本文主要是介绍基于PiflowX构建MySQL和Postgres的Streaming ETL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:案例来自flink cdc官方。[[基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL](基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL — CDC Connectors for Apache Flink® documentation (ververica.github.io))]
这篇文章将演示如何基于PiflowX快速构建 MySQL和Postgres的流式ETL。本教程的演示都将在WEB画布中进行,只需拖拉拽,无需一行Java/Scala代码,也无需安装IDE。
案例背景
假设我们正在经营电子商务业务,商品和订单的数据存储在MySQL中,订单对应的物流信息存储在Postgres中。 对于订单表,为了方便进行分析,我们希望让它关联上其对应的商品和物流信息,构成一张宽表,并且实时把它写到ElasticSearch中。
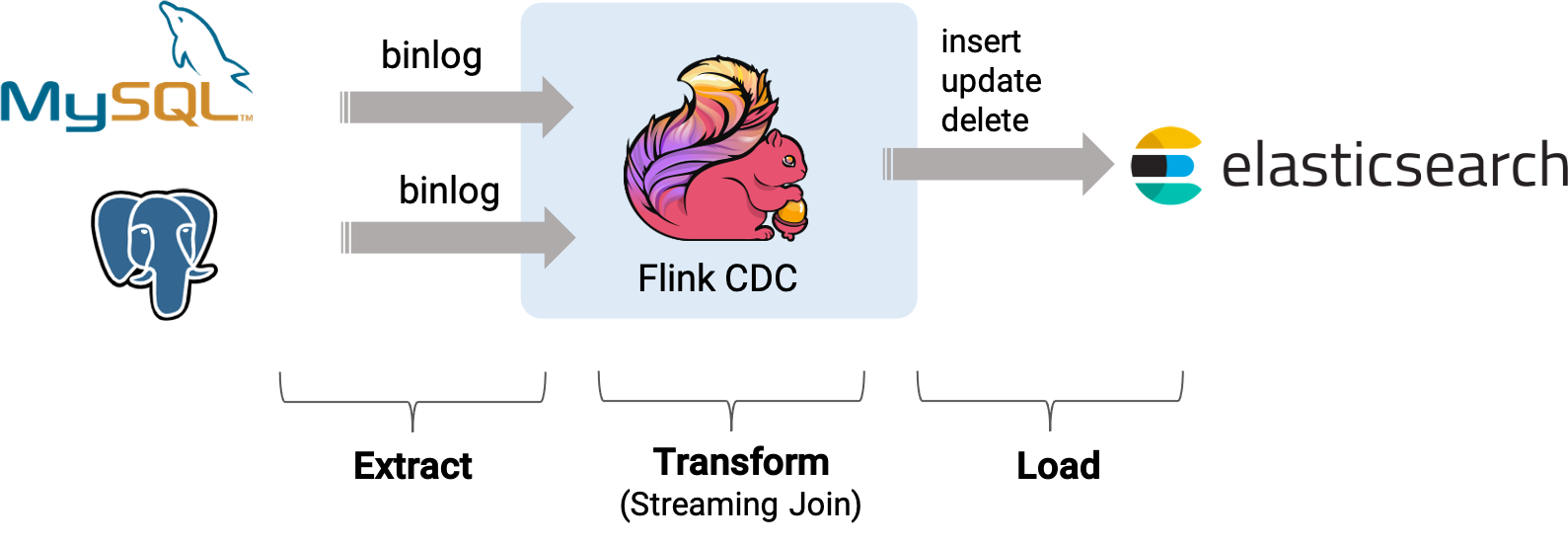
接下来的内容将介绍如何使用 PiflowX 来实现这个需求,系统的整体架构如下图所示(图片来自原官方文章内容,PiflowX底层流程亦是如此):
