本文主要是介绍PLAN方法:解决 GAN 生成医学图像 Latent 空间中的隐私保护方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PLAN方法:解决 GAN 生成医学图像 Latent 空间中的隐私保护方法
- PLAN 原理
- StyleGAN 生成视网膜图
- k-SALSA 生成视网膜图
- PLAN方法 生成视网膜图
- 总结
PLAN 原理
论文:https://arxiv.org/abs/2307.02984
代码:https://github.com/perceivelab/PLAN
生成对抗网络 (GAN) 已经证明了其生成与目标分布匹配的合成样本的能力(比如 Sytle GAN 生成视网膜图)。
然而,从隐私角度来看,使用 GAN 作为数据共享的代理并不是一个安全的解决方案,因为它们往往会在latent空间中嵌入接近重复的真实样本。
最近的研究通过在潜在空间中聚合样本来解决这个问题,是受到k-匿名原则的启发,但这样做的缺点是将数据集的大小减少了k倍。
PLAN方法旨在通过提出一种隐空间(Latent Space)导航策略来缓解这个问题,该策略能够生成多种合成样本,这些样本可以支持深度模型的有效训练,同时以原则性的方式解决隐私问题。
我们的方法利用辅助身份分类器作为指导,以非线性的方式在潜在空间中的点之间行走,最小化与真实样本近似副本的碰撞风险。
论文实证,给定潜在空间中任意一对随机点,我们的行走策略比线性插值更安全。
然后,我们将寻路策略与k-same方法结合起来,并在结核病分类和『糖尿病视网膜病变分类』的两个基准测试中进行了测试,使用我们的方法生成的样本训练模型可以减轻性能下降,同时保持隐私保护。
对于糖尿病视网膜病变分类,使用了APTOS眼底图像数据集,这个数据集包含被眼科医生按照严重程度分为五级的视网膜图像。
为了模拟医学应用中常见的数据量有限的情况,随机选择了950张图像,均匀分布在各个类别中。
所有图像都被调整大小到256×256,并按照70%、10%、20%的比例划分为训练集、验证集和测试集。
StyleGAN 生成视网膜图
比如使用StyleGAN来生成视网膜图:
- 训练数据收集:首先收集大量真实的视网膜图像作为训练数据集。
- 训练StyleGAN:使用这些真实的视网膜图像来训练StyleGAN模型。这个训练过程通过不断的迭代,让生成器(G)学习如何产生看起来真实的视网膜图像,而鉴别器(D)学习如何区分真实图像和生成图像。
- 生成图像:训练完成后,可以通过向生成器输入潜在空间中的随机点,生成新的视网膜图像。
但是,如果直接从GAN生成数据,可能会有隐私泄露的风险,特别是在图像与个人健康数据紧密相关的情况下。
k-SALSA 生成视网膜图
k-SALSA是一个应用了k-匿名原则的算法,它在生成合成的视网膜底片图像时尝试保持隐私。
k-SALSA通过将k个真实样本合并成一个合成样本来实现这一点,这样可以保证合成样本不会直接映射回任何个体的真实样本。
选择真实样本:从真实数据集中选择k组样本。
样本聚合:将这k组样本在潜在空间中聚合,生成一个合成样本。这样做的目的是确保任何合成的图像都不会直接对应于任何一个具体的真实样本,从而增加了隐私保护。
