本文主要是介绍【Apache Rocket】源码解析:消息消费源码解析(监听模式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
消费消息源码解析
1. Push模式消费源码解析
相比于生产者,消费者的代码要更为复杂一点,不过也不会太复杂,我们来逐一进行分解。RocketMQ的消费模式一般分为push模式和pull模式;push模式,又可以称为监听模式。
注意:push模式并不是Broker主动去push消息给客户端,本质上还是客户端去pull消息,只不过这个过程客户端是帮你做了而已。实际上还是在内部启了一个PullMessageServieScheduledThread线程专门去向Broker拉取消息。
2. Simple Demo
public static void main(String[] args) throws InterruptedException, MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("CID_JODIE_1");consumer.subscribe("TopicTest", "*");consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);//wrong time format 2017_0422_221800consumer.setConsumeTimestamp("20181109221800");consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});consumer.start();System.out.printf("Consumer Started.%n");
}
3. Consumer初始化
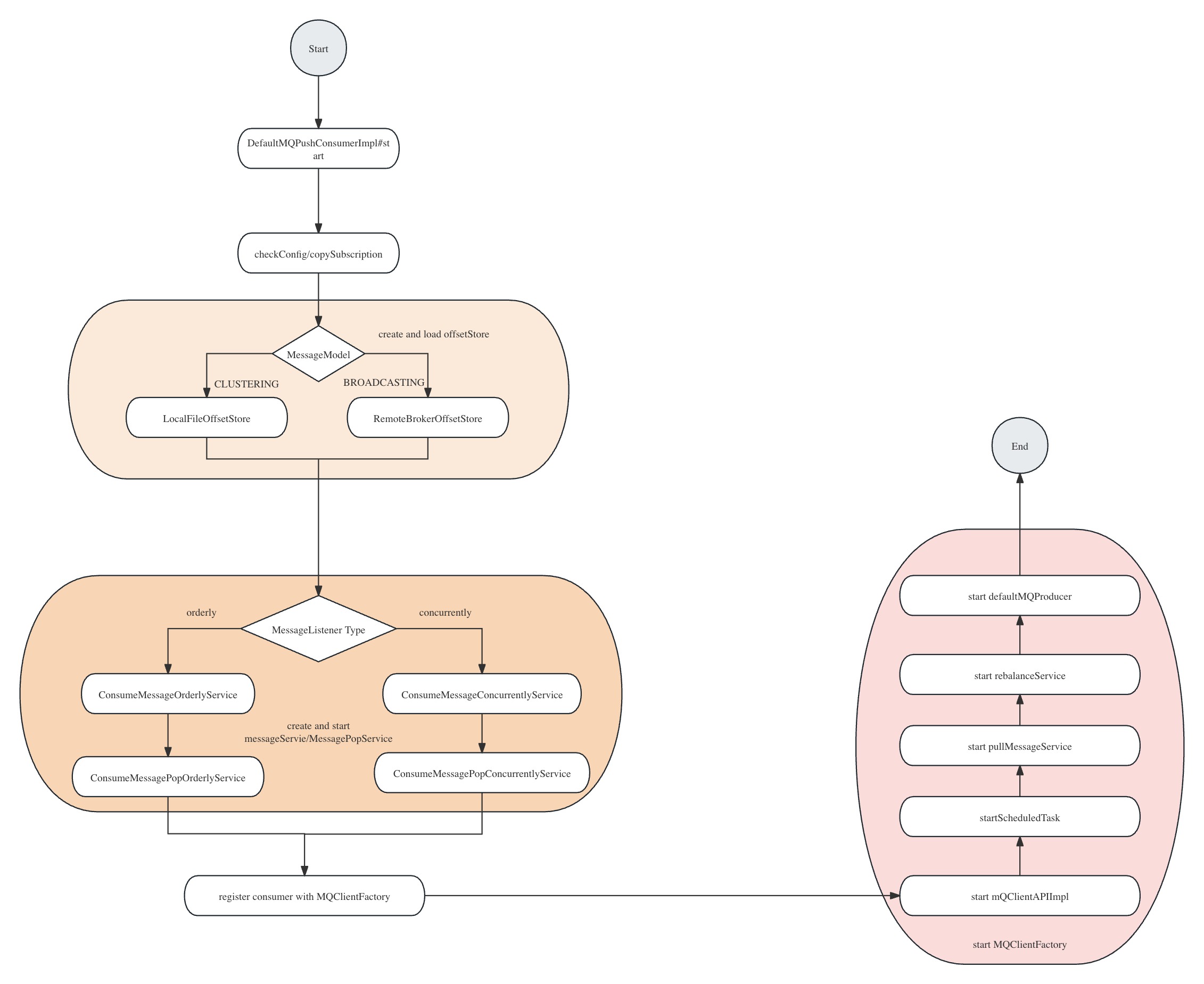
- 首先我们先来看看Consumer是如何初始化的,首先我们要创建一个DefaultMQPushConsumer,再设置对应的参数,然后再注册对应的MessageListener,最后在启动consumer。
- 启动consumer的过程中,首先看检查相应的配置信息,如consumerGroup、messageModel是否存在,拉取、消费线程的配置情况,拉取队列的大小等等;然后将对应的订阅信息put到rebalance的subscriptionInner中。
