本文主要是介绍xxl-job使用(小白也看得懂),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分布式任务调度
在微服务架构体系中,服务之间通过网络交互来完成业务处理的,在分布式架构下,一个服务往往会部署多个实例来运行我们的业务,如果在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度。
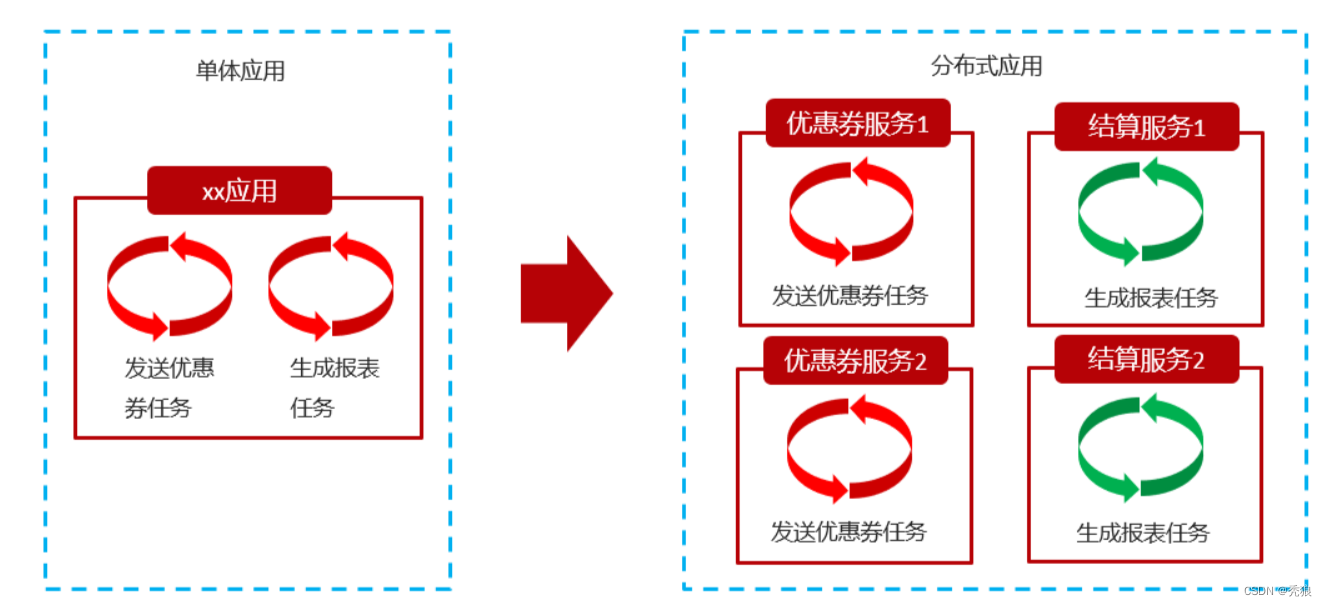
在当体项目中我们直接使用异步任务就可以实现发布任务的效果,但是在微服务中,每个服务是独立的,任务和任务之间是无法协调的,所以我们需要使用xxl-job。
xxl-job简介
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
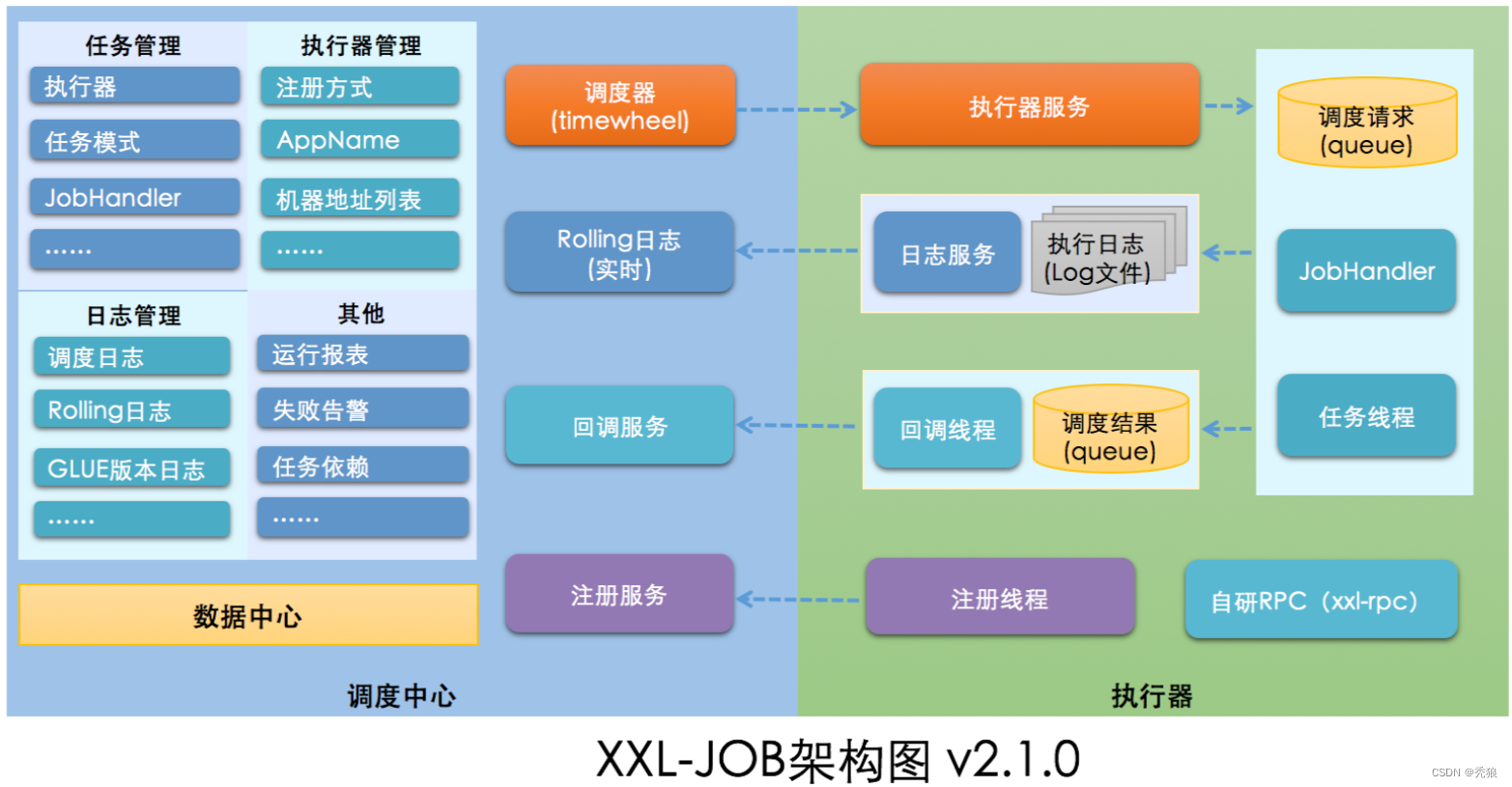
xxl-job架构图
安装xxl-job
通过docker安装xxl-job
在云服务器中创建目录 /data/applogs,该目录用于挂载xxl-job-admin-applogs。设置对应的数据库信息,设置开机自启动,映射端口,并进行挂载。
