本文主要是介绍OB SQL引擎和存储引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一 SQL引擎
- 1.1 双模共存
- 1.2 基本操作
- 1.3 查看SQL的执行计划
- 二 存储引擎
- 2.1 传统数据库存在的问题
- 2.2 LSM-Tree存储
- 2.3 OceanBase转储和合并
- 2.4 控制内存数据落盘
- 2.5 LSMTree存储压缩
- 三 备份恢复
- 3.1 物理备份系统架构
- 3.2 物理恢复系统架构
一 SQL引擎
1.1 双模共存
SQL引擎支持MySQL和Oracle兼容模式
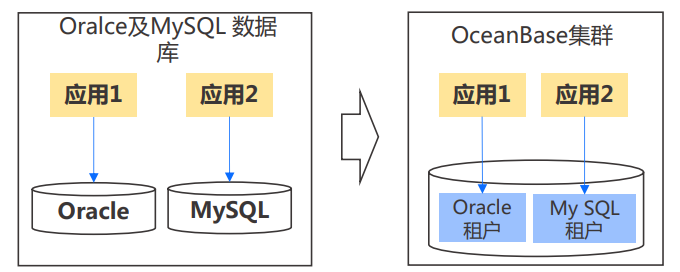
- 同一个集群,同时支持mysql和oracle
- 租户创建时需要配置为MySQL兼容模式或Oracle兼容模式
- DBA由原来维护“多个数据库产品”变为维护一个“统一的数据库产品”,DBA可以结合应用需求,创建不同兼容模式的租户
MySQL兼容模式
- MySQL 5.6语法全兼容
- 兼容MySQL通信协议,MySQL应用可直接迁移至OceanBase
Oracle兼容模式
- 兼容Oracle 11g语法
- 支持90%的Oracle数据类型和内置函数;还在持续完善中
- 支持分布式执行的存储过程(PL/SQL)
1.2 基本操作
- 有关增删改查的基本操作,与sql语法内容一致,可以直接使用Mysql、Oracle的基本操作,这里不再赘述
- OceanBase官网包含MySQL模式和Oracle模式的开发者文档和SQL参考文档
1.3 查看SQL的执行计划
- 查看SQL的执行计划-EXPLAIN命令
explain [extended] <sql statement> \G
