本文主要是介绍java eazyexcel 实现excel的动态多级联动下拉列表(1)使用名称管理器+INDIRECT函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原理
- 将数据源放到一个新建的隐藏的sheet中
- 将选项的子选项的对应字典设置到名称管理器中(名称是当前选项的内容,值是他对应的子菜单的单元格范围,在1里面的sheet中)
- 子菜单的数据根据INDIRECT函数去左边那个单元格获取内容,根据内容去名称管理器中获取字典的key,也就是子菜单的单元格范围
- 使用方式只需要构建CascadeCellBO对象即可,定义级联初始位置和行数,还有选项列表nameCascadeList,他的结构很简单就是name和子nameCascadeList。代码会自动扫描出最深的子菜单层数,根据这个层数构建下拉的个数
优缺点
优点
选项的个数和内容的个数不限制
缺点
- 因为excel的名称管理器的名称有很多限制比如不支持特殊字符、不支持括号、不能数字开头等等,所以选项的内容也会有这些限制
- 因为excel的名称管理器的名称不能相同,所有如果有两个相同二级菜单在不同的一级菜单中,那这两个二级菜单的三级菜单会是一样的
总之使用名称管理器+INDIRECT函数实现的级联下拉列表,只能做一些简单的数据,如果想克服那些缺点,需要用另一种方式,请看下篇文章
代码
import lombok.Data;import java.util.List;/*** @date 2024-01-19 21:05*/
@Data
public class CascadeCellBO {/*** 初始的行*/private int rowIndex;/*** 初始的列*/private int colIndex;/*** 行数*/private int rowNum;/*** 选项*/private List<NameCascadeBO> nameCascadeList;
}import lombok.Data;import java.util.List;/*** @date 2024-01-20 10:26*/
@Data
public class NameCascadeBO {/*** 名称*/private String name;/*** 子选项*/private List<NameCascadeBO> nameCascadeList;
}
import com.alibaba.excel.write.handler.SheetWriteHandler;
import com.alibaba.excel.write.metadata.holder.WriteSheetHolder;
import com.alibaba.excel.write.metadata.holder.WriteWorkbookHolder;
import lombok.Data;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellRangeAddressList;import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.IntStream;@Data
public class CascadeWriteHandler implements SheetWriteHandler {private final String dataSourceName;private final CascadeCellBO cascadeCellBO;public CascadeWriteHandler(CascadeCellBO cascadeCellBO) {this.cascadeCellBO = cascadeCellBO;this.dataSourceName = "dataSource" + System.currentTimeMillis();}@Overridepublic void beforeSheetCreate(WriteWorkbookHolder writeWorkbookHolder, WriteSheetHolder writeSheetHolder) {}@Overridepublic void afterSheetCreate(WriteWorkbookHolder writeWorkbookHolder, WriteSheetHolder writeSheetHolder) {//获取工作簿Sheet sheet = writeSheetHolder.getSheet();Workbook book = writeWorkbookHolder.getWorkbook();//创建一个专门用来存放地区信息的隐藏sheet页//因此不能在现实页之前创建,否则无法隐藏。Sheet hideSheet = book.createSheet(dataSourceName);book.setSheetHidden(book.getSheetIndex(hideSheet), true);// 将具体的数据写入到每一行中,每行的第一个单元格为父级区域的值,后面是子区域。List<NameCascadeBO> nameCascadeList = cascadeCellBO.getNameCascadeList();if (nameCascadeList == null || nameCascadeList.isEmpty()) {return;}Row row = hideSheet.createRow(0);IntStream.range(0, nameCascadeList.size()).forEach(i ->row.createCell(i).setCellValue(nameCascadeList.get(i).getName()));// 大类规则int colIndex = cascadeCellBO.getColIndex();int firstRowIndex = cascadeCellBO.getRowIndex();int lastRowIndex = firstRowIndex + cascadeCellBO.getRowNum();///开始设置(大类小类)下拉框DataValidationHelper dvHelper = sheet.getDataValidationHelper();CellRangeAddressList expRangeAddressList = new CellRangeAddressList(firstRowIndex, lastRowIndex, colIndex, colIndex);String bigEndCol = colIndex2Str(nameCascadeList.size());DataValidationConstraint bigFormula = dvHelper.createFormulaListConstraint("=" + dataSourceName + "!