1.在搭建之前我们需要先要在云服务器中准备好xxl-job的数据库xxl_job,并初始化数据库。
初始化数据库的sql脚本为:数据库初始化脚本
2.拖取xxl-job的镜像。
docker pull xuxueli/xxl-job-admin:2.3.03.创建目录。
mkdir /data/applogs4.启动xxl-job的容器(在此之前需要开放对应的端口)。
docker run -d \
-e PARAMS="--spring.datasource.url=jdbc:mysql://139.9.544.116:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=UTC \
--spring.datasource.username=xxl_job \
--spring.datasource.password=123456 \
--spring.datasource.driver-class-name=com.mysql.jdbc.Driver" \
-p 28080:8080 \
-v xxl-job-admin-applogs:/data/applogs \
--name my-xxl-job-admin-2.3.0 \
-d xuxueli/xxl-job-admin:2.3.0
效果图为下:
输入定时任务的管理界面的地址为: 139.9.567.564:28080/xxl-job-admin(IP根据自己修改)
初始的账号: admin 密码:123456
效果图为下:
数据库中表的信息
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
xxl-job的使用
使用方式:在服务中编写好执行器(也就是执行的方法)将其注册到xxl-job中,在xxl-job的控制面板中设置定时任务去调用执行器,最终实现定时任务。
xxl-job支持的路由策略非常丰富:
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):在线的机器按照顺序一次执行一个
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
xxl-job使用格式
引入对应的依赖
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId>
</dependency>创建配置类XxlJobConfig用于配置必要信息
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** xxl-job config*/
