本文主要是介绍深度学习(初识tensorflow2.版本)之三好学生成绩问题(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝
🥰 博客首页:knighthood2001
😗 欢迎点赞👍评论🗨️
❤️ 热爱python,期待与大家一同进步成长!!❤️
👀给大家推荐一款很火爆的刷题、面试求职网站👀
目录
三好学生成绩问题的引入
搭建解决三好学生成绩问题的神经网络
构建的神经网络的代码
代码讲解
三好学生成绩问题的引入
我们来看这样一个问题: 某个学校将要评选三好学生,我们知道,三好学生的“三好"指的是品德好、学习好、体育好:而要进行评选,如今都需要量化,也就是说学校会根据德育分、智育分和体育分3项分数来计算一个总分, 然后根据总分来确定谁能够被评选为三好学生。假设这个学校计算总分的规则是:德育分占60% ,智育分占30%,体育分占10% 。这个规则如果用一个公式来表达是这样的
| 总分=德育分*0.6 +智育分* 0.3 +体育分*0.1 |
可以看到,计算三好学生总成绩的公式实际上是把3项分数各自乘上一个权重(weight)值,然后相加求和。
以上是我们要解决问题的背景。那么,我们需要解决的问题是这样的:有两位孩子的家长,知道了自己孩子的3项分数及总分,但是学校并没有告诉家长们计算出总分的规则。家长们猜测出计算总分的方法肯定是把3项分数乘以不同的权重后相加来获得,唯一不知道的就是这几个权重值到底是多少。现在家长们就想用人工智能中神经网络的方法来大致推算出这3个权重分别是多少。我们假设第一位家长的孩子A的德育分是90、智育分是80、 体育分是70、总分是85,并分别用w1、w2、w3来代表德育分、智育分和体育分所乘的权重,可以得到这个式子:
| 90 * w1 + 80 * w2 + 70 * w3 = 85 |
另一位孩子B的德育分是98、智育分是95、体育分是87、总分是96,我们可以得到这个式子:
| 98 * w1 + 95 * w2 + 87 * w3 = 96 |
从数学中解方程式的方法来说,这两个式子中一共有3个未知数,理论上只要有3个不等价的式子,就可以解出答案了。但我们恰恰只有两个学生的数据,只能凑出两个式子,也就无法用解方程的方法解决这个问题。那么这时候,就可以用到神经网络的方法来尝试解决这个问题。
搭建解决三好学生成绩问题的神经网络
理论知识
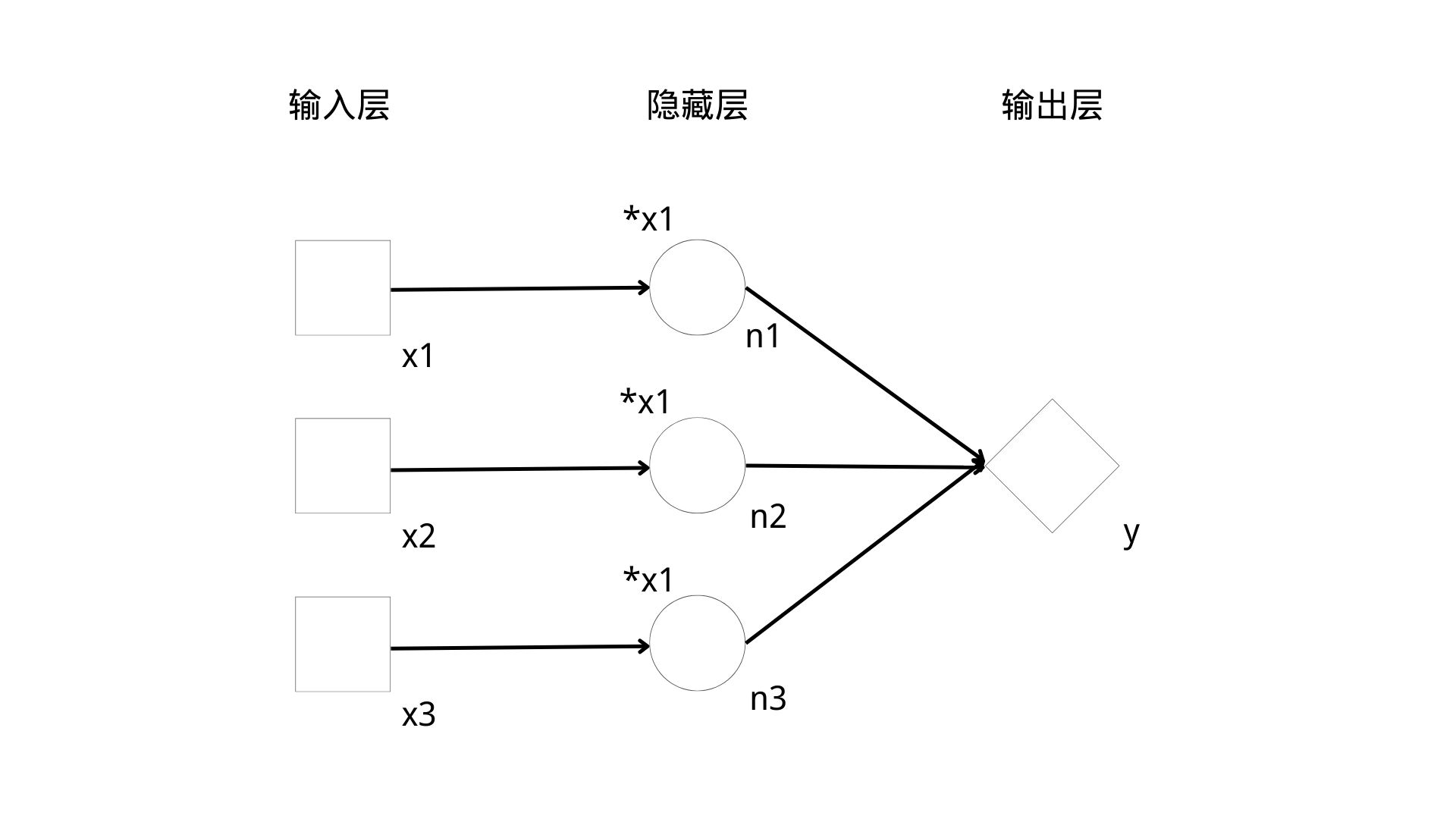
①神经网络模型图一般均包含1个输入层、1个或多个隐藏层,以及1个输出层。
②一般来说, 输入层是描述输入数据的形态的;我们用方块来代表每条输入数据的一个数 (或者叫一个字段),叫作输入节点;输入节点一般用x来命名,如果有多个数值,则用x1,x2,...,xn来代表。
③隐藏层是描述我们设计的神经网络模型结构中最重要的部分;隐藏层可能有多个;每一层中都会有1个或多个神经元,我们用圆圈来表示,叫做神经元节点或隐藏节点,有时也直接简称为节点;每一个节点都接收上一层传来的数据并进行一定的运算后向下一层输出数据,符合神经元的特性,神经元节点上的这些运算称为计算操作或操作(operation,简称op)
④输出层一般是神经网络模型的最后一层,会包含1个或多个以菱形表示的输出节点,输出节点代表着整个神经网络计算的最后结果:输出层的节点一般习惯上用y来命名,但并非必须。
⑤我们在神经网络模型图中,一般约定在各个节点的右下方(有时候因为拥挤也会在左下方)标记节点的名称,在节点的左上方标记该节点所做的计算,例如,x1、x2、x3、n1、n2、n3、y都是节点名称,“*w1”、 “*w2”、 “*w3”这些都代表节点运算。
