本文主要是介绍memcached内存管理分析(不同于上一篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Memcached是一个高效的分布式内存cache,了解memcached的内存管理机制,便于我们理解memcached,让我们可以针对我们数据特点进行调优,让其更好的为我所用。这里简单谈一下我对memcached的内存管理的一些认识,在没有特别注明的情况下,这里谈到的memcached是1.2版本,1.1和1.2版本有一些差异。
基本概念:Slab和chunk
在Memcached内存结构中有两个非常重要的概念:slab 和 chunk,我们先从下图中对这两个概念有一个感性的认识:
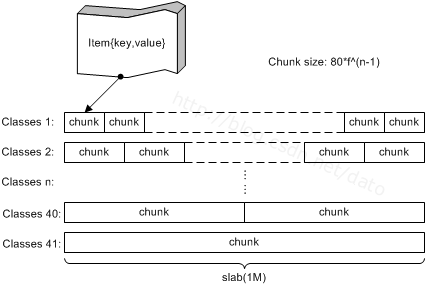
图 1 memcached内存结构

Slab是一个内存块,它是memcached一次申请内存的最小单位。在启动memcached的时候一般会使用参数-m指定其可用内存,但是并不是在启动的那一刻所有的内存就全部分配出去了,只有在需要的时候才会去申请,而且每次申请一定是一个slab。Slab的大小固定为1M(1048576 Byte),一个slab由若干个大小相等的chunk组成。每个chunk中都保存了一个item结构体、一对key和value。
虽然在同一个slab中chunk的大小相等的,但是在不同的slab中chunk的大小并不一定相等,在memcached中按照chunk的大小不同,可以把slab分为很多种类(class)。在启动memcached的时候可以通过-vv来查看slab的种类:
$ memcached -vv
slab class 1: chunk size 80 perslab 13107
slab class 2: chunk size 104 perslab 10082
slab class 3: chunk size 136 perslab 7710
slab class 4: chunk size 176 perslab 5957
slab class 5: chunk size 224 perslab 4681
slab class 6: chunk size 280 perslab 3744
slab class 7: chunk size 352 perslab 2978
slab class 8: chunk size 440 perslab 2383
slab class 9: chunk size 552 perslab 1899
slab class 10: chunk size 696 perslab 1506
slab class 11: chunk size 872 perslab 1202
slab class 12: chunk size 1096 perslab 956
slab class 13: chunk size 1376 perslab 762
slab class 14: chunk size 1720 perslab 609
slab class 15: chunk size 2152 perslab 487
slab class 16: chunk size 2696 perslab 388
slab class 17: chunk size 3376 perslab 310
slab class 18: chunk size 4224 perslab 248
slab class 19: chunk size 5280 perslab 198
slab class 20: chunk size 6600 perslab 158
slab class 21: chunk size 8256 perslab 127
slab class 22: chunk size 10320 perslab 101
slab class 23: chunk size 12904 perslab 81
slab class 24: chunk size 16136 perslab 64
slab class 25: chunk size 20176 perslab 51
slab class 26: chunk size 25224 perslab 41
slab class 27: chunk size 31536 perslab 33
slab class 28: chunk size 39424 perslab 26
slab class 29: chunk size 49280 perslab 21
slab class 30: chunk size 61600 perslab 17
slab class 31: chunk size 77000 perslab 13
slab class 32: chunk size 96256 perslab 10
slab class 33: chunk size 120320 perslab 8
slab class 34: chunk size 150400 perslab 6
slab class 35: chunk size 188000 perslab 5
slab class 36: chunk size 235000 perslab 4
slab class 37: chunk size 293752 perslab 3
slab class 38: chunk size 367192 perslab 2
slab class 39: chunk size 458992 perslab 2
slab class 40: chunk size 573744 perslab 1
slab class 41: chunk size 717184 perslab 1
slab class 42: chunk size 1048576 perslab 1
slab class 1: chunk size 80 perslab 13107
slab class 2: chunk size 104 perslab 10082
slab class 3: chunk size 136 perslab 7710
slab class 4: chunk size 176 perslab 5957
slab class 5: chunk size 224 perslab 4681
slab class 6: chunk size 280 perslab 3744
slab class 7: chunk size 352 perslab 2978
slab class 8: chunk size 440 perslab 2383
slab class 9: chunk size 552 perslab 1899
slab class 10: chunk size 696 perslab 1506
slab class 11: chunk size 872 perslab 1202
slab class 12: chunk size 1096 perslab 956
slab class 13: chunk size 1376 perslab 762
slab class 14: chunk size 1720 perslab 609
slab class 15: chunk size 2152 perslab 487
slab class 16: chunk size 2696 perslab 388
slab class 17: chunk size 3376 perslab 310