- 根据MessageModel的类型创建并加载对应的offsetStore
- CLUSTERING:创建并加载RemoteBrokerOffsetStore,CLUSTERING模式的offset存放到Broker端
- BROADCASTING:创建并加载LocalFileOffsetStore,BROADCASTING模式的offset存在到Client端。
- 根据MessageListener的类型创建并启动MessageListener,两者的区别可以从字面意思就可以知晓,一个是并发的执行消费逻辑,另一个是顺序的执行消费逻辑。
- orderly:创建并启动ConsumerMessageOrderlyService和ConsumeMessagePopOrderlyService
- concurrently:创建并启动ConsumeMessageConcurrentlyService和ConsumeMessagePopConcurrentlyService
- 将自己注册到MQClientFactory中。
- 最后在启动MQClientFactory
- 先检查是否已经获取到了NameServer的地址,没有的话去获取NameServer的地址
- 再开启request-response的channel
- 启动schedule任务线程。
- 定时去获取NameServer的地址
- 更新对应Topic的路由信息
- 持久化当前服务的所有的Consumer的offset信息,只持久化LocalFileOffsetStore,即广播消费。
- 调整线程池线程数量大小,目前concurrent模式和order模式都没有对应的实现。
- 然后在启动pullService和rebalanceService
- 最后再启动DefaultMQProducer,为什么要启动Producer?因为在消费监听返回RECONSUMER_LATER后,消息会发送到Broker,这个时候就需要发送者发送对应的RETRY消息。
4. 拉取消息(客户端处理)
当Consumer成功启动后,就开始拉取消息并消费。但是上述过程其实已经启动了拉取、消费线程,具体的执行如下:
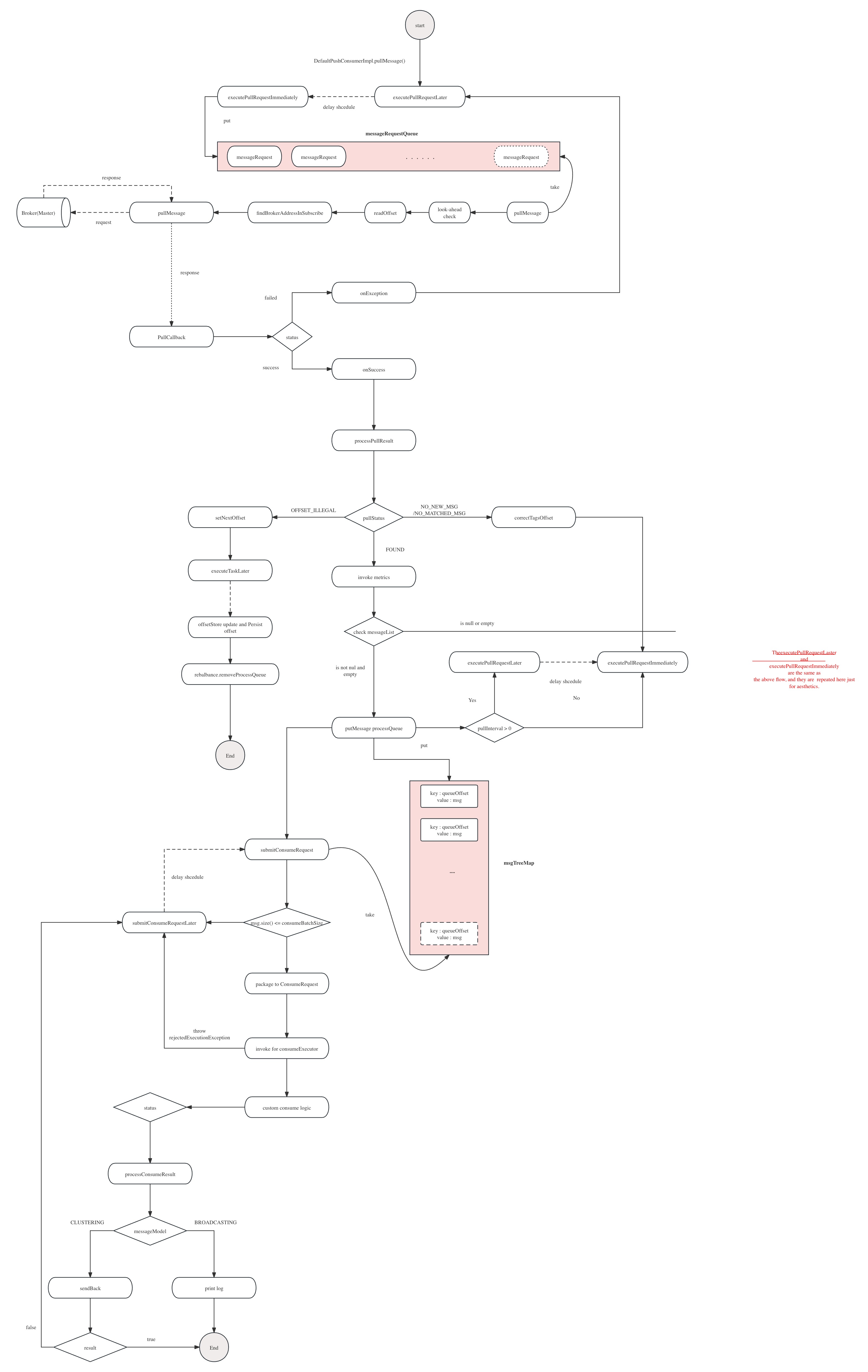