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken:}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address:}")private String address;@Value("${xxl.job.executor.ip:}")private String ip;@Value("${xxl.job.executor.port:0}")private int port;@Value("${xxl.job.executor.logpath:}")private String logPath;@Value("${xxl.job.executor.logretentiondays:}")private int logRetentionDays;//自动配置到ioc中@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}}编写执行器JobHandler(例子)
import cn.hutool.core.util.RandomUtil;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;import java.time.LocalDateTime;
import java.util.Arrays;
import java.util.List;/*** 任务处理器*/
@Component
public class JobHandler {private List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);/*** 普通任务*/@XxlJob("firstJob")public void firstJob() throws Exception {System.out.println("firstJob执行了.... " + LocalDateTime.now());for (Integer data : dataList) {System.out.println("data= {}" + data);Thread.sleep(RandomUtil.randomInt(100, 500));}System.out.println("firstJob执行结束了.... " + LocalDateTime.now());}
}在@XxlJob中配置的属性就是执行器的名字。
进入任务调度中心发布定时任务,设置执行器的AppName也就是当前微服务的application.name
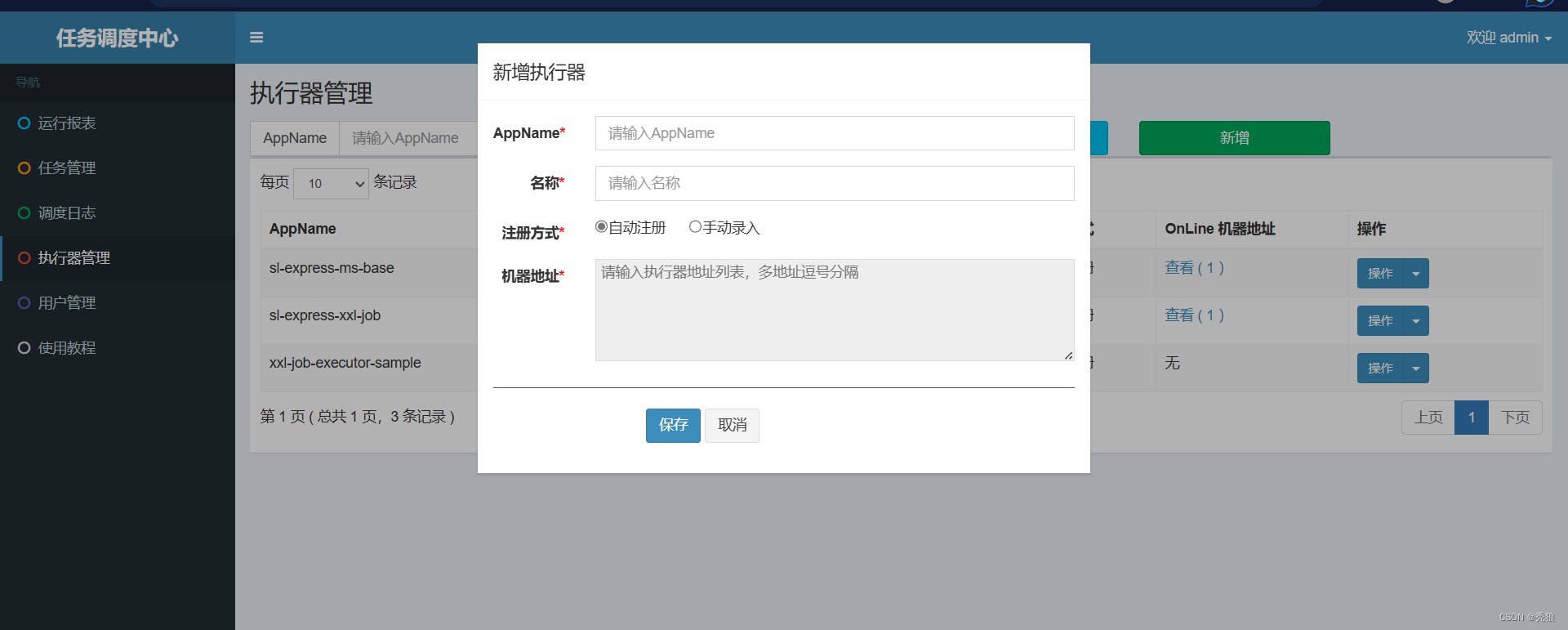
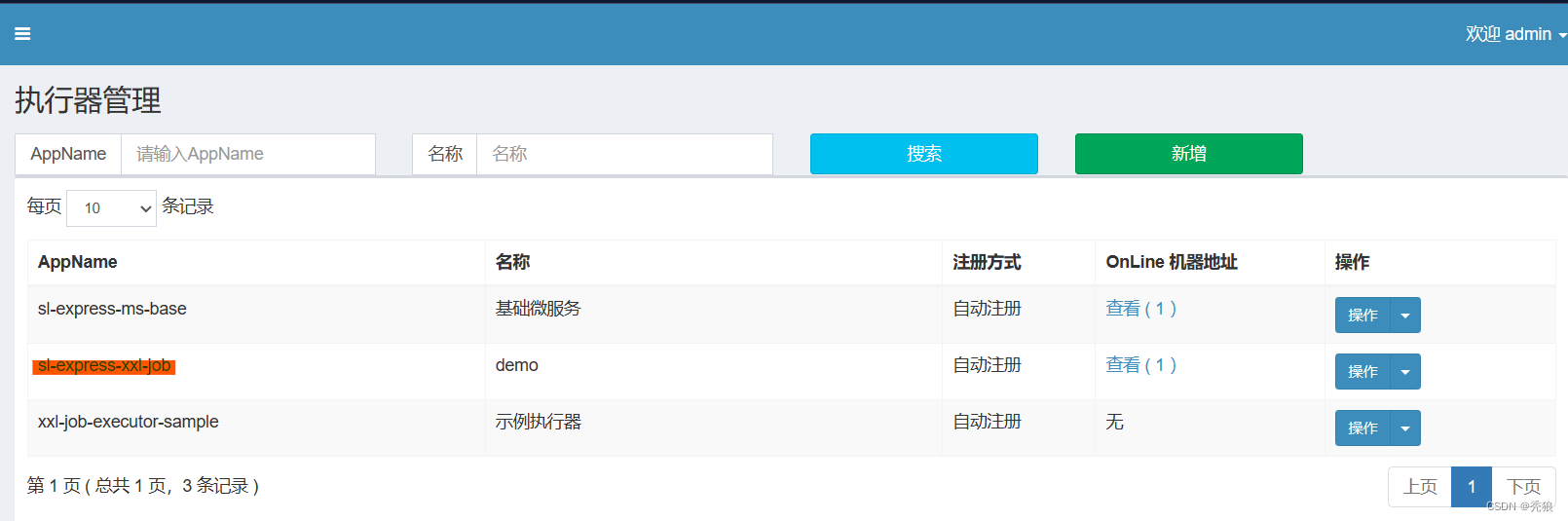
选择执行器,新建任务。
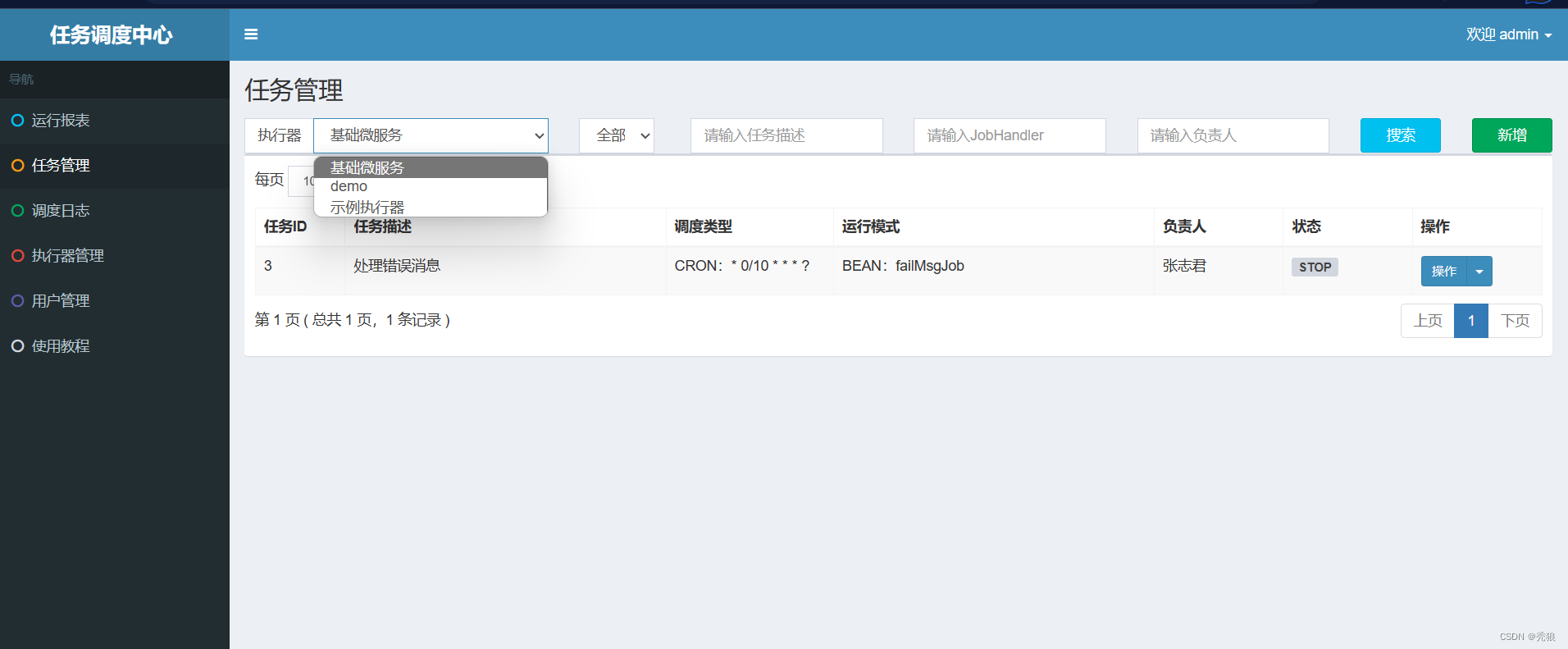 在新建任务中JobHandler就是我们在微服务中编写的任务处理器的名称,该名称就是对应的@XxlJob中属性的值。
在新建任务中JobHandler就是我们在微服务中编写的任务处理器的名称,该名称就是对应的@XxlJob中属性的值。
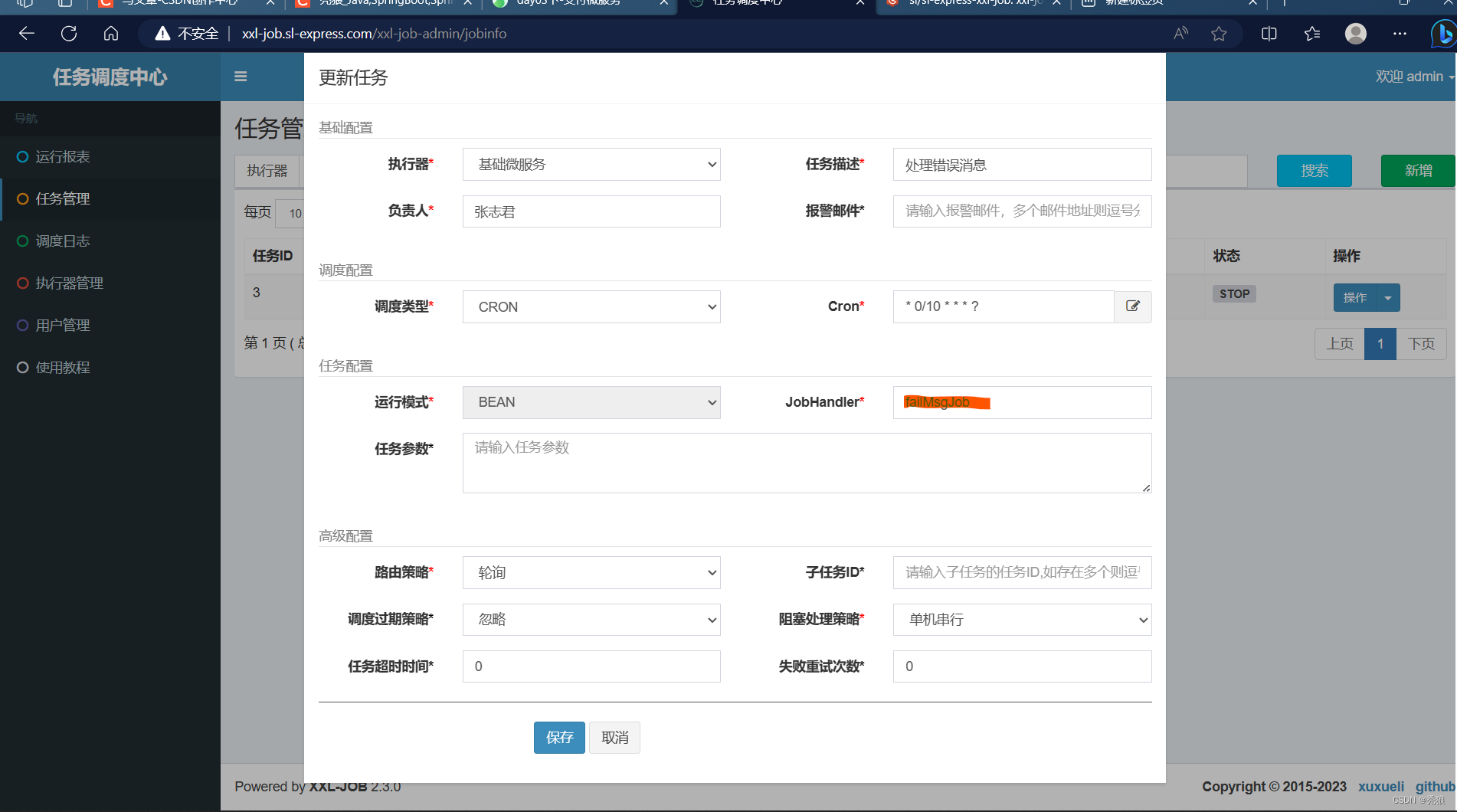
进行测试,点击执行一次,弹出窗口直接迪点击确认。
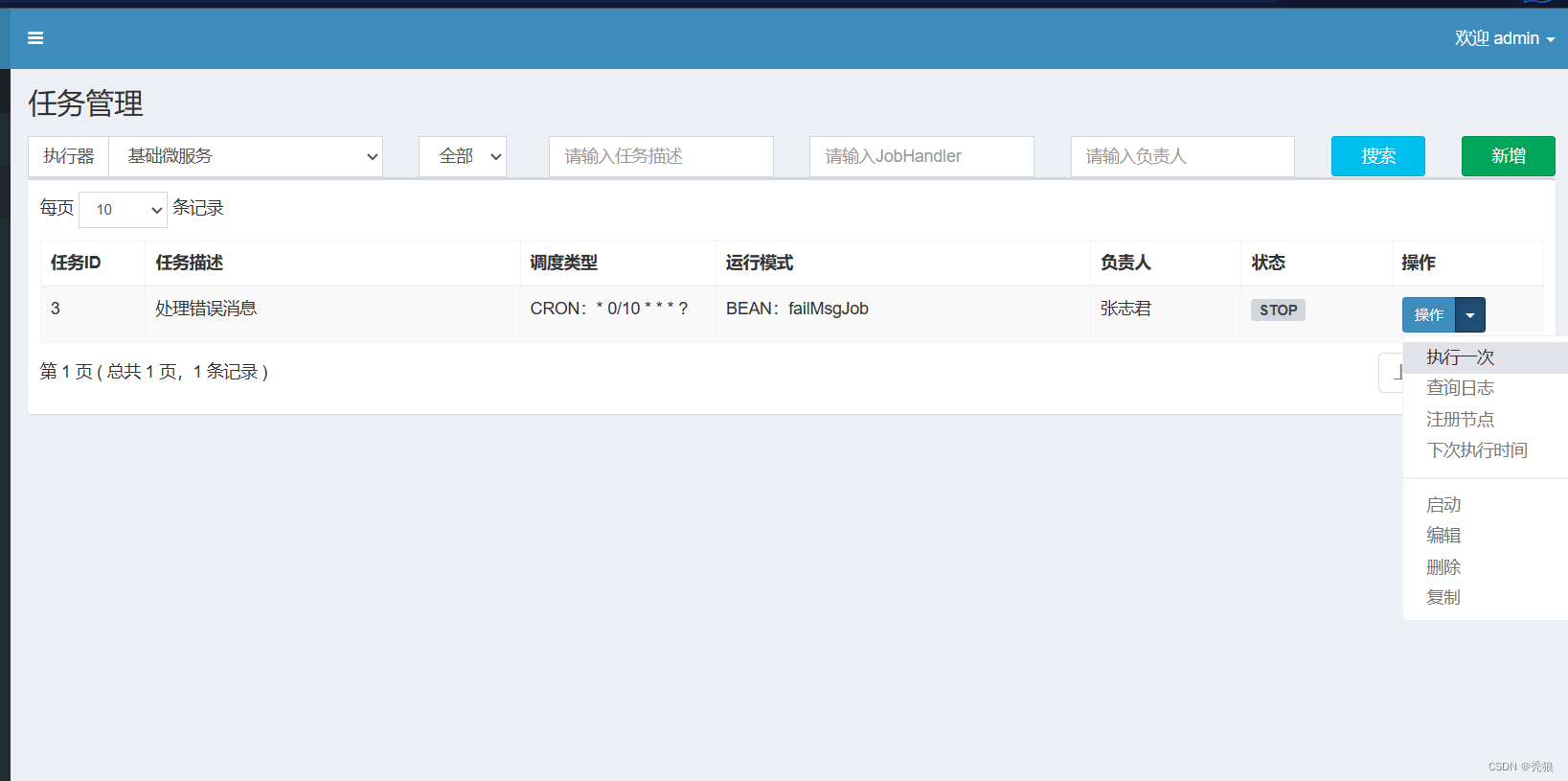 该测试处理器中,就是将属性dataList遍历一遍。
该测试处理器中,就是将属性dataList遍历一遍。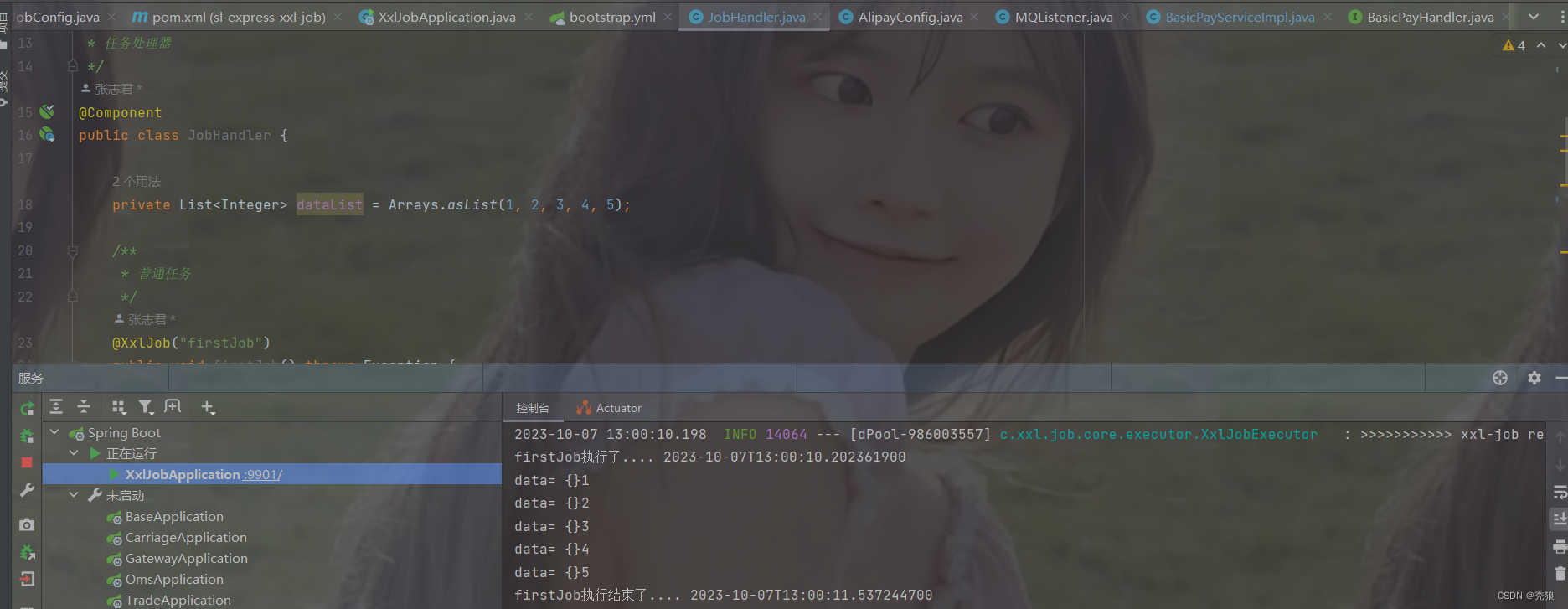
这是单个xxl-job的情况,接下来我吗们需要实现xxl-job集群的使用。
