本文主要是介绍MeterSphere本地化部署实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目结构

搭建本地环境
- 安装JDK11,配置好JDK环境,系统同时支持JDK8和JDK11
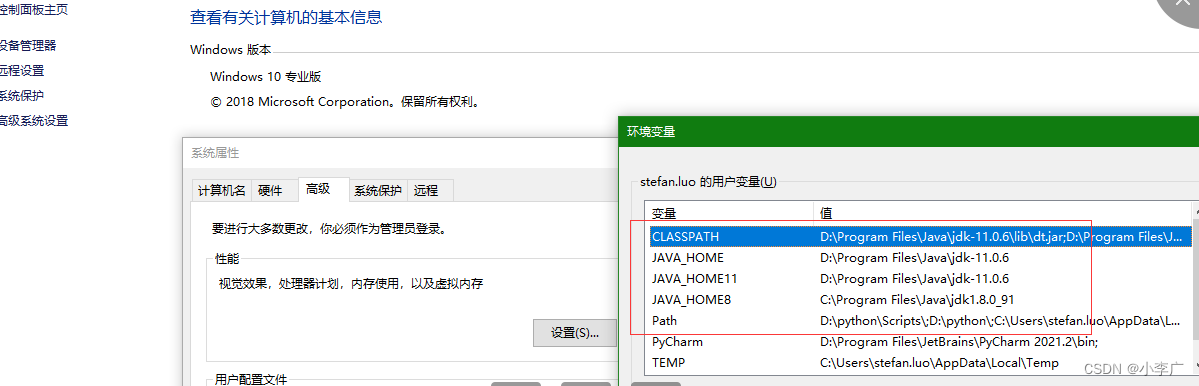
- 安装IEAD,配置JDK环境


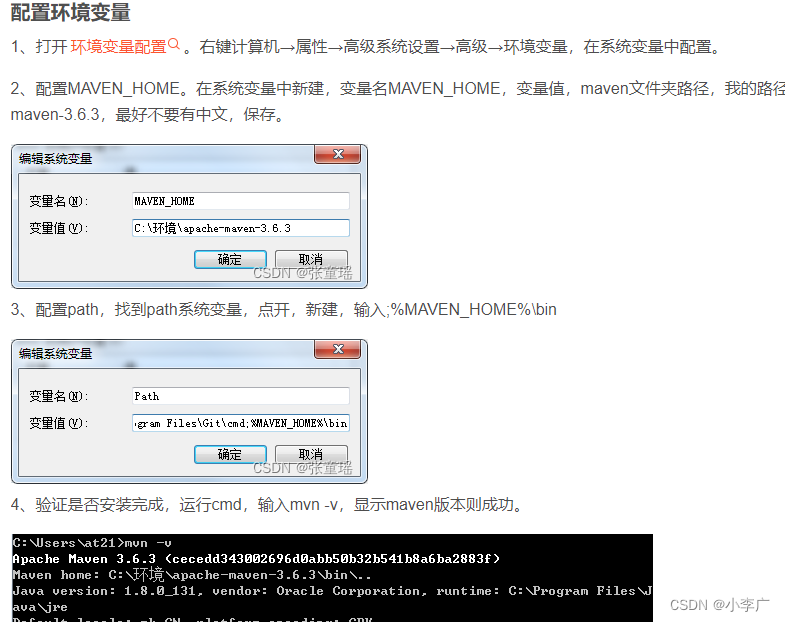
- 配置maven环境,IDEA配置(解压可以直接使用)
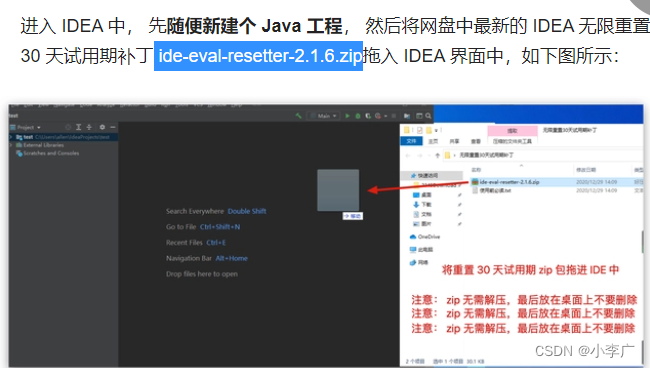
- 无限重置IDEA试用期

- 配置redis环境(解压可以直接使用)
- 配置kafka环境
- 安装mysql-5.7环境,创建数据库(metersphere)
- 替换jar包
ApacheJMeter_core-5.4.3、ApacheJMeter_tcp-5.4.3、ms-jmeter-core-1.2
- 安装node环境

配置开发环境
Kafka环境
官网下载kafaka包
配置属性文件和环境


启动kafka
cd D:\soft\kafka_2.13-2.8.1\bin\windows>
1.kafka启动脚本和zookeeper启动脚本