风格对齐:k-SALSA方法特别提出了局部风格对齐策略,以确保合成的图像在视觉上类似于原始数据,保持了医学上的有效性,同时避免了暴露任何个人的特定特征。
但通过这种方法生成的数据集大小会减少k倍。
因为每k个真实样本只生成了一个合成样本。
如果原始数据集有N个样本,那么应用k-SALSA之后,只会有 N/k 个合成样本,这显著减少了数据集的大小。
PLAN方法 生成视网膜图
而使用PLAN方法生成视网膜图像则添加了隐私保护的步骤:
- 使用身份和辅助分类器:在训练过程中,PLAN方法会利用一个身份分类器来识别和隔离与个体身份相关的特征,并使用一个辅助分类器来确保保留与视网膜图像分类相关的特征。
- 隐私保护的潜在空间导航:在潜在空间中,PLAN方法会找到一条路径,这条路径上的点可以生成视网膜图像,同时避免泄露任何个人的特定特征。
- 生成合成样本:沿着这条导航路径,PLAN方法可以生成新的视网膜图像,这些图像在保留了用于诊断或分析所需特征的同时,不会泄露个人身份信息。
PLAN方法提供了一个额外的隐私保护框架,允许在生成视网膜图像的同时减少潜在的隐私风险。
- 使用专门的身份分类器来隔离个体身份特征,同时利用辅助分类器确保合成图像保留医学上重要的分类特征。
- PLAN方法通过在潜在空间中寻找一条安全路径来生成新的视网膜图像
- 该路径的点被优化以避免生成任何可以追溯到训练集中个体的图像
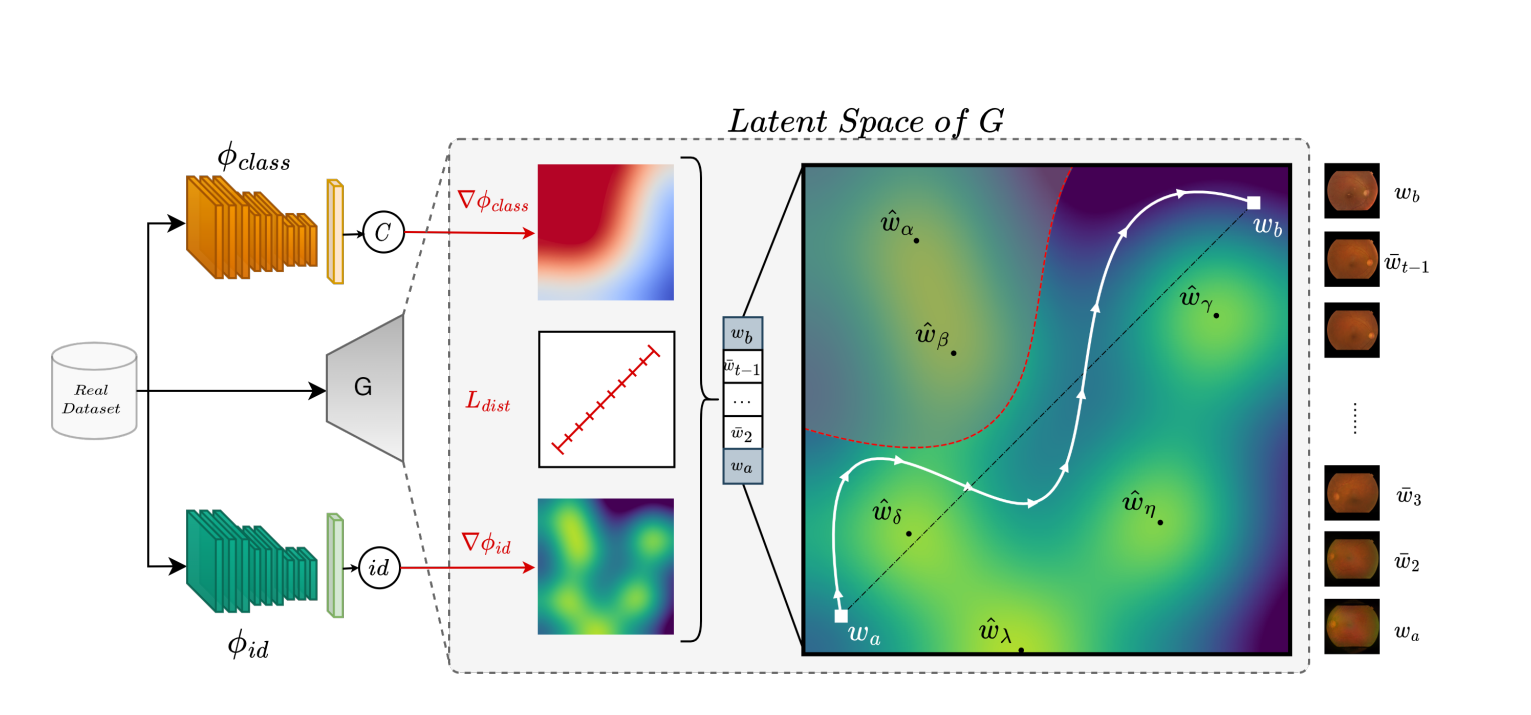
PLAN方法 具体步骤:
-
GAN训练:首先,需要使用真实的视网膜底片图像来训练一个GAN模型,这个模型能够学习和复现真实视网膜图像的分布。在这一阶段,模型的生成器(G)将能够从潜在空间(W)中产生新的图像(X)。
-
潜在空间优化:一旦模型被训练好,接下来的步骤是在潜在空间中定义和优化一个隐私保护的轨迹。这意味着我们要找到一组潜在向量 W ‾ ) \overline{W}) W),使得从这些向量生成的图像与训练集中的图像有足够的差异,以保护个人隐私。这个过程需要避免那些可能对应于真实视网膜图像的潜在区域。
计算潜在空间中轨迹的等距离损失: L d i s t = ∑ i = 1 T − 1 ∥ w ˉ i , w ˉ i + 1 ∥ 2 2 \mathcal{L}_{\mathrm{dist}}=\sum_{i=1}^{T-1}\left\|\bar{\mathbf{w}}_i,\bar{\mathbf{w}}_{i+1}\right\|_2^2 Ldist=∑i=1T−1∥wˉi,wˉi+1∥22
这个公式是计算潜在空间中轨迹的“等距离损失”,确保在潜在空间中导航时,连续点之间的距离大致保持一致,以此促进样本多样性并防止模式崩溃。
- L d i s t \mathcal{L}_{\mathrm{dist}} Ldist:这是等距离损失的表示,用于度量潜在空间中连续点之间的距离。
- ∑ i = 1 T − 1 \sum_{i=1}^{T-1} ∑i=1T−1:这表示对所有T步中的连续点对进行求和。
- ∥ w ˉ i , w ˉ i + 1 ∥ 2 2 \left\|\bar{\mathbf{w}}_i,\bar{\mathbf{w}}_{i+1}\right\|_2^2 ∥wˉi,wˉi+1∥22:这是计算两个连续潜在点 w ˉ i \bar{\mathbf{w}}_i wˉi 和 w ˉ i + 1 \bar{\mathbf{w}}_{i+1} wˉi+1 之间的欧几里得距离(L2范数)的平方。