组件准备
演示场景组件使用官方提供的docker-compose的文件准备所需要的组件,由于笔记本资源有限,结果直接使用PiflowX的ShowChangelog组件打印在控制台,elasticsearch和kibana组件就去除了。
version: '2.1'
services:postgres:image: debezium/example-postgres:1.1ports:- "5432:5432"environment:- POSTGRES_DB=postgres- POSTGRES_USER=postgres- POSTGRES_PASSWORD=postgresmysql:image: debezium/example-mysql:1.1ports:- "3306:3306"environment:- MYSQL_ROOT_PASSWORD=123456- MYSQL_USER=mysqluser- MYSQL_PASSWORD=mysqlpw
该Docker Compose中包含的容器有:
-
MySQL: 商品表
products和订单表orders将存储在该数据库中, 这两张表将和 Postgres 数据库中的物流表shipments进行关联,得到一张包含更多信息的订单表enriched_orders; -
Postgres: 物流表
shipments将存储在该数据库中。Mysql中创建数据库和表
products,orders,并插入数据
-- MySQL
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),(default,"car battery","12V car battery"),(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),(default,"hammer","12oz carpenter's hammer"),(default,"hammer","14oz carpenter's hammer"),(default,"hammer","16oz carpenter's hammer"),(default,"rocks","box of assorted rocks"),(default,"jacket","water resistent black wind breaker"),(default,"spare tire","24 inch spare tire");CREATE TABLE orders (order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,order_date DATETIME NOT NULL,customer_name VARCHAR(255) NOT NULL,price DECIMAL(10, 5) NOT NULL,product_id INTEGER NOT NULL,order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