- 当start PullMessageService的时候,会启动一个PullMessageServiceScheduledThread线程,这个线程专门负责执行拉取消息的动作,先判断请求模式,POP消息先不做讲解,后面专门讲解POP消息,MessageRequestMode不为POP消息,执行pullMessage方法。
- 首先是一些前置检查:检查状态是否OK,检查本地缓存的消息的size、byte是否大于阈值,检查无误后,读取offset信息,再到subscribeData中find一个Broker地址,远程请求Broker。
- 请求Broker之后,等broker处理之后,根据返回的结果执行对应的回调
- PullCallback.onException:调用executePullRequestLater,延迟相应的时间,执行executePullRequestImmediately,将当前的PullRequest对象put到到messageRequestQueue中。
- PullMessageServiceScheduledThread线程,会不断地从messageRequestQueue take PullRequest对象,拿到PullRequest对象后,执行PullMessage方法,与上述的pullMessage执行过程一致。
- PullCallback.onSuccess:先调用processPullResult方法处理broker返回的result,然后再判断状态:
- FOUND
- 先将对应的指标加到对应的metrics,判断是否返回了消息
- 为null或者empty:调用executePullRequestLater
- 不为null或者empty:先put到msgTreeMap中,然后根据pullInterval判断调用executePullRequestLater或者executePullRequestImmediately。
- 先将对应的指标加到对应的metrics,判断是否返回了消息
- NO_NEW_MSG/NO_MATCHED_MSG:执行correctTagsOffset,更正offset,调用executePullRequestLater
- OFFSET_ILLEGAL:延迟10s,更新offset信息并持久化到磁盘上(仅针对BROADCASTING模式,CLUSTERING模式的offset保存在broker,所以不需要持久化,这时候客户端对requestBroker进行更新。);然后remove对应的ProcessQueue。