用于在PLAN方法中优化潜在空间的路径,确保生成的合成样本具有多样性,同时避免生成与真实样本过于接近的图像
身份损失-隐私保护导航: L i d = ∑ i = 1 T K L [ ϕ i d ( G ( w ˉ i ) ) ∥ U ( 1 / n i d ) ] \mathcal{L}_{\mathrm{id}}=\sum_{i=1}^T\mathrm{KL}[\phi_{id}(G(\bar{\mathbf{w}}_i))\parallel\mathcal{U}(1/n_{\mathrm{id}})] Lid=∑i=1TKL[ϕid(G(wˉi))∥U(1/nid)]
- L i d \mathcal{L}_{\mathrm{id}} Lid:这是身份损失的表示,用于评估生成样本的隐私保护程度。
- ∑ i = 1 T \sum_{i=1}^T ∑i=1T:这表示对所有生成的潜在点进行求和。
- K L [ ϕ i d ( G ( w ˉ i ) ) ∥ U ( 1 / n i d ) ] \mathrm{KL}[\phi_{id}(G(\bar{\mathbf{w}}_i))\parallel\mathcal{U}(1/n_{\mathrm{id}})] KL[ϕid(G(wˉi))∥U(1/nid)]:这是计算 KL 散度,用于衡量由辅助网络 ϕ i d \phi_{id} ϕid 在点 w ˉ i \bar{\mathbf{w}}_i wˉi 上生成的样本的身份分类分布与均匀分布 U ( 1 / n i d ) \mathcal{U}(1/n_{\mathrm{id}}) U(1/nid) 之间的差异。这里的 ϕ i d \phi_{id} ϕid 是身份分类器, G ( w ˉ i ) G(\bar{\mathbf{w}}_i) G(wˉi) 是根据潜在点 w ˉ i \bar{\mathbf{w}}_i wˉi 生成的样本,而 U ( 1 / n i d ) \mathcal{U}(1/n_{\mathrm{id}}) U(1/nid) 是均匀分布,表示所有身份的平均可能性。
- n i d n_{\mathrm{id}} nid:这表示数据集中不同身份的数量。
用于优化生成样本的身份不确定性,通过最大化与均匀分布的KL散度,来确保生成样本不会与任何特定的训练样本相似
正确分类-保持类别一致性: L c l a s s = ∑ i = 1 T C E [ ϕ c l a s s ( G ( w ˉ i ) ) , y ] \mathcal{L}_{\mathrm{class}}=\sum_{i=1}^T\mathrm{CE}\left[\phi_{\mathrm{class}}(G(\bar{\mathbf{w}}_i)),y\right] Lclass=∑i=1TCE[ϕclass(G(wˉi)),y]
- L c l a s s \mathcal{L}_{\mathrm{class}} Lclass:这是类别一致性损失的表示,用于评估生成样本的类别准确性。