在Postgres数据库中准备数据
-- PG
CREATE TABLE shipments (shipment_id SERIAL NOT NULL PRIMARY KEY,order_id SERIAL NOT NULL,origin VARCHAR(255) NOT NULL,destination VARCHAR(255) NOT NULL,is_arrived BOOLEAN NOT NULL
);
ALTER SEQUENCE public.shipments_shipment_id_seq RESTART WITH 1001;
ALTER TABLE public.shipments REPLICA IDENTITY FULL;
INSERT INTO shipments
VALUES (default,10001,'Beijing','Shanghai',false),(default,10002,'Hangzhou','Shanghai',false),(default,10003,'Shanghai','Hangzhou',false);
使用PiflowX创建工作流
登录PiflowX系统
创建流水线任务
设计流水线任务
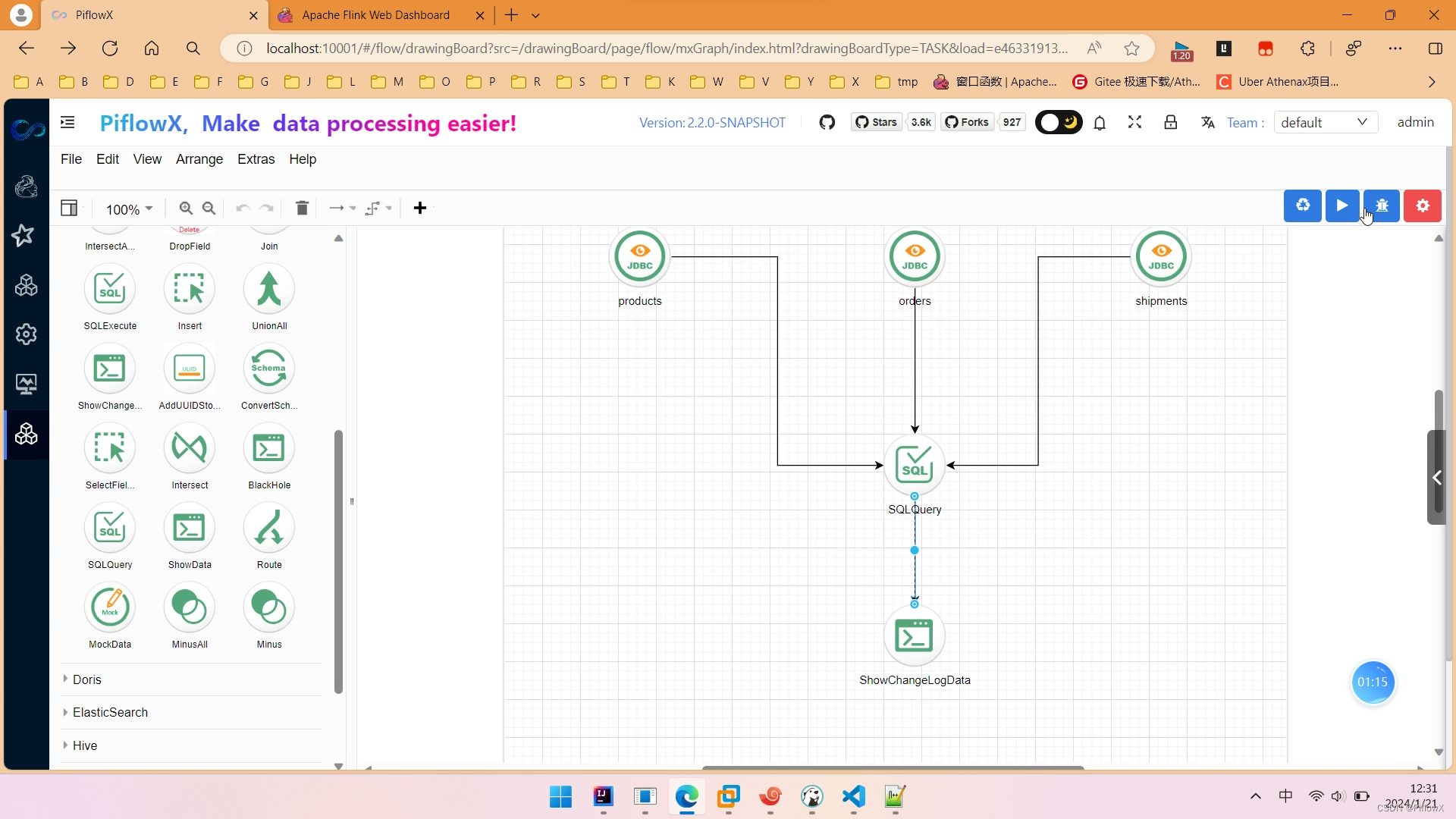
拖入MysqlCdC组件到画布中,命名为products,对应mysql数据库中的产品表products,填写节点参数。
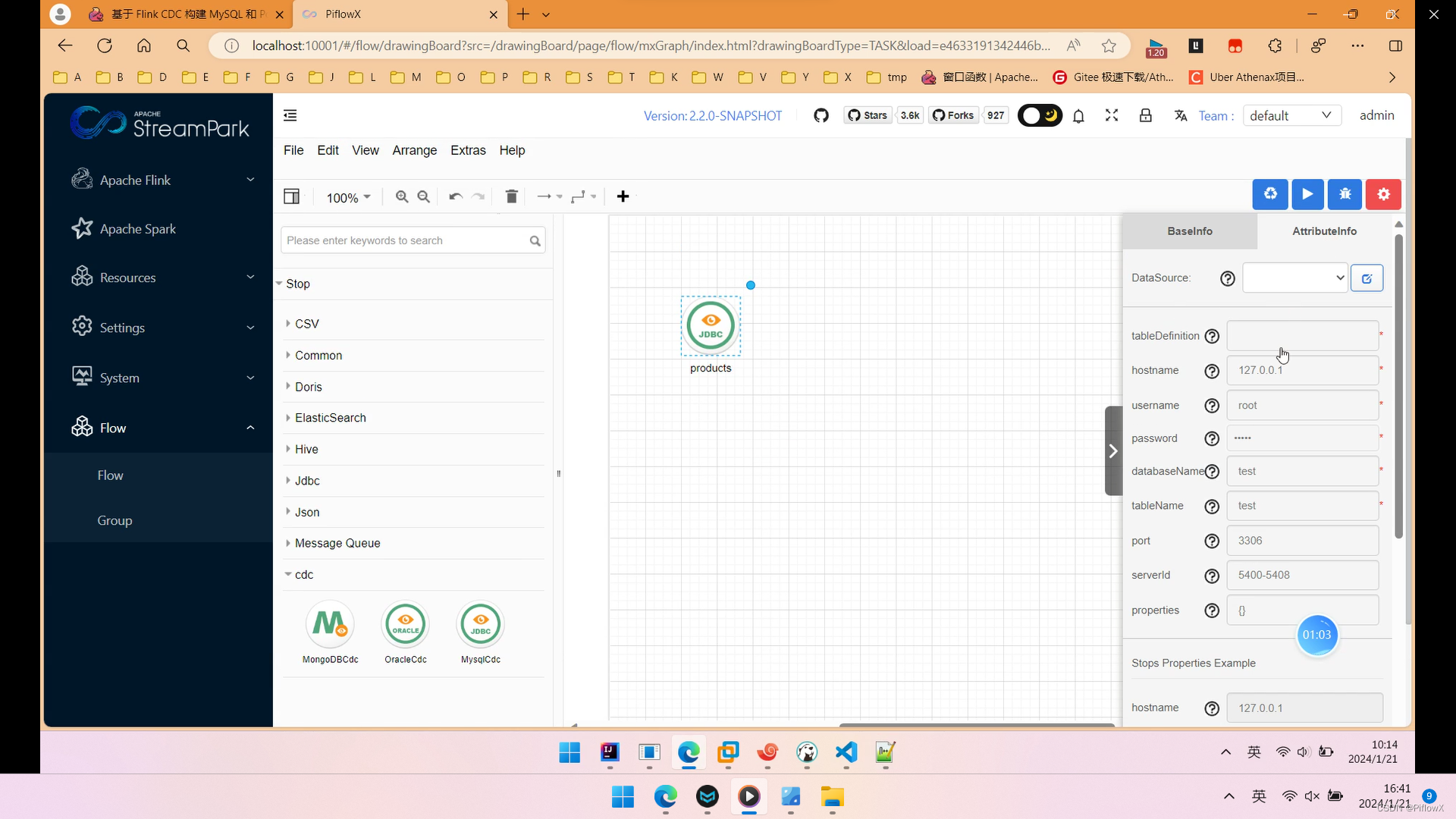
products节点生成的flink sql如下:
CREATE TABLE products (id INT,name STRING,description STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = '192.168.186.102','port' = '3306','username' = 'root','password' = '123456','database-name' = 'mydb','table-name' = 'products');
再拖入一个MysqlCdC组件到画布中,命名为orders,对应mysql中的订单表orders,填写节点参数。
products节点生成的flink sql如下:
CREATE TABLE orders (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = '192.168.186.102','port' = '3306','username' = 'root','password' = '123456','database-name' = 'mydb','table-name' = 'orders');