- 使用非常方便,无需创建单独系统表,可直接获取语句的执行计划
- extended选项会产生更多详细内容,排查执行计划问题时建议指定
- 命令的输出格式和Oracle数据库的EXPLAIN工具比较接近,可读性好
- 只获取执行计划,并不真正执行
二 存储引擎
2.1 传统数据库存在的问题
传统数据库有随机写、写放大等问题
- 大量随机写:buffer pool和表空间页面“一一对应”,数据更新时会在磁盘上产生频繁的随机写(check point)
- 写放大:随机写导致SSD的写放大问题,影响性能及磁盘寿命
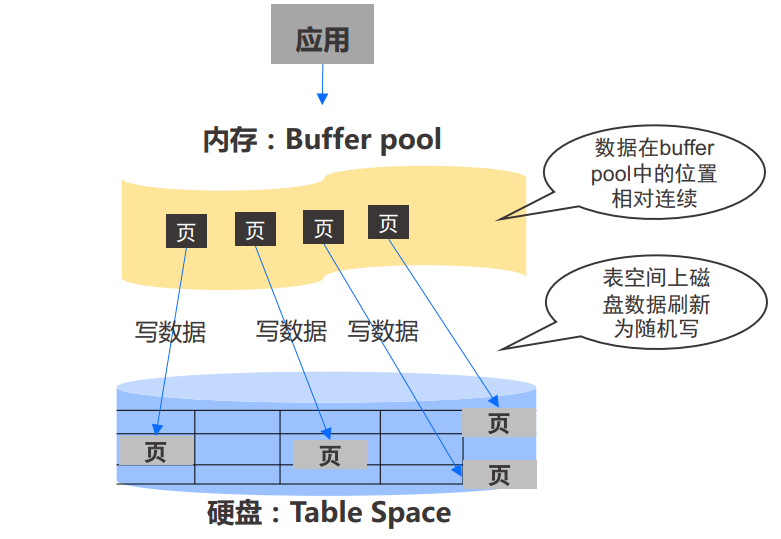
读数据 - 如果buffer Pool中有,则直接从内存读,如果没有,则从硬盘中提取到buffer pool中
- 可以提升热数据的读取速度,减少时延
写数据 - 修改数据时,先将数据写到buffer pool,再刷新到磁盘
- 通过check point将脏数据刷新到硬盘中,造成随机写和写放大:数据页离散分布,造成大量随机写,延迟大,影响性能;SSD上的随机写会导致严重的写放大,不仅影响写操作性能,而且显著降低SSD的寿命;一般使用高端读写型的SSD
2.2 LSM-Tree存储
- 准“内存数据库”+ LSM-Tree存储,避免随机写
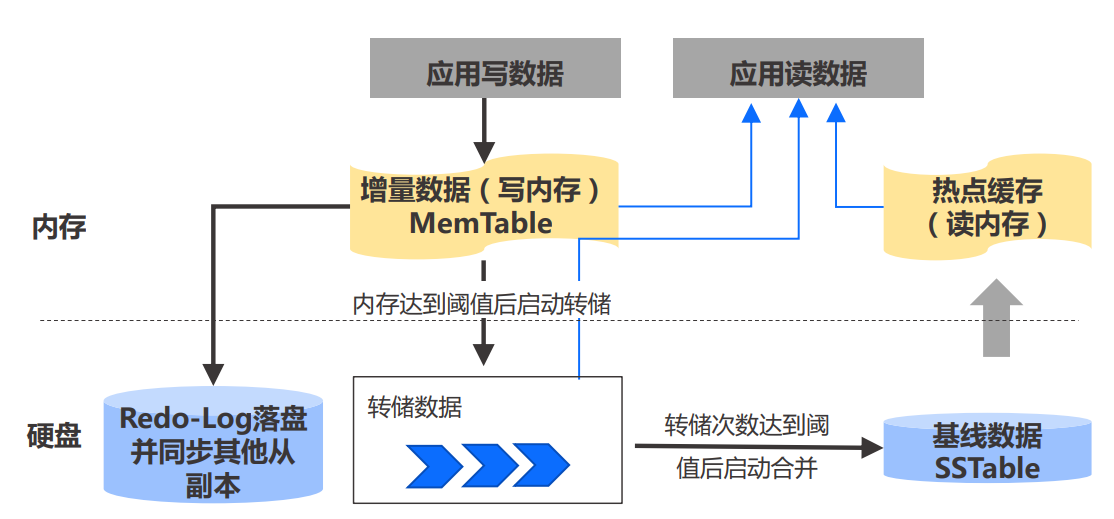
- 增量数据直接写入内存,并将Redo-Log落盘及同步给从副本后,即可通知业务成功
- 内存占用率达到阈值后冻结MemTable,并执行转储/合并等操作以释放内存空间
- 内存增量数据批量合并到磁盘,以顺序写代替随机写
- 读数据时,需要从热点缓存、MemTable以及转储SSTable中读取数据,保证数据一致性