$A$1:$" + bigEndCol + "$1");setValidation(sheet, dvHelper, bigFormula, expRangeAddressList, "提示", "你输入的值未在备选列表中,请下拉选择合适的值");// 小类规则(各单元格按个设置)// "INDIRECT($A$" + 2 + ")" 表示规则数据会从名称管理器中获取key与单元格 A2 值相同的数据,如果A2是浙江省,那么此处就是浙江省下面的市// 为了让每个单元格的公式能动态适应,使用循环挨个给公式。// 循环几次,就有几个单元格生效,次数要和上面的大类影响行数一一对应,要不然最后几个没对上的单元格实现不了级联AtomicInteger rowId = new AtomicInteger(1);buildName(book, hideSheet, nameCascadeList, rowId);int maxLevel = getMaxLevel(nameCascadeList, 0);for (int num = 1; num < maxLevel; num++) {String start = colIndex2Str(colIndex + num);String preStart = "$" + start + "$";for (int i = firstRowIndex; i <= lastRowIndex; i++) {CellRangeAddressList rangeAddressList = new CellRangeAddressList(i, i, colIndex + num, colIndex + num);DataValidationConstraint formula = dvHelper.createFormulaListConstraint("INDIRECT(" + preStart + (i + 1) + ")");setValidation(sheet, dvHelper, formula, rangeAddressList, "提示", "你输入的值未在备选列表中,请下拉选择合适的值");}}}// 添加名称管理器private void buildName(Workbook book, Sheet hideSheet, List<NameCascadeBO> nameCascadeList, AtomicInteger rowId) {Optional.ofNullable(nameCascadeList).ifPresent(l -> l.forEach(nameCascadeBO -> {List<NameCascadeBO> childList = nameCascadeBO.getNameCascadeList();if (childList != null && !childList.isEmpty()) {Row row = hideSheet.createRow(rowId.getAndIncrement());row.createCell(0).setCellValue(nameCascadeBO.getName());IntStream.range(0, childList.size()).forEach(c ->row.createCell(c + 1).setCellValue(childList.get(c).getName()));// 添加名称管理器String endCol = colIndex2Str(1 + childList.size());String range = "$B$" + rowId.get() + ":$" + endCol + "$" + rowId.get();Name name = book.createName();name.setNameName(nameCascadeBO.getName());name.setRefersToFormula(dataSourceName + "!" + range);buildName(book, hideSheet, childList, rowId);}}));}private int getMaxLevel(List<NameCascadeBO> nameCascadeList, int preLevel) {int curLevel = preLevel + 1;int maxLevel = curLevel;for (NameCascadeBO nameCascadeBO : nameCascadeList) {List<NameCascadeBO> childList = nameCascadeBO.getNameCascadeList();if (childList != null && !childList.isEmpty()) {int level = getMaxLevel(childList, curLevel);maxLevel = Math.max(level, maxLevel);}}return maxLevel;}/*** 设置验证规则** @param sheet sheet对象* @param helper 验证助手* @param constraint createExplicitListConstraint* @param addressList 验证位置对象* @param msgHead 错误提示头* @param msgContext 错误提示内容*/private void setValidation(Sheet sheet, DataValidationHelper helper, DataValidationConstraint constraint, CellRangeAddressList addressList, String msgHead, String msgContext) {DataValidation