拖入PostgresCdc组件,命名为shipments,对应PostgresSQL数据库中的物流表shipments。
shipments节点生成的flink sql如下:
CREATE TABLE shipments (shipment_id INT,order_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (shipment_id) NOT ENFORCED) WITH ('connector' = 'postgres-cdc','hostname' = '192.168.186.102','port' = '5432','username' = 'postgres','password' = 'postgres','database-name' = 'postgres','schema-name' = 'public','table-name' = 'shipments','slot.name' = 'flink');
到此,我们使用SqlQuery组件,实现我们需要的Streaming ETL。
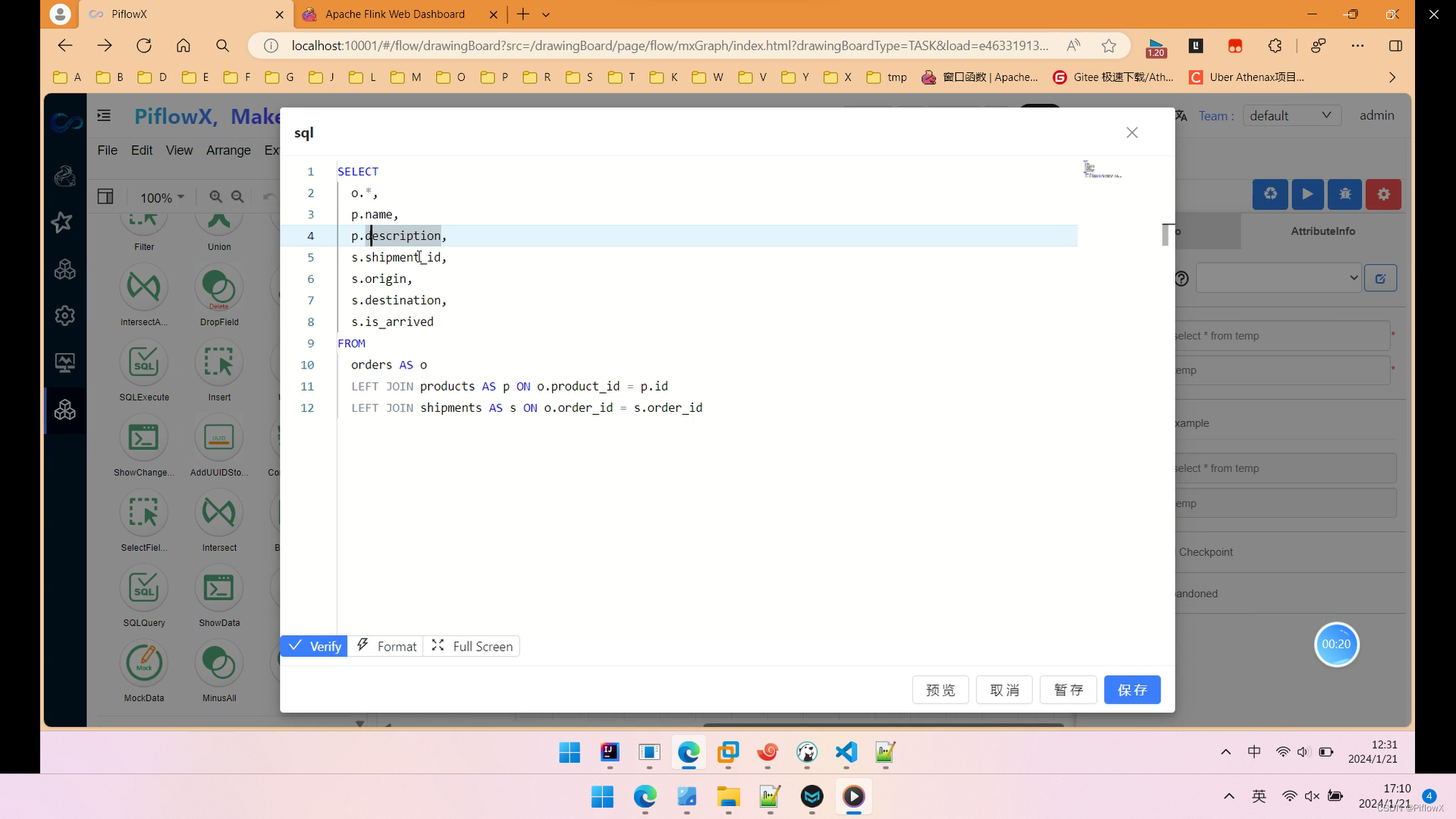
加工逻辑如图所示,我们使用简单的join将3张表关联起来。
