本文主要是介绍深度学习——苹果新鲜度识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本项目使用yolov8模型作为目标检测的模型
目录
项目背景:
一、项目需求:
二、项目实现:
(一)流程介绍:
1、YOLOv8环境配置:
(二)、训练数据集的准备工作
1、准备好数据集:
2、划分数据集
3、训练模型
4、预测模型
三、检测结果与思考:
1、训练阶段:
2、训练结束:
训练过程视频:
四、知识体系:
(一)、网络定义:
(二)、输出定义:
(三)、Loss函数定义:
五、模型结构设计
六、模型推理过程
七、小总结:
项目背景:
近年来,随着全球经济的发展,水果消费市场规模不断扩大,水果种类也日益丰富。水果检测与识别技术在农业生产、仓储物流、超市零售等领域具有重要的应用价值。传统的水果检测与识别方法主要依赖于人工识别,这种方法在一定程度上受到人力成本、识别效率和准确性等方面的限制。因此,开发一种高效、准确的自动化水果检测与识别系统具有重要的研究意义和实际价值。
在本博文中,我们提出了一种基于深度学习的苹果新鲜度检测与识别系统,该系统采用YOLOv8算法对苹果进行检测和识别,实现对图片中的苹果进行准确识别。
一、项目需求:
对苹果外形进行检测与识别,系统将识别出图片中苹果的新鲜程度并显示相应的类别。
二、项目实现:
通过调研,本项目最终使用yolov8模型作为目标检测的模型, YOLOv8 旨在快速、准确且易于使用,使其成为广泛的物体检测、图像分割和图像分类任务的极佳选择。
(一)流程介绍:
1、YOLOv8环境配置:
首先去自己的anaconda的安装的envs(虚拟环境),在导航栏输入cmd,进入命令窗口。
确保python>=3.7;CUDA>=10.1,PYtorch>=1.7
(1)、创建一个虚拟环境
conda create -n torch1.12.1 python=3.8.8
(2)、激活刚建的虚拟环境
activate torch1.12.1
(3)、到官方网站下载yolo模型 ,下载好后解压,里面有个文件requirements.txt
https://github.com/ultralytics/ultralytics
安装一个整体包:
pip install -r .\requirements.txt
直接按照路径会有问题,找到自己 requirements.txt 文件路径,我这里是pip install -r D:\ultralytics-main\ultralytics-main\requirements.txt
(4)、然后安装ultralytics ,这是必须的。可以用镜像地址。
pip install ultralytics -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
(5)、安装下载好包,接下来就是验证:
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg' show=True save=True
(二)、训练数据集的准备工作
1、准备好数据集:
我们选择的苹果数据集包含图片数量978张

2、划分数据集
我们导出的数据文件结构
标签类别包含两类:fresh_apple和rotten_apple;
├── yolov8_dataset└── train└── images (folder including all training images)└── labels (folder including all training labels)└── test└── images (folder including all testing images)└── labels (folder including all testing labels)└── val└── images (folder including all testing images)└── labels (folder including all testing labels)划分数据集:
import os
import random
import shutil# 设置随机数种子
random.seed(123)# 定义文件夹路径
root_dir = 'Moon_Cake'
image_dir = os.path.join(root_dir, 'images', 'all')
label_dir = os.path.join(root_dir, 'labels', 'all')
output_dir = 'yolov8_dataset'# 定义训练集、验证集和测试集比例
train_ratio = 0.7
valid_ratio = 0.15
test_ratio = 0.15# 获取所有图像文件和标签文件的文件名(不包括文件扩展名)
image_filenames = [os.path.splitext(f)[0] for f in os.listdir(image_dir)]
label_filenames = [os.path.splitext(f)[0] for f in os.listdir(label_dir)]# 随机打乱文件名列表
random.shuffle(image_filenames)# 计算训练集、验证集和测试集的数量
total_count = len(image_filenames)
train_count = int(total_count * train_ratio)
valid_count = int(total_count * valid_ratio)
test_count = total_count - train_count - valid_count# 定义输出文件夹路径
train_image_dir = os.path.join(output_dir, 'train', 'images')
train_label_dir = os.path.join(output_dir, 'train', 'labels')
valid_image_dir = os.path.join(output_dir, 'valid', 'images')
valid_label_dir = os.path.join(output_dir, 'valid', 'labels')
test_image_dir = os.path.join(output_dir, 'test', 'images')
test_label_dir = os.path.join(output_dir, 'test', 'labels')# 创建输出文件夹
os.makedirs(train_image_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(valid_image_dir, exist_ok=True)
os.makedirs(valid_label_dir, exist_ok=True)
os.makedirs(test_image_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)# 将图像和标签文件划分到不同的数据集中
for i, filename in enumerate(image_filenames):if i < train_count:output_image_dir = train_image_diroutput_label_dir = train_label_direlif i < train_count + valid_count:output_image_dir = valid_image_diroutput_label_dir = valid_label_direlse:output_image_dir = test_image_diroutput_label_dir = test_label_dir# 复制图像文件src_image_path = os.path.join(image_dir, filename + '.jpg')dst_image_path = os.path.join(output_image_dir, filename + '.jpg')shutil.copy(src_image_path, dst_image_path)# 复制标签文件src_label_path = os.path.join(label_dir, filename + '.txt')dst_label_path = os.path.join(output_label_dir, filename + '.txt')shutil.copy(src_label_path, dst_label_path)运行完后我们的数据集就会划分成这个格式了,现在数据准备工作就彻底完成了,接下来我们就可以开始着手训练模型。
这是划分数据集后的文件结构:

3、训练模型
dataset目录下为自己的数据集创建.yaml配置文件
里面写绝对路径:

4、预测模型
设置训练参数,迭代200次,训练次数为10次,开始训练
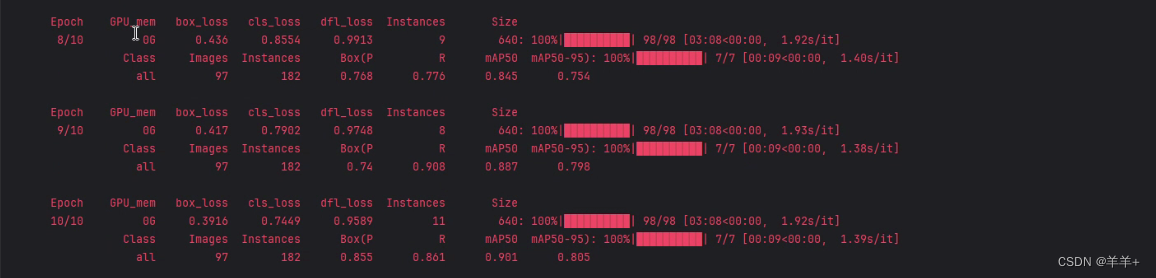
训练完成后,根目录下会产生一个run的文件夹,里面就存有训练好的结果

三、检测结果与思考:
我们使用精度和召回率等指标来评估模型的性能,还通过损失曲线和PR曲线来分析训练的过程。图中苹果的新鲜度和置信度值都标注出来了,预测速度较快。








1、训练阶段:
使用了YOLOv8算法对数据集训练,总计训练了200轮。在训练过程中,我们使用tensorboard(可视化tensorflow模型工具)记录了模型在训练集和验证集上的损失曲线。从下图可以看出,随着训练次数的增加,模型的训练损失和验证损失都逐渐降低,说明模型不断地学习到更加精准的特征

2、训练结束:
一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值。
我们对模型在测试集上进行了评估,得到了以下结果。下图展示了我们训练的YOLOv8模型在测试集上的PR曲线。可以看到,模型在不同类别上都取得了较高的召回率和精确率,我们的模型在验证集上的均值平均准确率为0.926。

训练过程视频:
苹果新鲜度识别-CSDN直播
四、知识体系:
(一)、网络定义:
YOLO检测网络包括24个卷积层和2个全连接层,其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
(二)、输出定义:
YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。
(三)、Loss函数定义:
YOLO使用均方和误差作为loss函数来优化模型参数,即网络输出的SS(B5 + C)维向量与真实图像的对应SS*(B*5 + C)维向量的均方和误差。
(四)、训练:
YOLO模型训练分为两步:
(1)预训练。使用ImageNet,1000类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
(2)在预训练中得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用VOC 20类标注数据进行YOLO模型训练。为提高图像精度,在训练检测模型时,将输入图像分辨率resize到448x448
五、模型结构设计

六、模型推理过程
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。
将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
有一个特别注意的点:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暂时没有开启,不清楚后面是否会开启,在 MMYOLO 中快速测试了下,如果开启 Batch shape 会涨大概 0.1~0.2。
七、小总结:
综上,我们训练的YOLOv8模型在苹果新鲜度检测数据集上表现良好,具有较高的检测精度,快速、准确的检测效果,可以在实际场景中应用。
这篇关于深度学习——苹果新鲜度识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




