 memory bound 问题,此时程序的性能受限于 GPU 带宽。
为了解决上述问题,我们利用 GPTQ 量化技术,在降低了部署成本的同时,也缓解了 GPU 的带宽压力 ,从而显著提升了推理速度。最终,CodeFuse-CodeLlama-34B 的 int4 量化模型可以部署在单张 A10 显卡上,推理速度可以达到 20 tokens/s (batch_size=1)。同时,相较于 fp16 数据精度的模型,通过算法上的优化,int4 量化引入的精度下降可以控制在 1% 以内。下面,我们从模型量化和测试两个方面展示我们是如何实现 CodeFuse-CodeLlama-34B 模型的 int4 量化部署的。另外,TensorRT-LLM 也支持了 CodeFuse 中基于 MFTCoder 训练的开源模型部署。
二、CodeFuse-CodeLlama-34B int4 量化
这里我们使用 GPTQ [4] 技术对模型进行 int4 量化。GPTQ 是对逐层量化范式经典框架 OBQ(Optimal Brain Quantization)[5] 的高效实现,能够利用单张 A100-80G 在 4 小时内完成 OPT-175B 模型的量化,并且可以获得较好的准确率。
另外,我们这里采用了静态量化方式,即通过矫正数据离线地进行量化,得到诸如缩放因子和零点的量化参数,在推理时不再进行量化参数的更新。与之对应的是动态量化,会在模型推理的同时根据输入进行量化参数的调整。最后,我们这里进行的是 int4-weight-only 量化,即只对权重进行量化而不对层输入进行量化,即 W4A16 量化。
GPTQ 算法

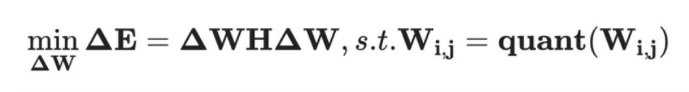

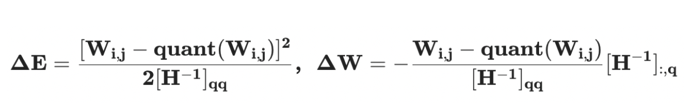

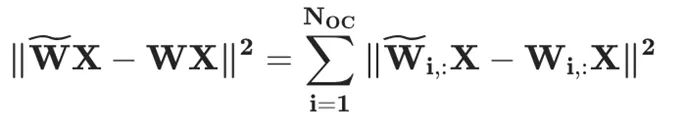

- 所有输出通道共享相同的量化顺序,从而使得行间共享同一份 Hessian 矩阵,大大减少了算法计算量。
- 使用一次 Cholesky 分解代替了在 GPTQ 每次迭代中对整个 Hessian 矩阵的逆矩阵的高斯消元迭代更新方式。既大大减少了计算量,又得以利用成熟 GPU 矩阵库中的 Cholesky 算法,且避免了迭代更新方式在矩阵运算中所带来的数值不稳定问题。
- 通过将整个计算过程由对单个输入通道进行更新,等效转变为划分 batch 并逐 batch 更新的方式,避免了每次量化对整个 Hessian 与权重矩阵的 GPU 读写操作,大大降低了 GPU 访存数量。
上述的改进使得 GPTQ 可以有效提升 GPU 利用率,从而能够对大模型进行高效量化。
三、int4-weight-only 量化
这里我们利用开源工具 AutoGPTQ(https://github.com/PanQiWei/AutoGPTQ)进行量化,工具超参数如下;
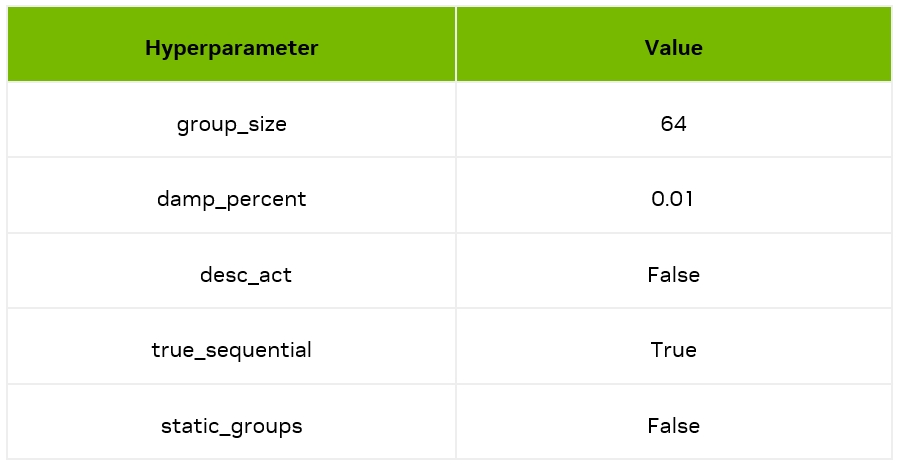
利用 AutoGPTQ 进行模型加载和推理的例子如下:
