本文主要是介绍剖析 | torch.cumsum维度详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近看别人代码的时候看到这么一个函数,一看吧,感觉是个求和的函数,毕竟有sum这种,可能性还是比较大,于是准备深入看看,具体是干嘛的。
1.写法。先不管结果如何,代码得先写出来。
函数原型:
torch.cumsum(input, dim, *, dtype=None, out=None) → Tensor返回维度dim中输入元素的累计和。【功能:累加】
例如,如果输入是大小为N的向量,则结果也将是大小为N的带有元素的向量。【运算后维度不变】

说明必须要有两个参数,一个是tensor类型的输入,也就是数据,另外一个是操作的维度,这也是今天的核心,很多人在维度上是不理解的,或者说是混淆的。
第一种写法(官网):
torch.cumsum(input, dim=?)第二种写法(代码中看到的写法):
b = input.cumsum(dim=?)大概的写法就这两种,主要分析下维度是如何计算的。采用官网的写法来测试一下,一般维度就三维算高的了,所以我就测试了一维、二维和三维数据时候的效果。
一维数据:
x1 = torch.arange(0, 6)
print(x1)
y1 = torch.cumsum(x1, dim=0)
print(y1)
y2 = torch.cumsum(x1, dim=-1)
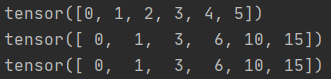
print(y2)运行结果:
结果分析:
y1(dim=0)的结果是:第一列不变,后面的列依次在上一列基础上加上自身的数。
第1列,值0,不变,和为本身,即:0;
第2列,值1,累加前一列值0,和为:0+1=1
第3列,值2,累加前一列值1,和为:1+2=3
第4列,值3,累加前一列值3,和为:3+3=6
第5列,值4,累加前一列值6,和为:6+4=10
第6列,值5,累加前一列值10,和为:10+5=15
y2(dim=-1)的结果和y1的结果一致。这是为什么嘞?一维数据的规模结果就只有一个数,这里算出来就是6,dim=0,指的是列不变,dim=-1也是指的列不变。
![]()
可以想象成一个循环圈,本来只有一个数据dim=0,但是由于方向可以反向,于是出现了dim=-1,既然到了头部0都还要减去1,那就到了尾部,这里一维数据很特殊,头部和尾部都是dim=0,所以dim=-1和dim=0就是一样的了,于是运行结果一致了。
二维数据:
a1 = torch.arange(0, 6).view(2, 3)
print(a1)
b1 = torch.cumsum(a1, dim=0)
c1 = torch.cumsum(a1, dim=1)
d1 = torch.cumsum(a1, dim=-1)
print(b1)
print(c1)
print(d1)运行结果:

结果分析:
二维数据的规模结果有两个数,第一个表示行数,第二个表示列数。这里是一个2行3列的二维数据,dim=0,指的是行不变,dim=1表示列不变。
b1(dim=0)的计算过程:行不变,指的是第一行不变,后面的行依次累加。
第一行,0,1,2,值不变,计算结果就是0,1,2
第二行,3,4,5,与上一行值累加,这里是对应位置的相加,所以就是:0+3,1+4,2+5,结果是3,5,7
综合计算结果就是运行结果中的第二个tensor效果。
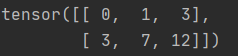
c1(dim=1)的计算结果:列不变,指的是第一列不变,后面的列依次累加
第一列:0,3,值不变,计算结果就是0,3
第二列,1,4,累加前一列,0+1,3+4,所以计算结果是1,7
第三列,2,5,累加前一列,1+2,7+5,所以计算结果是3,12
所以运行结果是:
d1(dim=-1),从运行结果可以看出,计算结果和dim=1的结果一致,这是什么原因嘞?其实有了一维数据的分析,大家可以猜测出来是为什么了,还是画个图理解一下:
![]()
二维数据规模中有两个数据,第一个表示行,第二个表示列,所以dim=0表示第一行值不变,后边的行依次累加,dim=1则是第一列不变,后面的列依次累加。dim=-1也就是说在dim=0的前面的维度,根据循环,0的前面没有了,所以dim=-1就等价于了dim=1,所以运行结果和c1和d1是一样的。是不是有点感觉了?接下来分析三维数据。
三维数据:
q1 = torch.arange(0, 16).view(2, 2, 4)
print(q1)
w1 = torch.cumsum(q1, dim=0)
e1 = torch.cumsum(q1, dim=1)
r1 = torch.cumsum(q1, dim=2)
t1 = torch.cumsum(q1, dim=-1)
print(w1)
print(e1)
print(r1)
print(t1)运行结果:

三维数据运行结果看起来有点多,我标记了一下。
结果分析:
三维数据规模计算后有三个数据,我们可以理解为层、行、列。这里的规模是:2,2,4,表示2层,2行,4列的数据。
w1(dim=0)表示层不变,也就是第一层不变,后面的层依次累加。这里一共就2层,第一层不变,那就只需要计算第二层就可以了。
第一层数据:
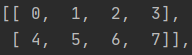 ,由于第一层值不变,所以不管了,结果就是原始的样子
,由于第一层值不变,所以不管了,结果就是原始的样子
第二层数据:
 ,需要累加上上一层的数据,对应位置相加,则就是0+8,1+9,2+10,3+11;4+12,5+13,6+14,7+15,所以计算结果是:
,需要累加上上一层的数据,对应位置相加,则就是0+8,1+9,2+10,3+11;4+12,5+13,6+14,7+15,所以计算结果是:
[[8,10,12,14],
[16,18,20,22]]
两层综合起来就是计算结果了,也就是运行结果中2表示的样子。
e1(dim=1)表示行不变,也就是第一行不变,后面的行依次累加,这里一共2层,每层有两行,所以,这每层中的手行都不变,也就是圈红的部分不变,
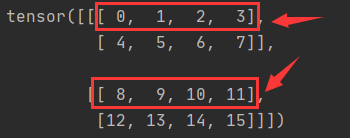
然后后面的行依次累加,也就是:0+4,1+5,2+6,3+7;8+12,9+13,10+14,11+15,也就是4,6,8,10;20,22,24,26,前四个计算出来为第一层的第二行,后四个为第二层的第二行数据,综合起来就是运行结果中3表示的样子.
r1(dim=2)表示列不变,后面的列依次累加,这里也标记一下不变的位置
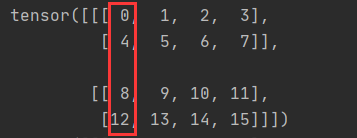
后面的列依次累加,所以就计算出了运行结果中的4表示样子.
至于t1(dim=-1)为什么和r1效果一致,能自己弄明白了不?三维数据的规模中有三个数,层、行、列,从层开始编号,依次是0,1,2。那么-1就是说在0的前面的维度,根据循环,-1是不是就是指的是2啊,所以dim=-1和dim=2的运行结果是一致的,这里我也放一个图,大家感悟一下吧。
![]()
最开始,我喜欢死记硬背,到底是dim=0是行还是列,现在终于找到规律了,实际上还是比较容易理解。
参考:
官网对函数的解释:https://pytorch.org/docs/stable/generated/torch.cumsum.html?highlight=cumsum#torch.cumsum
这篇关于剖析 | torch.cumsum维度详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!