slab class 18: chunk size 4224 perslab 248
slab class 19: chunk size 5280 perslab 198
slab class 20: chunk size 6600 perslab 158
slab class 21: chunk size 8256 perslab 127
slab class 22: chunk size 10320 perslab 101
slab class 23: chunk size 12904 perslab 81
slab class 24: chunk size 16136 perslab 64
slab class 25: chunk size 20176 perslab 51
slab class 26: chunk size 25224 perslab 41
slab class 27: chunk size 31536 perslab 33
slab class 28: chunk size 39424 perslab 26
slab class 29: chunk size 49280 perslab 21
slab class 30: chunk size 61600 perslab 17
slab class 31: chunk size 77000 perslab 13
slab class 32: chunk size 96256 perslab 10
slab class 33: chunk size 120320 perslab 8
slab class 34: chunk size 150400 perslab 6
slab class 35: chunk size 188000 perslab 5
slab class 36: chunk size 235000 perslab 4
slab class 37: chunk size 293752 perslab 3
slab class 38: chunk size 367192 perslab 2
slab class 39: chunk size 458992 perslab 2
slab class 40: chunk size 573744 perslab 1
slab class 41: chunk size 717184 perslab 1
slab class 42: chunk size 1048576 perslab 1
图2 slab分组信息
从上图可以看到,默认情况下memcached把slab分为40类(class1~class40),在class 1中,chunk的大小为80字节,由于一个slab的大小是固定的1048576字节(1M),因此在class1中最多可以有13107个chunk:
13107×80 + 16 = 1048576
在class1中,剩余的16字节因为不够一个chunk的大小(80byte),因此会被浪费掉。每类chunk的大小有一定的计算公式的,假定i代表分类,class i的计算公式如下:
chunk size(class i) : (default_size+item_size)*f^(i-1)+ CHUNK_ALIGN_BYTES
- default_size: 默认大小为48字节,也就是memcached默认的key+value的大小为48字节,可以通过-n参数来调节其大小;
- item_size: item结构体的长度,固定为32字节。default_size大小为48字节,item_size为32,因此class1的chunk大小为48+32=80字节;
- f为factor,是chunk变化大小的因素,默认值为1.25,调节f可以影响chunk的步进大小,在启动时可以使用-f来指定;
- CHUNK_ALIGN_BYTES是一个修正值,用来保证chunk的大小是某个值的整数倍(在32位机器上要求chunk的大小是4的整数倍)。
从上面的分析可以看到,我们实际可以调节的参数有-f、-n,在memcached的实际运行中,我们还需要观察我们的数据特征,合理的调节f,n的值,使我们的内存得到充分的利用减少浪费。
内存申请分配
Memcached内存管理采取预分配、分组管理的方式,分组管理就是我们上面提到的slab class,按照chunk的大小slab被分为很多种类。下面解释一下memcached的内存预分配过程。
向memcached添加一个item时候,memcached首先会根据item的大小,来选择最合适的slab class:例如item的大小为190字节,默认情况下class 4的chunk大小为160字节显然不合适,class 5的chunk大小为200字节,大于190字节,因此该item将放在class 5中(显然这里会有10字节的浪费是不可避免的),计算好所要放入的chunk之后,memcached会去检查该类大小的chunk还有没有空闲的,如果没有,将会申请1M(1个slab)的空间并划分为该种类chunk。例如我们第一次向memcached中放入一个190字节的item时,memcached会产生一个slab(也叫一个page),并会用去一个chunk,剩余5241个chunk供下次有适合大小item时使用,当我们用完这所有的5242个chunk之后,下次再有一个在160~200字节之间的item添加进来时,memcached会再次产生一个class 5的slab(这样就存在了2个pages)。查看slab的使用情况,我们可以telnet ip port,然后输入命令 stats slabs即可:
例如:telnet 10.0.4.210 11211
| stats slabs STAT 5:chunk_size 200 STAT 5:chunks_per_page 5242 STAT 5:total_pages 1 STAT 5:total_chunks 5242 STAT 5:used_chunks 5242 STAT 5:free_chunks 0 STAT 5:free_chunks_end 5241 STAT active_slabs 1 STAT total_malloced 1048400 |
图3 stats slab
图3显示的是第一次(???)放入一个190字节的item之后的统计结果。
总结:
我理解的是
就是memcached 在一开始启动的时候m参数是制定分配多大的内存。不是启动就分配的。。而是memcached使用的时候动态的分配的。当你set 一个item的时候,memcached 会根据你的这个item大小来判断 新增出一块 slab 每一块的slab的大小都是一样的。而是不同的class 类的slab 再分配 chunk时 是不一样的。。。这点就可以去优化你的memcached 根据你的应用
用 echo stats sizes | nc 127.0.0.1 11211 | less 查看内存多数的item 的大小 分布。。然后分配 不同类的slab 这个事可以调节的。。
可以看看这个 http://blog.sina.com.cn/s/blog_6ab686dc01010169.html
关于memcached 分配内存的时候,网上还有很多写的挺好的
转自:http://www.cnblogs.com/qq78292959/archive/2012/12/27/2836015.html
这篇关于memcached内存管理分析(不同于上一篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