zookeeper-server-start.bat ..\..\config\zookeeper.properties
2.运行成功,2181端口,不要关闭窗口
执行命令 kafka-server-start.bat ..\..\config\server.properties
参考文献:https://blog.csdn.net/weixin_43085439/article/details/106403168
Redis环境

后端
MeterSphere 后端使用了 Java 语言的 Spring Boot 框架,并使用 Maven 作为项目管理工具。开发者需要先在开发环境中安装 JDK 1.11 及 Maven。
初始化配置
MeterSphere 使用 MySQL 数据库,推荐使用 MySQL 5.7 版本。同时 MeterSphere 对数据库部分配置项有要求,请参考下附的数据库配置,修改开发环境中的数据库配置文件。
[mysqld]
default-storage-engine=INNODB
lower_case_table_names=1
table_open_cache=128
max_connections=2000
max_connect_errors=6000
innodb_file_per_table=1
innodb_buffer_pool_size=1G
max_allowed_packet=64M
transaction_isolation=READ-COMMITTED
innodb_flush_method=O_DIRECT
innodb_lock_wait_timeout=1800
innodb_flush_log_at_trx_commit=0
sync_binlog=0
server-id=1
log-bin=mysql-bin
expire_logs_days = 2
binlog_format=mixed
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
skip-name-resolve
请参考文档中的建库语句创建 MeterSphere 使用的数据库,metersphere-server 服务启动时会自动在配置的库中创建所需的表结构及初始化数据。
CREATE DATABASE `metersphere` /*!40100 DEFAULT CHARACTER SET utf8mb4 */
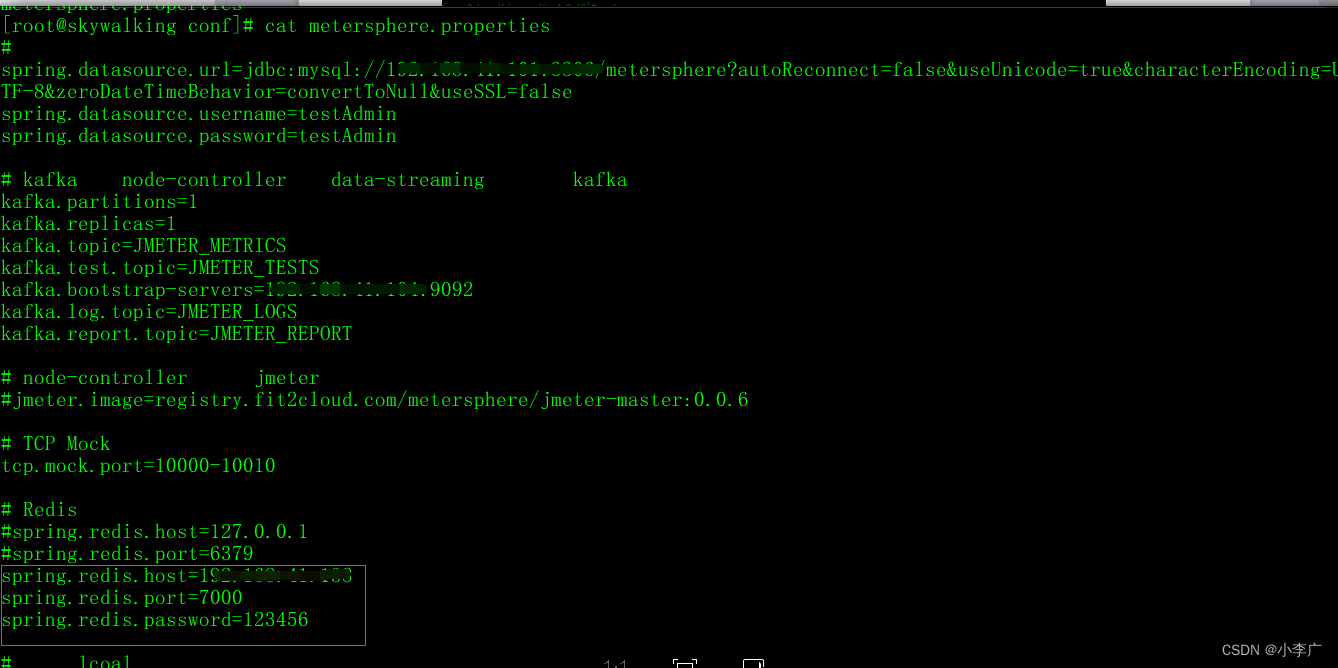
METERSPHERE 配置文件
MeterSphere 会默认加载该路径下的配置文件 /opt/metersphere/conf/metersphere.properties,请参考下列配置创建对应目录及配置文件。