最后,拖入ShowChangelog组件,方便我们查看数据。最终工作流如图所示。点击运行按钮,提交任务到flink。
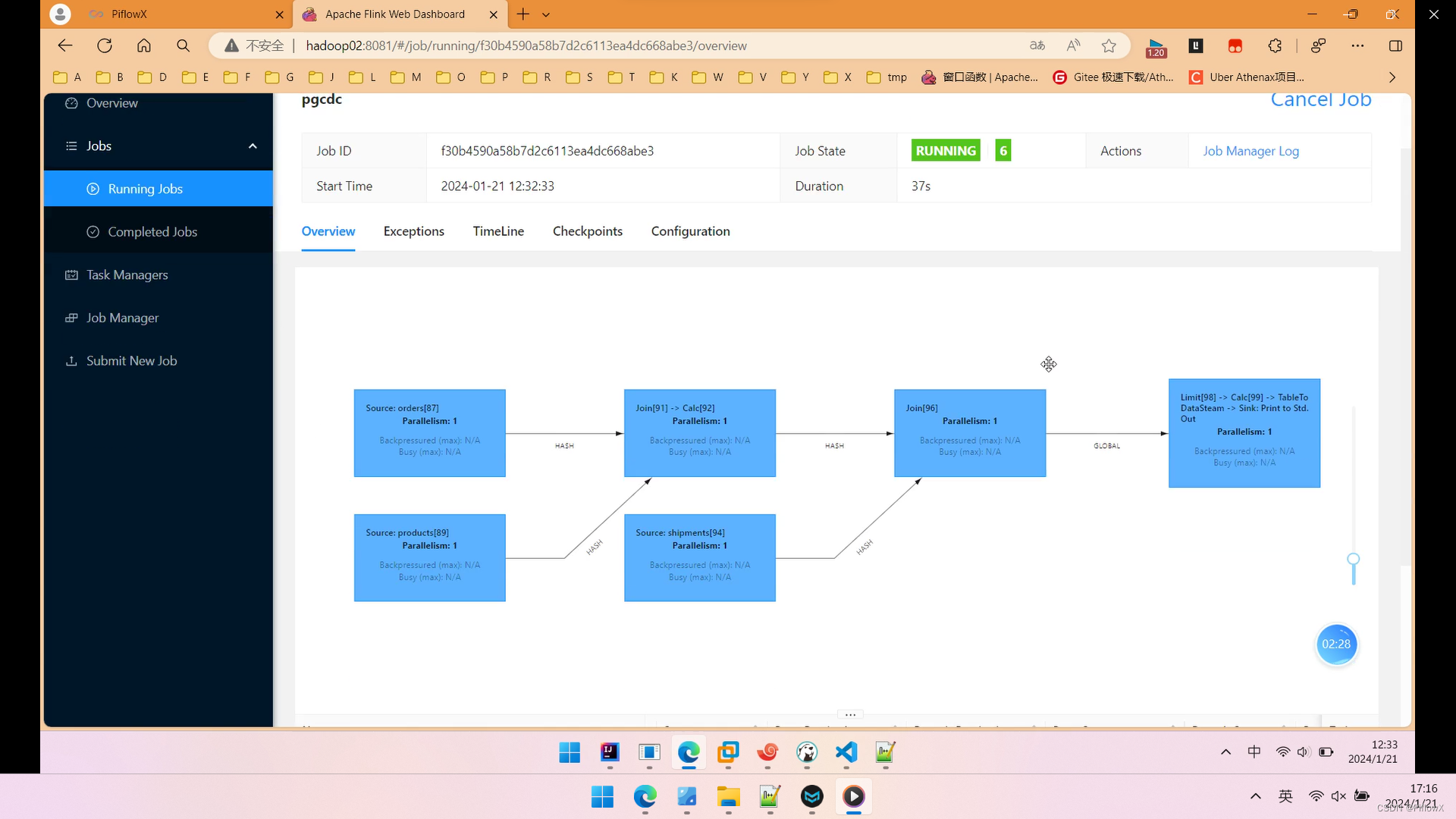
进入flink web ui,查看运行任务。
查看控制台日志,可以看到加工后的宽表数据成功打印出来。
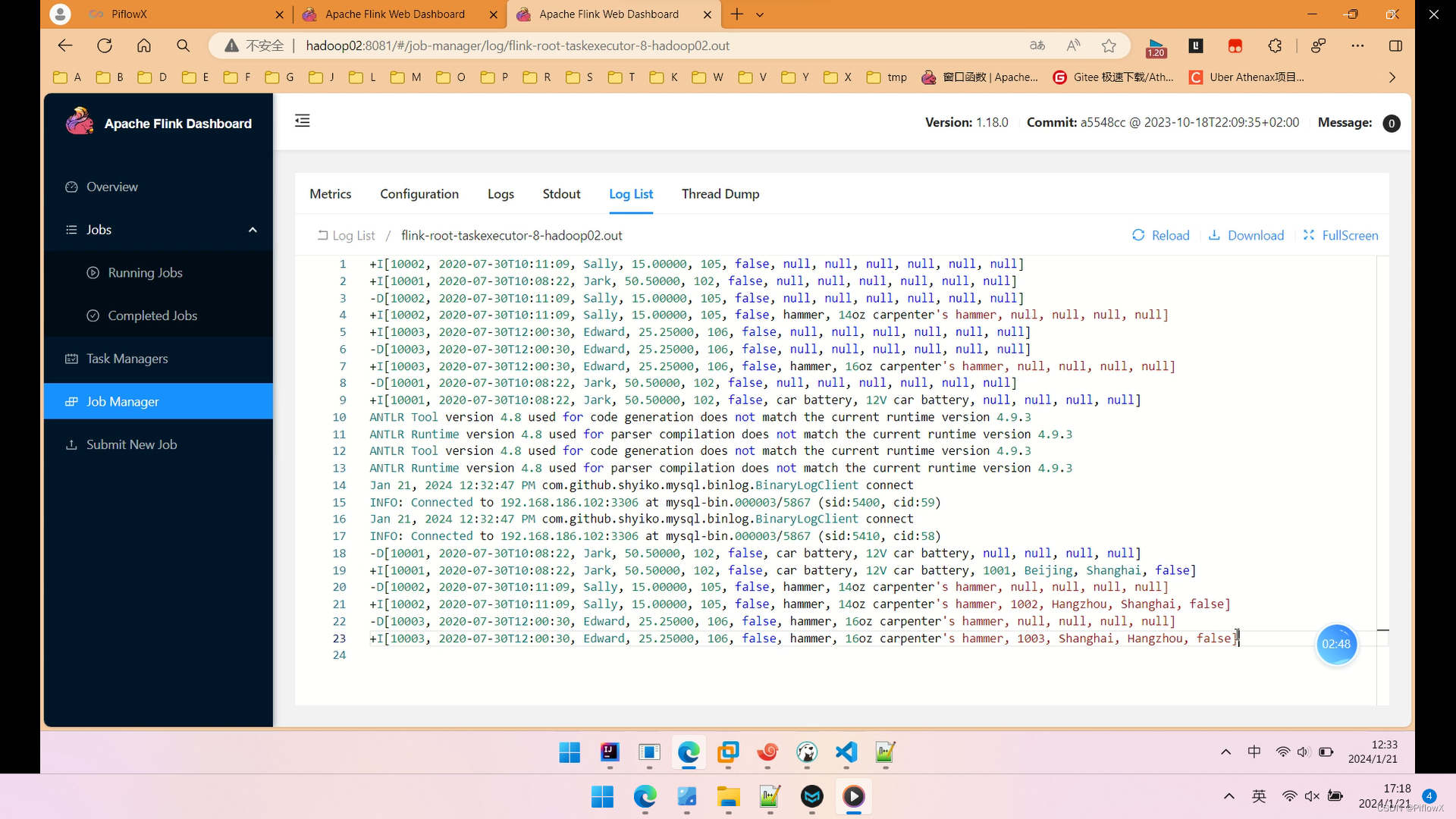
接下来,我们执行增删改的操作,看看flink能够实时捕获到数据库变更。
在MySQL的orders表中插入一条数据:
--MySQL
INSERT INTO orders
VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);
在Postgres的shipment表中插入一条数据:
--PG
INSERT INTO shipments
VALUES (default,10004,'Shanghai','Beijing',false);
再来观察flink控制台输出:

可以看到,控制台成功的将新增后的记录,实时捕获并更新。删除和更新就不截图说明了,完整演示可以观看下方视频
基于 PiflowX构建 MySQL 和 Postgres 的 Streaming ETL
这篇关于基于PiflowX构建MySQL和Postgres的Streaming ETL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