dataValidation = helper.createValidation(constraint, addressList);dataValidation.setErrorStyle(DataValidation.ErrorStyle.STOP);dataValidation.setShowErrorBox(true);dataValidation.setSuppressDropDownArrow(true);dataValidation.createErrorBox(msgHead, msgContext);sheet.addValidationData(dataValidation);}public static String colIndex2Str(int column) {if (column <= 0) {return null;}String columnStr = "";column--;do {if (columnStr.length() > 0) {column--;}columnStr = ((char) (column % 26 + (int) 'A')) + columnStr;column = (int) ((column - column % 26) / 26);} while (column > 0);return columnStr;}
}使用
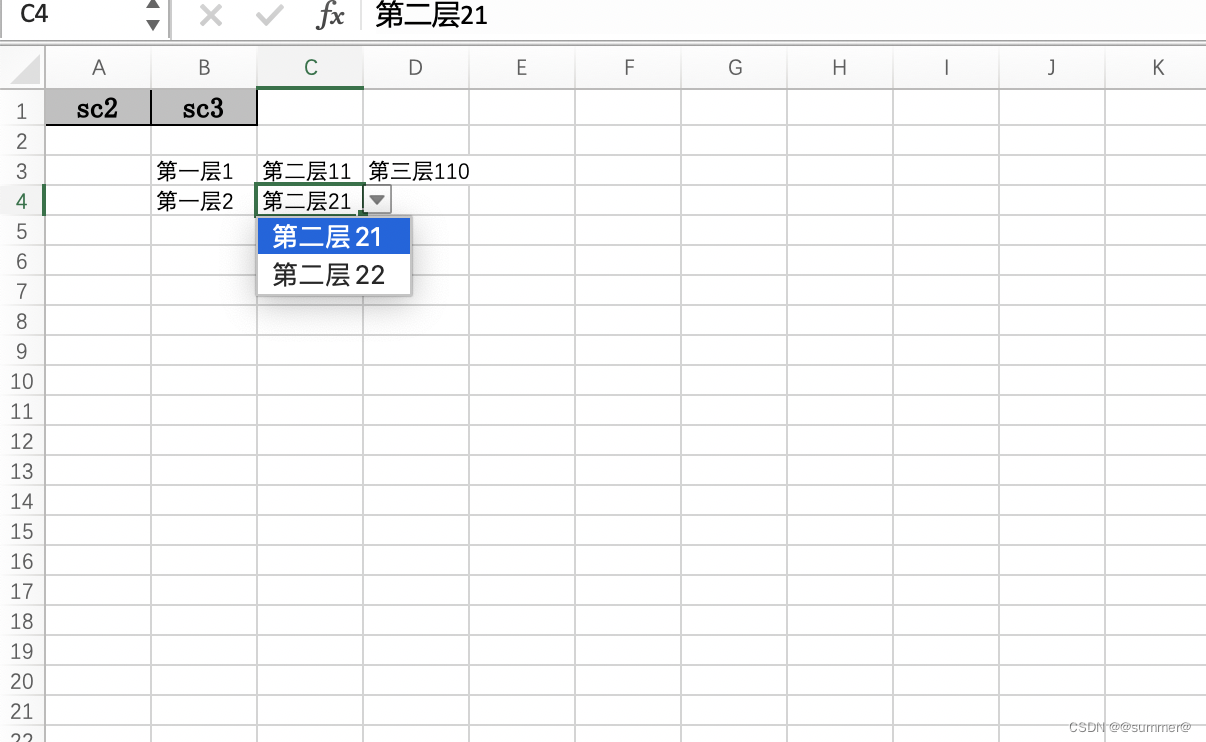
public static void main(String[] args) {List<List<String>> header = new ArrayList<>();header.add(Arrays.asList( "sc2"));header.add(Arrays.asList( "sc3"));int colIndex = header.size() - 1;List<NameCascadeBO> nameCascadeList = new ArrayList<>();NameCascadeBO nameCascadeBO = new NameCascadeBO();nameCascadeBO.setName("第一层1");List<NameCascadeBO> nameCascadeList2 = new ArrayList<>();NameCascadeBO nameCascadeBO2 = new NameCascadeBO();nameCascadeBO2.setName("第二层11");List<NameCascadeBO> nameCascadeList3 = new ArrayList<>();IntStream.range(0, 400).forEach(i -> {NameCascadeBO nameCascadeBO3 = new NameCascadeBO();nameCascadeBO3.setName("第三层11" + i);nameCascadeList3.add(nameCascadeBO3);});nameCascadeBO2.setNameCascadeList(nameCascadeList3);nameCascadeList2.add(nameCascadeBO2);nameCascadeBO2 = new NameCascadeBO();nameCascadeBO2.setName("第二层12");nameCascadeList2.add(nameCascadeBO2);nameCascadeBO.setNameCascadeList(nameCascadeList2);nameCascadeList.add(nameCascadeBO);nameCascadeBO = new NameCascadeBO();nameCascadeBO.setName("第一层2");nameCascadeList2 = new ArrayList<>();nameCascadeBO2 = new NameCascadeBO();nameCascadeBO2.setName("第二层21");nameCascadeList2.add(nameCascadeBO2);nameCascadeBO2 = new NameCascadeBO();nameCascadeBO2.setName("第二层22");nameCascadeList2.add(nameCascadeBO2);nameCascadeBO.setNameCascadeList(nameCascadeList2);nameCascadeList.add(nameCascadeBO);IntStream.range(2, 200).forEach(i -> {NameCascadeBO item = new NameCascadeBO();item.setName("第一层" + i);nameCascadeList.add(item);});CascadeCellBO cascadeCellBO = new CascadeCellBO();cascadeCellBO.setRowIndex(2);cascadeCellBO.setRowNum(10);cascadeCellBO.setColIndex(colIndex);cascadeCellBO.setNameCascadeList(nameCascadeList);CascadeWriteHandler cascadeWriteHandler = new CascadeWriteHandler(cascadeCellBO);ByteArrayOutputStream outputStream = new ByteArrayOutputStream();EasyExcelFactory.write(outputStream).head(header).registerWriteHandler(cascadeWriteHandler).sheet("导入信息").doWrite(new ArrayList<>());FileUtils.save2File("/Users/admin/aa/导入模板.xlsx", outputStream.toByteArray());}


这篇关于java eazyexcel 实现excel的动态多级联动下拉列表(1)使用名称管理器+INDIRECT函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