# 数据库配置
spring.datasource.url=jdbc:mysql://localhost:3306/metersphere?autoReconnect=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
# kafka 配置,node-controller 以及 data-streaming 服务需要使用 kafka 进行测试结果的收集和处理
kafka.partitions=1
kafka.replicas=1
kafka.topic=JMETER_METRICS
kafka.test.topic=JMETER_TESTS
kafka.bootstrap-servers={KAFKA_IP}:9092
kafka.log.topic=JMETER_LOGS
kafka.report.topic=JMETER_REPORT
# node-controller 所使用的 jmeter 镜像版本
jmeter.image=registry.fit2cloud.com/metersphere/jmeter-master:0.0.6
# TCP Mock 端口范围
tcp.mock.port=10000-10010
# Redis 配置
spring.redis.host={REDIS_IP}
spring.redis.port=6379
spring.redis.password=Password123@redis
# 启动模式,lcoal 表示以本地开发模式启动
run.mode=local
JMETER 配置文件
metersphere-server 服务依赖的 JMeter 核心类库需要加载 JMeter 配置文件,默认加载 /opt/jmeter 下的配置文件。
开发者需要先创建好对应文件夹,并将工程目录中 backend/src/main/resources/jmeter/bin 目录下的配置文件拷贝到 /opt/jmeter/bin 目录。
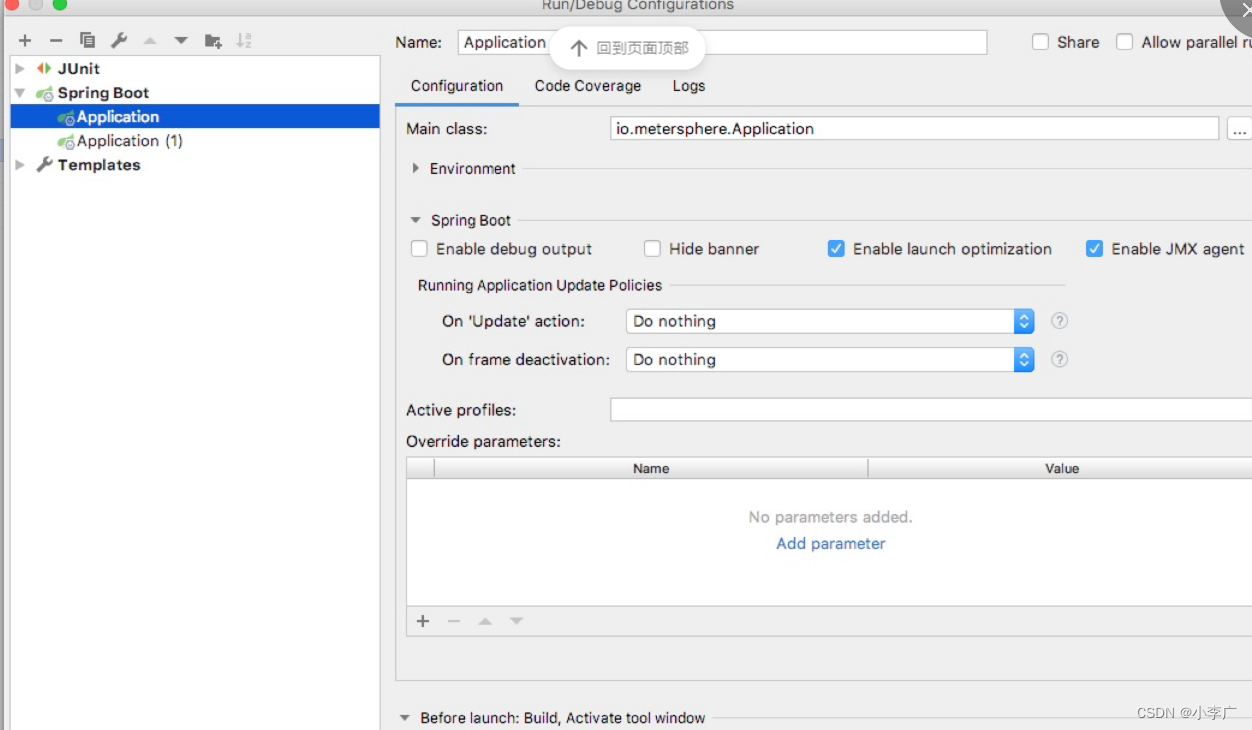
运行后端服务
在启动配置中添加 Spring Boot 启动项,直接启动 Spring Boot 项目即可。
前端
MeterSphere 前端使用了 Vue.js 作为前端框架,ElementUI 作为 UI 框架,并使用 npm 作为包管理工具。开发者请先下载 Node.js 作为运行环境,IDEA 用户建议安装 Vue.js 插件,便于开发。
初始化配置
进入 metersphere-server/frontend/ 目录,执行以下命令安装相关前端组件。
npm install
运行前端服务