- FOUND
- PullCallback.onException:调用executePullRequestLater,延迟相应的时间,执行executePullRequestImmediately,将当前的PullRequest对象put到到messageRequestQueue中。
- 当put完到msgTreeMap中后,执行submitConsumeRequet方法
- 先判断当前消息条数是否满足消费的阈值,
- 不满足:执行submitConsumeRequestLater
- 满足:先把对应的msg、processQueue、messageQueue封装成一个ConsumeRequest对象,丢给消费线程去调用,如果此时抛出rejectedExecutionException,执行submitConsumeRequet
- ConsumeRequest实现了Runnable接口,所以被消费线程执行时,会执行内部的run方法
- run:先执行用户自己的消费逻辑并返回结果并处理consumeResult并更新对应的ackIndex
- 如果ackIndex不满足对应的要求,说明这批消息消费失败,根据messageModel来执行一下逻辑
- CLUSTERING:执行sendBack,将消息发送给Broker,这就是为什么consumer也需要创建Producer对象的原因;等待sendback时候执行完成,如果执行失败,执行submitConsumeRequestLater,反之则结束。
- BROADCASTING:输入warn日志即完成。
- 如果ackIndex不满足对应的要求,说明这批消息消费失败,根据messageModel来执行一下逻辑
- run:先执行用户自己的消费逻辑并返回结果并处理consumeResult并更新对应的ackIndex
- 先判断当前消息条数是否满足消费的阈值,
拉取消息(Broker端处理)
当拉取请求到达Broker端时,执行流程如下图:
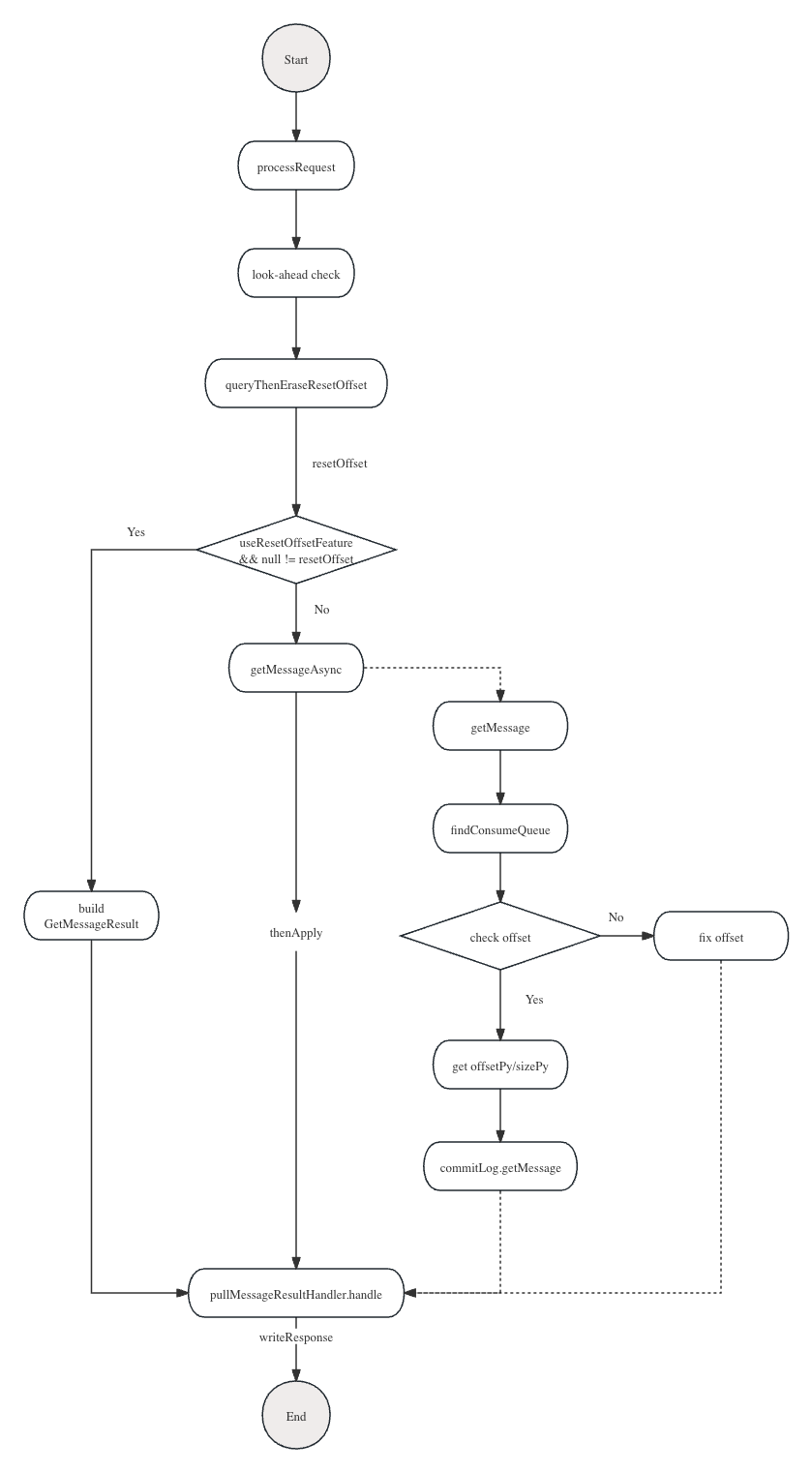