在Handler中编写一个处理器(通过取模的方式,让每个xxl-job都可以处理到任务,例如:三个集群,我们就以三取模,每个xxl-job就分别处理值为 0,1 ,2的任务)
import cn.hutool.core.util.RandomUtil;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;import java.time.LocalDateTime;
import java.util.Arrays;
import java.util.List;/*** 任务处理器*/
@Component
public class JobHandler {private List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);/*** 分片式任务*/@XxlJob("shardingJob")public void shardingJob() throws Exception {// 分片参数// 分片节点总数int shardTotal = XxlJobHelper.getShardTotal();// 当前节点下标,从0开始int shardIndex = XxlJobHelper.getShardIndex();System.out.println("shardingJob执行了.... " + LocalDateTime.now());for (Integer data : dataList) {if (data % shardTotal == shardIndex) {System.out.println("data= {}"+ data);Thread.sleep(RandomUtil.randomInt(100, 500));}}System.out.println("shardingJob执行结束了.... " + LocalDateTime.now());}
}在任务管理中添加一个新的任务
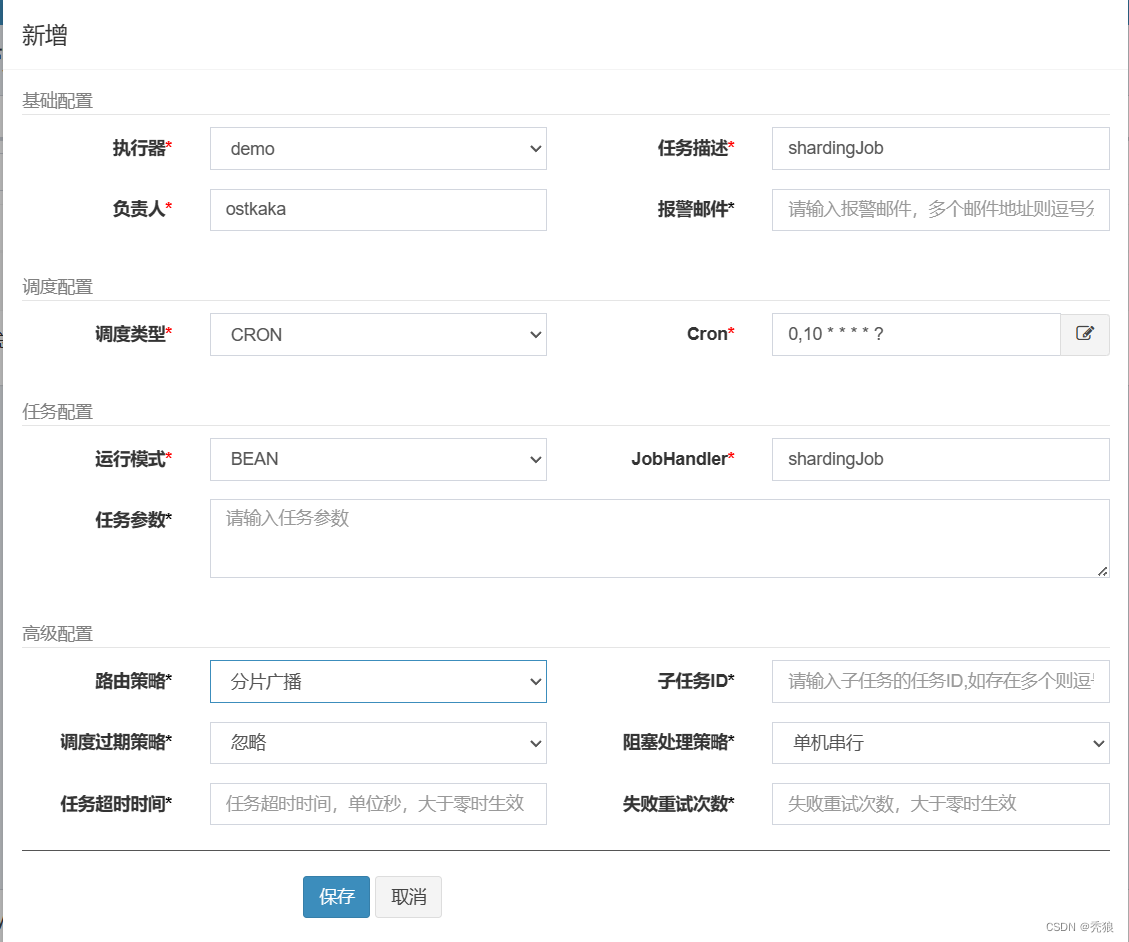
进行测试,两个xxl-job都参与了任务的处理。

 真正意义上实现了轮询的效果,而在路由策略的轮询的效果则是每一个xxl-job按顺序单独处理一次任务,这样任务还是没有达到负载均衡的效果。
真正意义上实现了轮询的效果,而在路由策略的轮询的效果则是每一个xxl-job按顺序单独处理一次任务,这样任务还是没有达到负载均衡的效果。
这篇关于xxl-job使用(小白也看得懂)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