技术优势 - 读写分离:读内存和写内存分开
- 提升写速度:准内存处理,数据修改主要是内存操作,无频繁 check point操作,提高写性能
- 避免随机写:内存的脏数据批量合并之后,顺序写入SSD硬盘,避免随机写,提高写性能并延长SSD寿命
- 数据持久性:为避免内存中数据丢失,redolog以WAL机制实时落盘,保证数据持久
- 降低成本:磁盘数据按主键有序排列,磁盘碎片少,并提供快速检索能力。使用普通读密集型SSD硬盘
- 底层存储会划分微块(micro block)和宏块(macro block),由数据库内部管理
2.3 OceanBase转储和合并
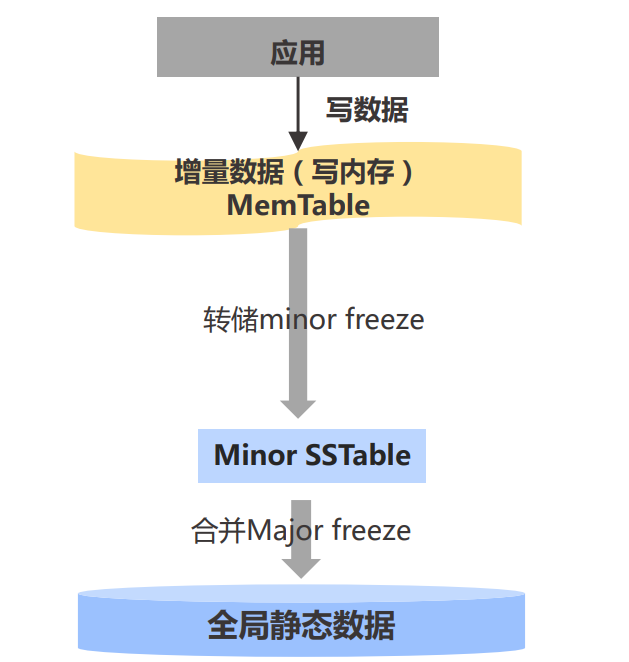
转储操作(minor freeze)
- 是不断的把内存的 MemTable 写入磁盘以释放内存空间
- 转储过程首先会冻结 MemTable(阻止当前的 MemTable 再有新的写入),并生成新的活跃 MemTable
- Partition 副本可以独立决定冻结当前 MemTable,并转储到磁盘上
- 转储出的数据只与相同大版本的增量数据做数据归并,不与全局静态数据合并
合并操作
- 将动静态数据做归并,会比较费时。当转储产生的增量数据积累到一定程度时,通过Major freeze实现大版本的合并
磁盘数据按主键有序排列,提供快速检索能力。内存增量数据(MemTable)分多级做批量归并(Minor-Major),最终整合到磁盘
(SSTable),对整体性能影响较小
- 转储和合并的最大区别:合并是集群上所有的Partition在一个统一的快照点和全局静态数据进行合并的行为,是一个全局的操作,最终形成一个全局快照
| 转储(Minor freeze) | 合并(Major freeze) |