- 拉取请求到达Broker后,通过Broker内部封装的netty,使请求流转到PullMessageProcessor,先进行一些前置检查,如:是否用户当前Broker的拉取权限;当前Broker的主动拉取是否开启;当前ConsumerGroup对应的SubscribeGroup是否存在;当前topic对应的TopicConfig是否存在;校验当前请求参数是否正确等等
- 然后再查询resetOffsetTable中是否有对应重置之后的offset并且重置操作在Broker进行。
- 是:把对应的resetSequence set到GetMessageResult中,最后PullMessageResultHandler处理,最后在response给客户端。
- 否:先getMessageStore(我们以DefaultMessageStore为例,DLedgerMessageStore,后续再详细讲解),在调用messageStore.getMessageAsync()方法,getMessageAsync方法本质上就是用CompletableFuture包了一下getMessage方法。先判断当前topic是否开启了压缩,开启压缩:调用compactionStore.getMessage()(其实本质上还是查CommitLog,所以在流程图中并未体现),拿到ConsumeQueue后,先检查offset是否正确
- 正确:遍历Mmap直至拿到正确的offsetPy,SizePy,再跟你offsetPy定位到具体的commitlog文件,定位到commitlog文件后,先确定开始拉取的postion(offset%mappedFileSize),把消息写到对应的byteBuffer中。
- 不正确:修正offset,再把修正之后的offset set到getResult中
- 上述执行完成后,在PullMessageResultHandler中进行处理
- 先执行执行之后的回调
- 如果是广播消费,更新对应广播消费的拉取进度,如果不是广播消费,这步可以忽略
- 然后把对应的消费进去commit到offsetTable中。
- 最后在把结果response给客户端。
创作不易:请关注微信公众号:【An前码后】获取更多源码解析,您的关注,就是博主创作的一份动力。
这篇关于【Apache Rocket】源码解析:消息消费源码解析(监听模式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