现在我们回到模型本身,这是一个标准的前馈神经网络,即信号总是往前传递的神经网络。输入层有3个节点x1、x2、x3,分别代表前面所说的德育分、智育分和体育分。因为问题比较简单,隐藏层我们只设计了一层,其中有3个节点n1、n2、n3,分别对3个输入的分数进行处理,处理的方式就是分别乘以3个权重w1、w2、w3。输出层只有一个节点y, 因为我们只要求一个总分数值;节点y的操作就是把n1、n2、n3这3个节点输出过来的数值进行相加求和。
构建的神经网络的代码
import tensorflow as tf
# placeholder和eager execution不兼容
tf.compat.v1.disable_eager_execution()# 定义三个输入节点
x1 = tf.compat.v1.placeholder(dtype=tf.float32)
x2 = tf.compat.v1.placeholder(dtype=tf.float32)
x3 = tf.compat.v1.placeholder(dtype=tf.float32)# 定义权重(可变参数)
w1 = tf.Variable(0.1, dtype=tf.float32)
w2 = tf.Variable(0.1, dtype=tf.float32)
w3 = tf.Variable(0.1, dtype=tf.float32)# 隐藏层
n1 = x1 * w1
n2 = x2 * w2
n3 = x3 * w3# 输出层
y = n1 + n2 + n3# 会话,管理神经网络运行的一个对象
sess = tf.compat.v1.Session()init = tf.compat.v1.global_variables_initializer()# 在sess会话中运行初始化这个函数
sess.run(init)# 执行一次神经网络的计算
result = sess.run([x1, x2, x3, w1, w2, w3, y], feed_dict={x1: 90, x2: 80, x3: 70})
print(result)
# [array(90., dtype=float32), array(80., dtype=float32), array(70., dtype=float32), 0.1, 0.1, 0.1, 24.0]
代码讲解
tf.compat.v1.disable_eager_execution()需要加这个,原因是placeholder和eager execution不兼容
# 定义三个输入节点
x1 = tf.compat.v1.placeholder(dtype=tf.float32)
x2 = tf.compat.v1.placeholder(dtype=tf.float32)
x3 = tf.compat.v1.placeholder(dtype=tf.float32)定义3个输入节点,placeholder(占位符),所谓占位符,就是在编写程序时还不确定要输入什么数,而在程序运行的时候才会输入,编程时仅仅把这个节点定义好,先“占个位子”。
dtype是“data type”的缩写,表示占位符所代表的数值的类型,tf.float32是tensorflow中的32位浮点数,即用32位二进制来代表一个小数,一般32位浮点数能满足计算的需要。
# 定义权重(可变参数)
w1 = tf.Variable(0.1, dtype=tf.float32)
w2 = tf.Variable(0.1, dtype=tf.float32)
w3 = tf.Variable(0.1, dtype=tf.float32)这里用来定义每个分数的权重,在神经网络中,类似权重这种会在训练中经常性的变化的神经元参数,tensorflow把他们叫做变量。