import os
import torch
import time
from modelscope import AutoTokenizer, snapshot_download
from auto_gptq import AutoGPTQForCausalLMos.environ["TOKENIZERS_PARALLELISM"] = "false"def load_model_tokenizer(model_path):"""Load model and tokenizer based on the given model name or local path of downloaded model."""tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False,lagecy=False)tokenizer.padding_side = "left"tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids("<unk>")tokenizer.eos_token_id = tokenizer.convert_tokens_to_ids("</s>")model = AutoGPTQForCausalLM.from_quantized(model_path, inject_fused_attention=False,inject_fused_mlp=False,use_cuda_fp16=True,disable_exllama=False,device_map='auto' # Support multi-gpus)return model, tokenizerdef inference(model, tokenizer, prompt):"""Uset the given model and tokenizer to generate an answer for the speicifed prompt."""st = time.time()inputs = prompt if prompt.endswith('\n') else f'{prompt}\n'input_ids = tokenizer.encode(inputs, return_tensors="pt", padding=True, add_special_tokens=False).to("cuda")with torch.no_grad():generated_ids = model.generate(input_ids=input_ids,top_p=0.95,temperature=0.1,do_sample=True,max_new_tokens=512,eos_token_id=tokenizer.eos_token_id,pad_token_id=tokenizer.pad_token_id )print(f'generated tokens num is {len(generated_ids[0][input_ids.size(1):])}')outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) print(f'generate text is {outputs[0][len(inputs): ]}')latency = time.time() - stprint('latency is {} seconds'.format(latency))if __name__ == "__main__":model_dir = snapshot_download('codefuse-ai/CodeFuse-CodeLlama-34B-4bits', revision='v1.0.0')prompt = 'Please write a QuickSort program in Python'model, tokenizer = load_model_tokenizer(model_dir)inference(model, tokenizer, prompt)在做静态量化时,GPTQ 使用矫正数据集作为输入计算 Hessian 矩阵,从而更新未量化权重进而补偿量化带来的误差。如果推理阶段的输入和矫正数据集有偏差(bias),那么量化时用矫正数据得到的 Hessian 矩阵就无法完全反映推理输入,这会导致 GPTQ 的误差补偿失效(失效的程度和偏差成正比),出现量化模型在推理输入上量化误差变大的情况,进而导致量化模型的精度下降。
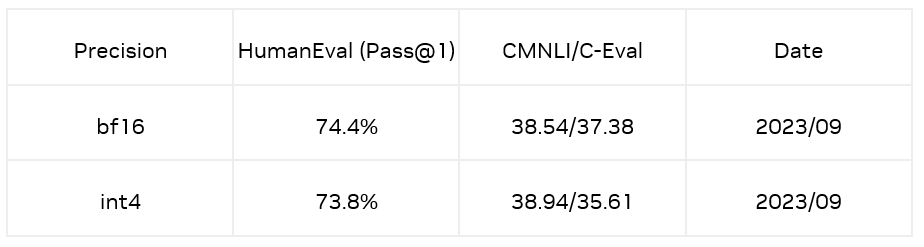
为了解决上述问题,对于微调模型,我们使用了一种数据分布对齐技术减少模型量化带来的损失。通过抽取训练数据(CodeFuse 开源的高质量代码数据集 evol)中的 Question 作为引导方式,利用原始模型生成 Answer,将 Question 和 Answer 拼接起来作为矫正数据;最终在 HumanEval Benchmarks 的 Python pass@1 取得了 73.8% 的准确率,相较于 bf16 模型仅有 0.6% 的精度损失。同时,在 CMNLI 和 C-Eval 两个数据集的精度损失也比较少。
四、构建 TensorRT 引擎
在通过 AutoGPTQ 可以得到 safetensors 格式的 int4 量化模型 [6] 后,我们的目标是构建单卡 TensorRT 引擎,同时保证 activation 是 fp16 的数据精度。通过 examples/llama/build.py 进行 TensorRT 引擎构建时,需要关注如下参数:
- dtype:设置为 fp16
- use_gpt_attention_plugin:设置为 fp16,构建引擎时利用 gpt a ttention plugin 并且数据精度为 fp16
- use_gemm_plugin:设置为 fp16,构建引擎时利用 gemm_plugin 并且数据精度为 fp16
- use_weight_only:触发 weight only 量化