|---|---|
| Partition 级别,只是 MemTable 的物化 | 全局级别,产生一个全局快照 |
| 每个 Partition 独立决定自己 MemTable 的冻结操作,主备 Partition 无需保持一致 | 全局 Partition 一起做 MemTable 的冻结操作,要求主备 Partition 保持一致 |
| 转储只与相同大版本的 Minor SSTable 合并,产生新的 Minor SSTable,所以只包含增量数据,最终被删除的行需要特殊标记 | 合并会把当前大版本的 SSTable 和 MemTable与前一个大版本的全量静态数据进行合并,产生新的全量数据 |
2.4 控制内存数据落盘
触发memstore内存dump操作的阈值
- freeze_trigger_percentage参数;默认值是70,即memstore的内存写满70%时,自动触发转储或者合并,具体行为取决于参数设置
转储(minor freeze)的时机
- 内存达到阈值后自动触发
- 手工触发:以root@sys用户执行
alter system minor freeze;命令
合并(major freeze)的时机
- 定时合并:由
major_freeze_duty_time参数控制,默认值是"02:00" - 手工触发:以root@sys用户执行
alter system major freeze;命令 - 转储次数已满:当转储次数已经达到major_compact_trigger参数指定的次数时,自动触发合并;值为0时则关闭转储,直接触发合并
支持轮转合并,多个Zone按次序合并
关闭合并
- enable_major_freeze = False; 建议保持默认值True