定义w1、w2、w3的形式除了函数用的是tf.Variable函数外,其他与定义占位符x1、x2、x3的时候类似,还有一点不同是除了用dtype参数来指定数值类型,还传入了另一个初始值参数,这个参数没有用命名参数的形式,这是因为tf.Variable函数规定第一个参数是用于指定可变参数的初始值有可以看到,我们把w1、w2、w3的初始值都设置为0.1。
# 隐藏层
n1 = x1 * w1
n2 = x2 * w2
n3 = x3 * w3# 输出层
y = n1 + n2 + n3
这里定义了隐藏层和输出层。
以上就完成了神经网络模型的定义,接下来看看如何在这个神经网络中输入数据并得到运算结果。
# 会话,管理神经网络运行的一个对象
sess = tf.compat.v1.Session()init = tf.compat.v1.global_variables_initializer()# 在sess会话中运行初始化这个函数
sess.run(init)首先定义一个sess变量,它包含一个会话(session)对象,我们可以把会话简单的理解为管理神经网络运行的一个对象,有了会话对象,我们的神经网络就可以正式运转。
会话对象管理神经网络的第一步,一般是要把所有的可变参数初始化,也就是给所有可变参数一个各自的初始值,
首先让变量init 等于global_variables_initializer 这个函数的返回值,它返回的是一个专门用于初始化可变参数的对象。然后调用会话对象sess的成员函数run(),带上init变量作为参数,就可以实现对我们之前定义的神经网络模型中所有可变参数的初始化。run(init)就是在sess会话中运行初始化这个函数。具体给每个可变参数赋什么样的初值,是由我们刚才在定义w1、w2、w3时的第一个参数来决定的。我们把它设置为了0.1.
# 执行一次神经网络的计算
result = sess.run([x1, x2, x3, w1, w2, w3, y], feed_dict={x1: 90, x2: 80, x3: 70})
print(result)
# [array(90., dtype=float32), array(80., dtype=float32), array(70., dtype=float32), 0.1, 0.1, 0.1, 24.0]
result = sess.run([x1, x2, x3, w1, w2, w3, y], feed_dict={x1: 98, x2: 95, x3: 87})
print(result)
# [array(98., dtype=float32), array(95., dtype=float32), array(87., dtype=float32), 0.1, 0.1, 0.1, 28.0]这里我们进行了真正意义上的的计算,sess.run函数的第一个参数为一个数组,代表我们需要查看哪些结果项;另一个参数feed_dict,代表我们要输入的数据。
结果如下
# [array(90., dtype=float32), array(80., dtype=float32), array(70., dtype=float32), 0.1, 0.1, 0.1, 24.0]# [array(98., dtype=float32), array(95., dtype=float32), array(87., dtype=float32), 0.1, 0.1, 0.1, 28.0]经过验算:
90*0.1+80*0.1+70*0.1=24
98*0.1+95*0.1+87*0.1=28
正确,说明我们搭建的神经网络计算的结果是正确的。
后续进行训练神经网络,敬请期待......
这篇关于深度学习(初识tensorflow2.版本)之三好学生成绩问题(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