- ∑ i = 1 T \sum_{i=1}^T ∑i=1T:这表示对所有生成的潜在点进行求和。
- C E [ ϕ c l a s s ( G ( w ˉ i ) ) , y ] \mathrm{CE}\left[\phi_{\mathrm{class}}(G(\bar{\mathbf{w}}_i)),y\right] CE[ϕclass(G(wˉi)),y]:这是计算交叉熵(Cross-Entropy)损失,用于衡量由辅助分类网络 ϕ c l a s s \phi_{\mathrm{class}} ϕclass 在点 w ˉ i \bar{\mathbf{w}}_i wˉi 上生成的样本的预测分类与实际分类 (y) 之间的差异。这里的 ϕ c l a s s \phi_{\mathrm{class}} ϕclass 是用于执行原始数据集分类的辅助分类器,而 G ( w ˉ i ) G(\bar{\mathbf{w}}_i) G(wˉi) 是根据潜在点 w ˉ i \bar{\mathbf{w}}_i wˉi 生成的样本。
- y y y:这是目标类别标签,表示每个生成样本应该属于的类别。
用于确保在潜在空间中生成的样本不仅隐私安全,而且在医学上具有正确的分类属性。
总损失函数: L P L A N = L d i s t + λ 1 L i d + λ 2 L l a b e l \mathcal{L}_{\mathrm{PLAN}}=\mathcal{L}_{dist}+\lambda_1\mathcal{L}_{id}+\lambda_2\mathcal{L}_{label} LPLAN=Ldist+λ1Lid+λ2Llabel
- L P L A N \mathcal{L}_{\mathrm{PLAN}} LPLAN:这是PLAN方法的总损失函数。
- L d i s t \mathcal{L}_{\mathrm{dist}} Ldist:等距离损失,确保潜在空间导航过程中生成的连续样本之间的距离大致一致,促进样本多样性。
- λ 1 L i d \lambda_1\mathcal{L}_{\mathrm{id}} λ1Lid:身份损失,乘以权重因子 (\lambda_1),用于最大化生成样本的身份不确定性,以增强隐私保护。
- λ 2 L c l a s s \lambda_2\mathcal{L}_{\mathrm{class}} λ2Lclass:类别一致性损失,乘以权重因子 (\lambda_2),用于确保生成样本在医学分类上的准确性。
- λ 1 和 λ 2 \lambda_1 和 \lambda_2 λ1和λ2:这些是权重系数,用于平衡不同损失函数对总损失的贡献。
这个总损失函数结合了三个关键因素:样本多样性、隐私保护和类别准确性,以生成对下游任务(如疾病诊断)有用且隐私安全的合成医学图像。
-
合成数据集生成:通过优化的轨迹,我们可以在潜在空间中安全地移动,生成新的合成视网膜底片图像,这些图像既不会揭露个人身份,也包含了临床上有意义的特征,使其适合于如疾病诊断这样的下游任务。
-
实际应用:在实际应用中,我们可能会使用一个k-same方法来产生一些合成的视网膜底片图像,然后利用PLAN在这些样本之间的潜在空间进行导航,以增加数据集的大小,同时保留隐私保护。生成的扩展数据集然后可以用来训练下游的分类器 ϕ d o w n \phi_{down} ϕdown,仅使用合成样本。
