本文主要是介绍【转载】Swift里的CAP理论和NWR策略应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自:http://blog.sina.com.cn/s/blog_57f61b490101a8ca.html
最近有人讨论到swift副本数是否能够调整,3副本成本过高,如果改成2副本怎么样?多聊了几句以后发现不少人可能都是望文生义,简单的认为副本数只是多一个少一个Copy的问题,并不了解背后的理论依据。所以想写个简单的介绍,普及分布式系统设计的一些基础知识点。这个是按傻瓜版写的,已经知道的同学请自动无视。
不同于传统的集中式存储,对于分布式存储系统来说,因为自身的复杂性,副本数并非简单拍脑门而来,需要找到理论支撑,它的依据实际上是来自于CAP理论和基于其上的NWR策略。
CAP 理论是由UC Berkerly的Eric Brewer(没错,他也叫Eric,哈哈)在2000年提出的,当时是一个猜想,2年后被MIT的两个家伙证明为理论,很快被互联网大企业们(Ebay,Twitter,Amazon等)接受和拥护,到如今已经13年,成为了分布式系统设计的经典理论之一。
CAP的主要思想是“C,A, P三者不可得兼,舍一而取二者也”。这就像找对象,如果你想找到一个真实存在的女朋友,你必须先明白没有人是完美的,分布式系统也这样。
C = 一致性 (Consistency) :保证得到的都是完成状态的数据,否则直接失败。
原文是A service that is consistent operates fully or not at all,要么完整得到一个原子性操作,要么闹太套(哈哈,开个玩笑)。这个要求像个专一的妹纸,一次只和一个人谈,没什么牵扯不清的中间状态。意味着系统给出去的数据必须保证是原子操作的合格品,否则直接不给,坚决不能给半成品。你不会拿到一张被另外一个请求画了一半的图,或者是更新了上半段的说明书。
A = 可用性 (Availability) :在容忍的响应时间内,每个操作总是能够返回,不会出现所谓in_flight IO,总是能及时响应。这意味着一个好脾气的妹纸,永远一分钟内反应。就是不想理你,她也会马上回答“我不想理你”而不是玩冷战,问她在吗?半天没声音。系统总能在指定时间段(例如15秒)内给你反馈,要么给你数据,要么告诉你失败鸟,不会告诉你正在处理中,然后把你撂一边自己下班了。
P = 分区容忍性 (Partition Tolerance) :能够保证系统是分区的。
原文是这样No set of failures less than total network failure is allowed to cause the system to respond incorrectly,比较难理解,简单的解释一下这是个反证,除非整个分布式系统所在的网络都挂掉,只要还有分区就能给出正确响应。这意味着一个会到处出没的妹纸,她可能在家,可能在office,可能在外面happy,但只要任何一个地方能上网,她就能给你反馈。(有人说那多个地方同时出现算什么,那只能说明你很花心,同时和好几个妹纸交往,她们互相之间还不反感,能够配合互为备份)这第三种特质比较罕见也比较难搞,这大概也就是跨分区(设备)的系统吸引人的地方吧。
CAP定理告诉我们,同时具有这三种特质的妹纸和分布式系统都是不存在的,你必须在其中做取舍。
Amazon于是写了个论文,描述了一下如果取舍的具体策略,具体到副本数怎么设定,这就是NWR。
N = 副本数
W = 一次成功的写操作必须完成的写副本数
R = 一次成功的读操作需要读的副本数(是的,随便读一个副本是不行的,你必须读到一定数量的副本,再相互比较取最新的数据)
策略来说就有具体的公式可供运算,有两个:
W > N/2
W + R > N
我们结合Swift的设定,N=3,W=2,R=2(or 1),来看看这两个公式是什么意义。
分布式系统通常用来处理大并发请求的应用,很多请求大家同时来,有一堆在读,也有一堆想写。