进入到 metersphere-server/frontend/ 目录,执行以下命令启动前端服务。
npm run serve
页面效果
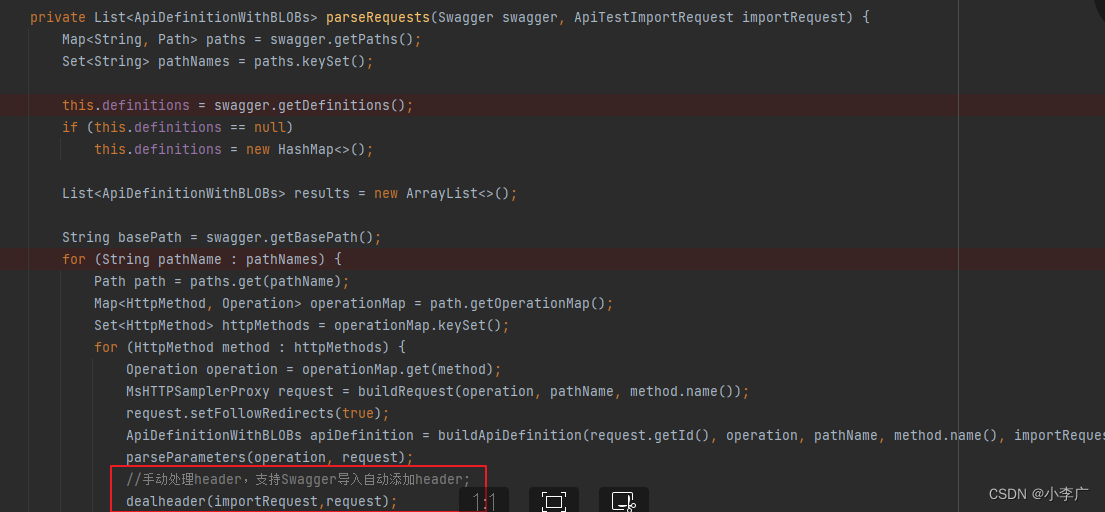
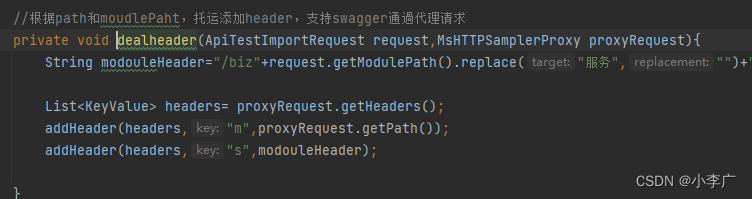
swagger导入接口时处理请求头
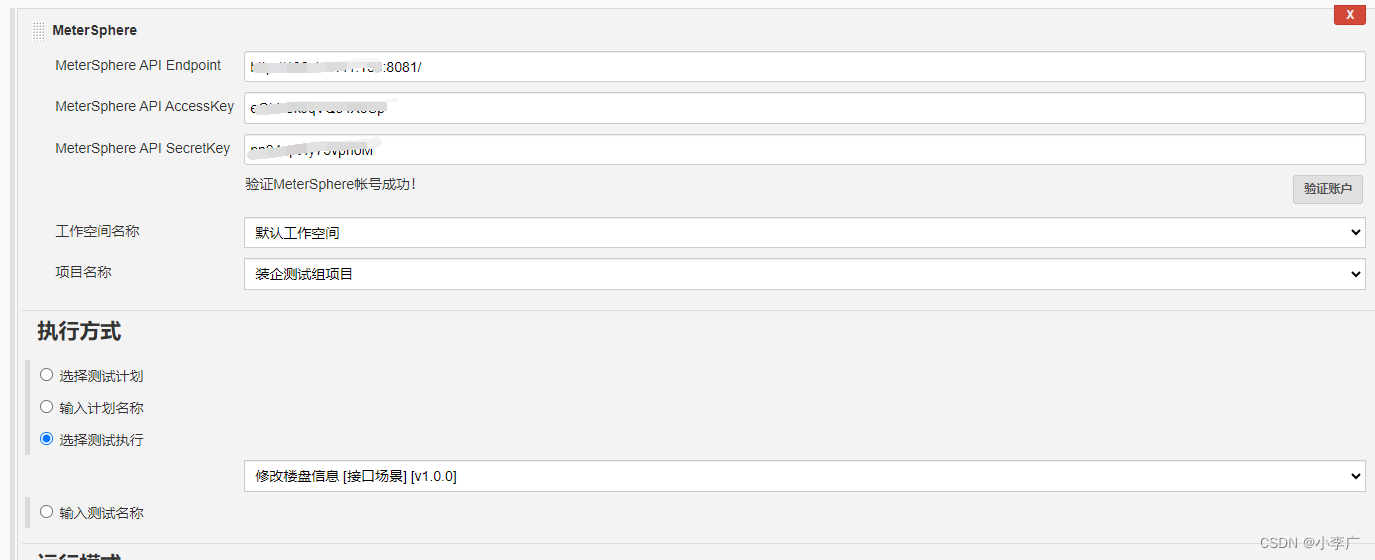
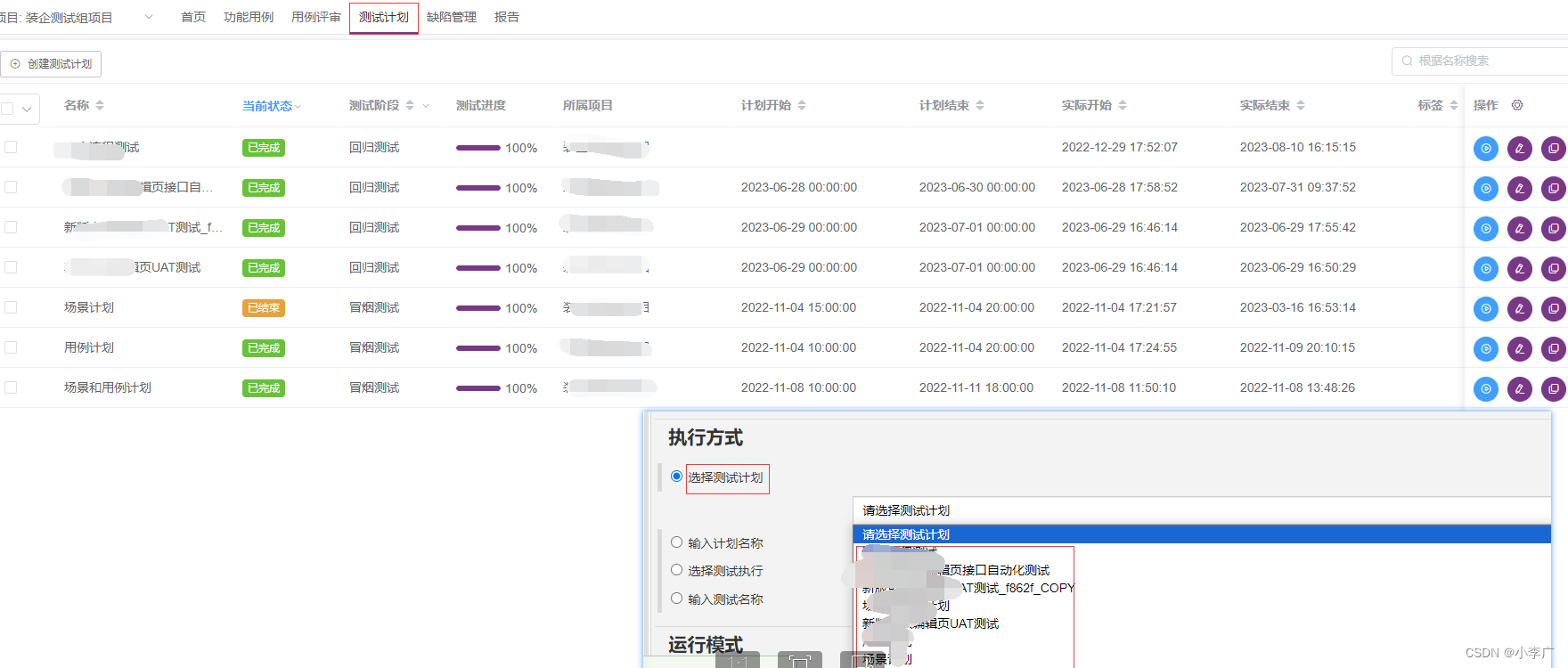
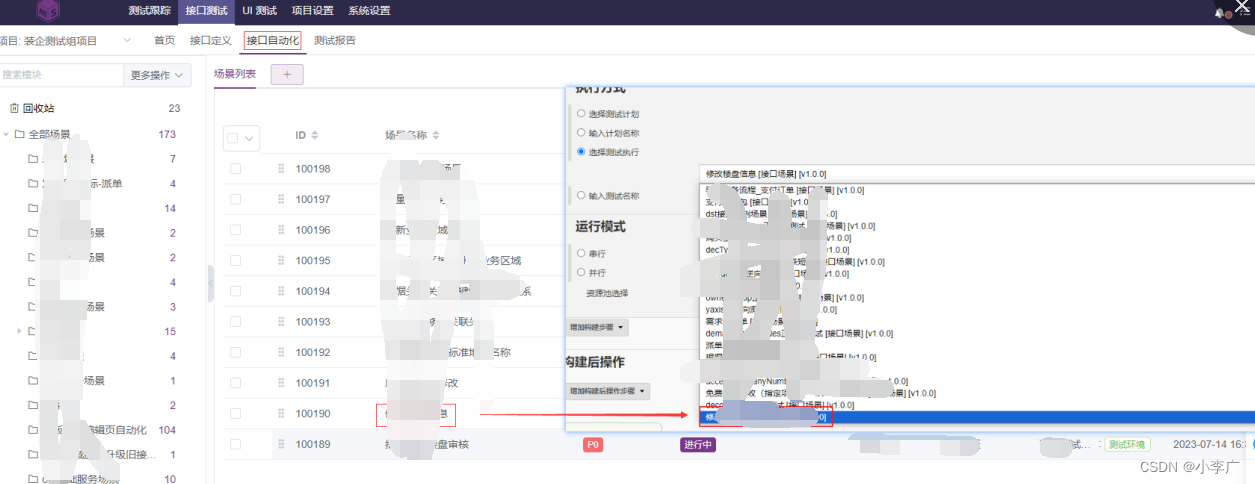
meterSphere安装Jenkins并执行(插件对应ms版本)

配置Key

验证URL和用户

文中插件下载地址:
https://download.csdn.net/download/luozhuwang/88759636
https://blog.51cto.com/u_11100758/3217808
https://blog.csdn.net/weixin_43085439/article/details/106403168
这篇关于MeterSphere本地化部署实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