- weight_only_precision:设置为 int4 _gptq,表示构建 W4A16 的 GPTQ 量化模型引擎
- per_group:gptq 为group-wise 量化,所以需要触发 per-group
- max_batch_size: TensorRT 引擎最大允许 batch size
- max_input_len:TensorRT 引擎最大允许输入长度
- max_output_len:TensorRT 引擎最大允许输出长度
综上,我们在单卡 A10/A100 上构建 TensorRT 引擎的命令如下:
python build.py --model_dir "${model_dir}" \--quant_safetensors_path "${quant_safetensors_path}" \--dtype float16 \--use_gpt_attention_plugin float16 \--use_gemm_plugin float16 \--use_weight_only \--weight_only_precision int4_gptq \--max_batch_size 1 \--max_input_len 2048 \--max_output_len 1024 \--per_group \--output_dir "${engin_dir}" 2>&1 | tee dev_build.log五、测试
性能
下面,我们主要测试了 batch size 为 1 时,不同的输入输出长度和量化精度情况下,TensorRT-LLM 在 A10/A100 上的推理速度表现。可以看到,在 A100 上,TensorRT-LLM 的 int4 相对 fp16,最高能够带来 2.4 倍的加速,相对 int8 最高也能带来 1.7 倍的加速。
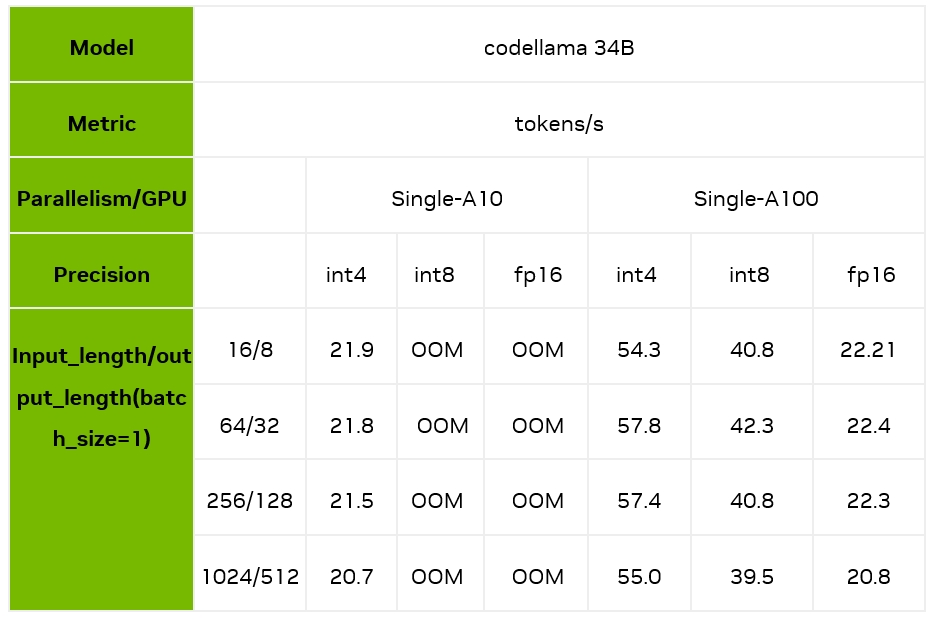
注意:以上性能测试均基于 TensorRT-LLM 的 0.6.1 版本
显存占用和结果测试
我们测量了模型加载后占用的显存占用情况,以及输入 2048/1024 tokens 并输出 1024/2048 tokens 时的显存使用情况;同时我们也测试了量化前后的精度情况,如下表所示:
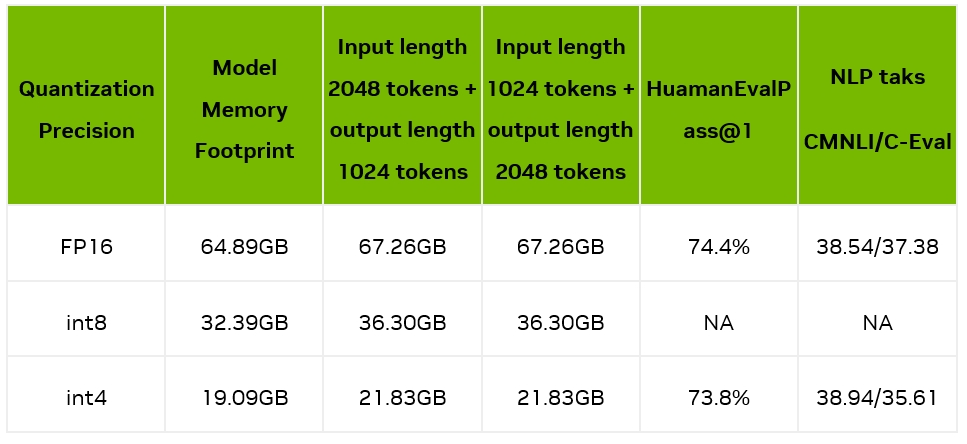
可见,4bit 量化后,显存占用大幅缩小,在一张 A10(24GB 显存)上就能部署 34B 的大模型,具备非常好的实用性。
六、模型演示
我们通过终端命令行 [7] 以及网页聊天机器人 [8] 两种不同的方式,展示我们最终的推理效果,具体细节可以访问开源的链接。
Cli Demo

Webui Demo
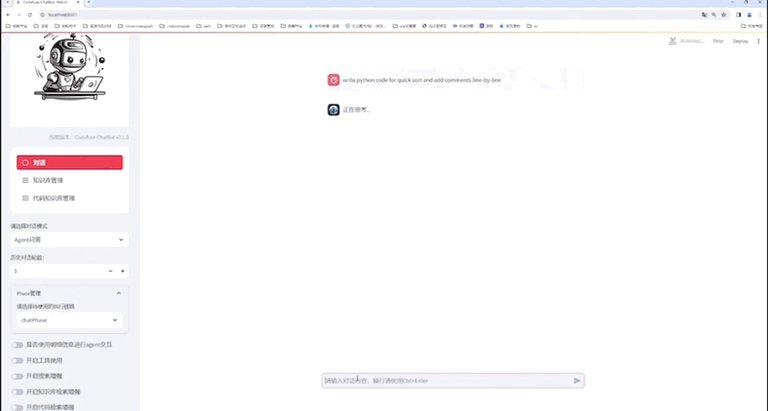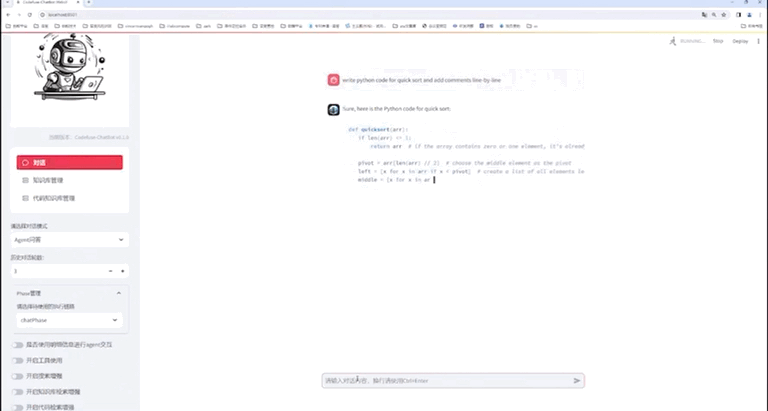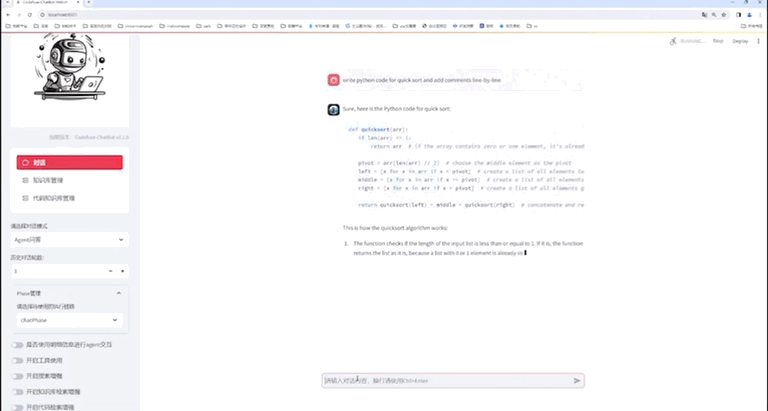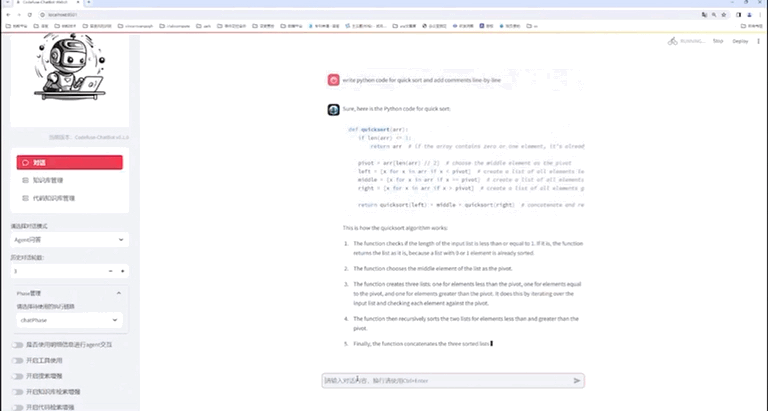