假设有一个数据拥有三副本,每个副本已经同步好,原来的值都是A
我们看看如果不需要满足公式让W小于3/2,也就是W=1的情况下会出现什么问题,W=1,意味着每个写的请求只要写完一个副本即可成功返回。
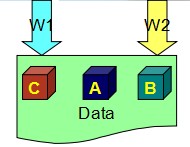
假设两个进程同时来更新这份数据,进程W1要把值改写成C,进程W2要把值改写成B,那就有可能出现下图的情形,两个进程各拿到一个副本改写,都认为自己的写操作是成功的,结果却留给系统三个不同的副本,这样就出现数据副本不一致的问题。
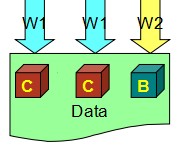
所以公式W> N/2, 实际上变成了一个写的锁,意味着只有写了过半数副本的才算写成功,拿不到的就返回失败,解决了竞争的问题。如下图,W1的会话成功,W2的会话就返回失败。
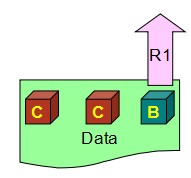
W> N/2,同时意味着不需要把所有的副本都写完,未完成的留给系统自己后台慢慢同步,那这个时候问题就来了,一个新的会话过来读数据的时候,分配到的副本有可能是没来得及更新的。这时候R1读回去的就是过时的数据B,而非最新的数据C
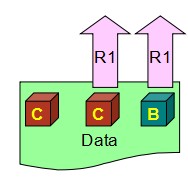
第2个公式变形下就是R> N-W,R=2就避免正好倒霉读到没更新的那一个。这样读回去C和B两个数据,再比较后取最新的C。所以W+R> N 能够保证每个读的请求至少读到一份最新的数据,
所以你也许已经琢磨出来,这两个公式更加强调一致性,在可用性上是有所保留的。
当然NWR还可能取其他值,不同的取值代表了不同的倾向。如果设定N=3, W=3, R=1,那么强调的是一致性,写数据的时候一定要把所有副本都刷新,杜绝中间状态,这样一致性得到很好保证;如果N=3, W=1, R=1,那强调的是可用性,这种情况下一致性是被牺牲掉了,所以上面两个保证一致性的公式在这种情况下就不再适用。之所以可用性提高是因为读和写都放低了要求,只要完成一个副本即可,这样完成时间降低,响应速度是更快的。
N=3, W=2, R=2是一种折中的策略。其实Amazon的Dynamo就是采用的这个参数,据说Swift是照搬S3的。
所以回到Swift的副本设定来看,swift的NWR值是可调的,有两种配置,一种是标准的N3W2R2,但是实际上你也可以使用N3W2R1,这个更实用点。在这种配置下,虽然一个数据拥有三副本,但是容错上读写是不一样的。网络断线,硬盘故障等意外造成一个副本失效时, 系统仍然可读可写,但两个副本失效时,受影响的这部分数据系统就变成只读,无法再写了。
CAP理论和NWR策略在大规模系统下是比较合理的,除了被用来设计分布式存储之外,也用来设计分布式数据库,比如很热的NOSQL。另外,这个理论问世已经不短的时间,也经常看到有人发文要挑战他,也有一些吐槽等等,那个是另外的话题,这里就不再继续了。
最近我一个朋友在网上购物,遇到一件有意思的事,某电商有个特价抢购,是个手机移动电源,他就很happy下了单,结果第2天送来了两瓶酱油。回头看订单详情,明明还是移动电源。再看促销,原来的促销已经变成了酱油。我们可以用前面的理论模拟下问题是如何产生的。朋友在查看商品的时候,他的这个会话,假设读到的库存数据是1,意思就是有货,就放到购物车里了。但同时估计也有很多人在查询,读到的数据都是1,大家都认为有货。除了我朋友,至少还有一个人也下了单,下单就需要后台需要将这个库存数据减去1,常见的逻辑应该是改写库存成功才能生成订单。如果设定的W是1,那么两个会话就会有机会都认为自己成功,两个订单同时生成,但货只有一个了,导致问题出现。
至于如何变成酱油的,我不太想猜测,这件事本身实在是太搞笑了,我想起他拆开包裹的样子就想笑哈哈哈。
这篇关于【转载】Swift里的CAP理论和NWR策略应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