上面很多,但其实就 2 步:
-
生成合成视网膜底片图像前需要进行的GAN训练步骤,这是为了让生成器学会如何从潜在空间产生新图像,这些图像在视觉上与真实的视网膜底片图像相似。
-
一旦GAN训练完成,就进行潜在空间优化,以确保新生成的图像在保护隐私的同时,仍然具有临床应用所需的特征。
使用PLAN方法生成视网膜图像可以比作一种“照相术”:
-
拍摄准备(GAN训练):想象一下你有一个非常先进的相机(GAN模型),这个相机可以学习怎样拍摄出看起来像真实视网膜的照片。
首先,你需要给这个相机展示很多真实的视网膜照片,让它学习这些照片的样子。
这个学习过程就像是在给相机“训练”。
-
拍摄技巧(潜在空间优化):现在相机已经学会了怎样拍出像真实视网膜的照片,接下来的问题是怎样在拍照时保护人们的隐私。
这就需要用到一些特殊的拍摄技巧:
- 保持多样性:确保每张照片都有点不同,不要让它们看起来太相似,就像不断改变拍摄角度和设置。
- 保护身份:用一个特殊的滤镜(身份分类器),确保照片中的人无法被识别。
- 确保准确性:即使使用滤镜,也要确保照片中的重要特征(如视网膜的医学特征)被保留下来。
-
生成照片(生成合成样本):通过这些技巧,相机现在可以生成既看起来像真实视网膜又不会泄露个人信息的照片了。
-
实际应用:这些生成的照片可以被用于各种目的,比如帮助医生学习如何诊断眼病,而不必担心泄露病人的隐私信息。
总结
-
问题:如何生成与真实视网膜图像相似但不泄露个人隐私的图像?
- 解法:GAN训练
- 原因:GAN能够学习和模仿真实视网膜图像的分布特征。
-
问题:在生成图像的同时,如何确保不泄露任何个人的特定特征?
- 解法:身份分类器
- 原因:身份分类器能够识别和隔离与个体身份相关的特征,减少泄露隐私的风险。
-
问题:如何保证生成的视网膜图像在医学上有用,即保持必要的医学特征?
- 解法:辅助分类器
- 原因:辅助分类器能够确保合成图像保留与视网膜图像分类相关的医学特征。
-
问题:如何在潜在空间中安全导航以生成多样化且隐私安全的样本?
- 解法:潜在空间优化
- 原因:通过在潜在空间中优化特定轨迹,可以控制生成样本的多样性和隐私安全性。
-
问题:在优化过程中,如何量化和平衡不同的目标,例如样本多样性、隐私安全性和类别准确性?
- 解法:总损失函数
- 原因:通过结合等距离损失、身份损失和类别一致性损失,可以量化并平衡这些目标。
特征组成:
- 特征1:GAN的能力在于学习和模仿真实数据的分布。
- 特征2:身份分类器的关键在于能隔离与个人身份相关的特征。
- 特征3:辅助分类器的作用是保持生成图像的医学相关性。
- 特征4:潜在空间优化允许精确控制生成样本的特性。
- 特征5:总损失函数是多目标优化过程的量化和平衡工具。
PLAN方法 = GAN的学习能力 + 身份分类器的隔离特征 + 辅助分类器的医学保持能力 + 潜在空间优化的控制能力 + 总损失函数的平衡能力。
这篇关于PLAN方法:解决 GAN 生成医学图像 Latent 空间中的隐私保护方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