七、总结
在这篇文章中,我们介绍了如何使用 TensorRT-LLM 来加速 CodeFuse 的推理性能。具体而言,我们按照顺序展示了如何使用 GPTQ Int4 量化方法、增强 GPTQ 量化算法精度的自动对齐技术、TensorRT-LLM int4 量化模型的使用方法以及相应的评估过程。通过 TensorRT-LLM 的支持,CodeFuse 实现了较低的推理延迟和优化的部署成本。欢迎大家关注 CodeFuse 获取最新发布的更高准确率的微调大模型。
参考资料:
[1] Liu, B., Chen, C., Liao, C., Gong, Z., Wang, H., Lei, Z., Liang, M., Chen, D., Shen, M., Zhou, H., Yu, H., & Li, J. (2023). MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning. ArXiv, abs/2311.02303.
[2] Zhang, Z., Chen, C., Liu, B., Liao, C., Gong, Z., Yu, H., Li, J., & Wang, R. (2023). Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code.
[3] https://huggingface.co/codefuse-ai/CodeFuse-CodeLlama-34B
[4] Frantar, E., Ashkboos, S., Hoefler, T., & Alistarh, D. (2022). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. ArXiv, abs/2210.17323.
[5] Frantar, E., Singh, S. P., Alistarh, D. (2022). Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning. Advances in Neural Information Processing Systems, 35, 4475-4488.
[6] https://huggingface.co/codefuse-ai/CodeFuse-CodeLlama-34B-4bits
[7] Codefuse-ai: https://github.com/codefuse-ai
[8] Codefuse-chatbot: https://github.com/codefuse-ai/codefuse-chatbot
这篇关于使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理优化实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