- enable_manual_merge = True; 开启手工合并,需要手工触发所有的合并操作。极少数特殊运维场景会用到,不建议使用
合并的并发线程数 - merge_thread_count参数控制并发度,并发的粒度为分区
- 默认值是0(系统自动判定并发度),值过大可能会影响在线业务性能
- 数快速写内存场景(如批处理)中,可以适当调大并发度,加快内存dump的速度
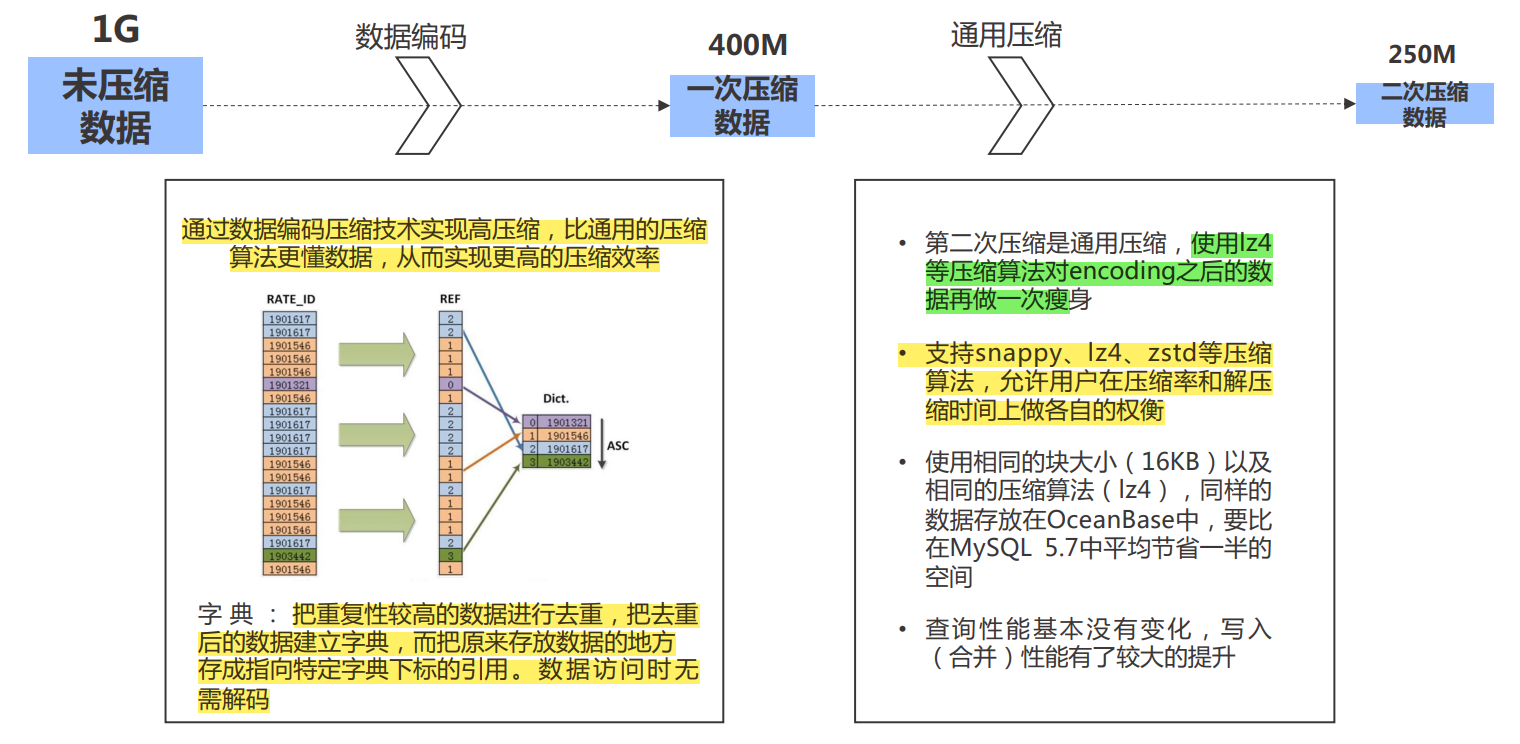
2.5 LSMTree存储压缩
- LSMTree存储高数据压缩率,降低存储需求
三 备份恢复
3.1 物理备份系统架构
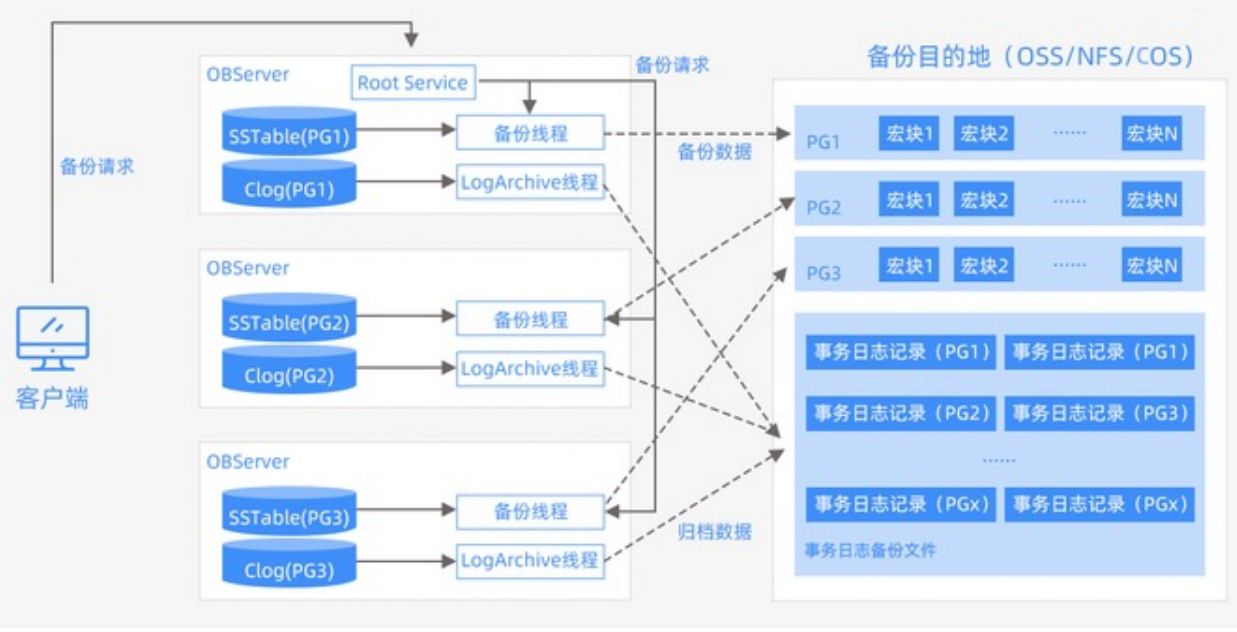
- 支持 OSS、NFS 和 COS 三种备份介质,提供了备份、恢复、管理三大功能。支持手动删除指定的备份和自动过期备份的功能
- 物理备份由数据备份和日志归档两个功能。数据备份指备份基线数据,包括全量备份和增量备份;日志归档指日志数据的自动归档功能
3.2 物理恢复系统架构
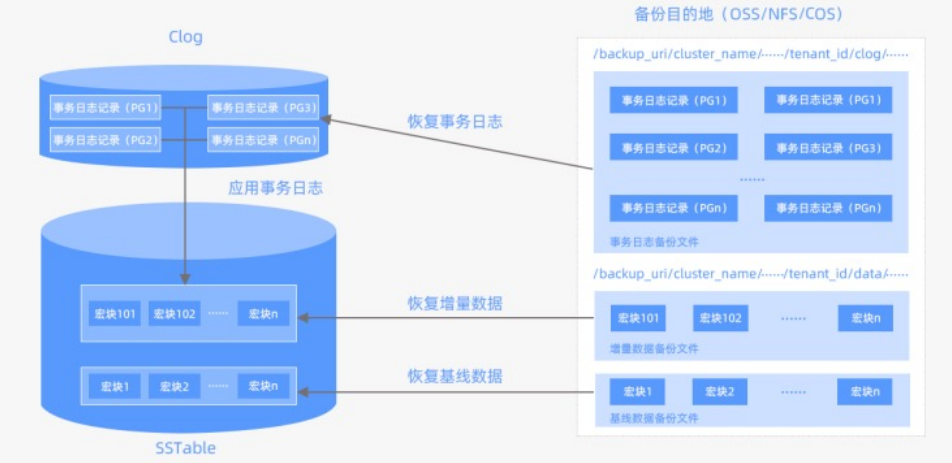
- 支持租户级别的恢复,恢复是基于已有备份数据重建新租户的过程。用户只需要一个
alter system restore tenant命令,就可以完成整个恢复过程 - 恢复过程包括租户系统表和用户表的Restore和Recover 过程。Restore是将恢复需要的基线数据恢复到目标租户的OBServer,Recover是将基线对应的日志恢复到对应OBServer
这篇关于OB SQL引擎和存储引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







