本文主要是介绍MPP架构和分布式架构的区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:对大数据的数据处理需求,当前技术方向上存在两个不同的发展路线,MPP和分布式处理。两者数据处理的基本思路都是一样的,分布式并行处理再合并结果;但由于二者在处理架构上的差异,最终产品在应用需求性能侧重也有所不同。
一、分布式架构和MPP架构分析
两种技术都是通过对大量普通机器的的一同使用,而达到了大数据处理的需求;只是二者在管理任务执行时,对磁盘、内存和CPU的使用方式不同,而造成了最终在应用上的特性差异。
1.1分布式架构分析
从分布式架构路线发展的技术有:Hadoop、Hive、Tez、Spark、Flink等;核心思想基本都是从HDFS+Yarn+MapReduce这套数据处理方案中延展出来的;
分布式处理在技术架构上有什么特点呢 ?
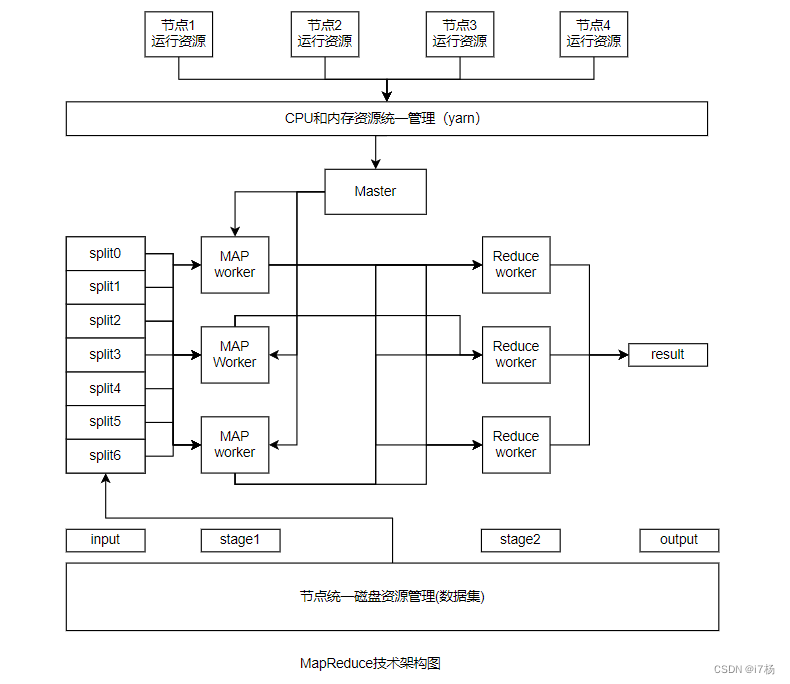
以MapReduce的技术架构为例,如何使用多台机器节点,做分布式数据处理:
首先是数据存储方面,每个机器都有自己的磁盘,数据可以存储到每个节点的磁盘上,但是对数据和磁盘存在的关系映射缺少管理;传统单机使用Raid(磁盘矩阵)将多块磁盘合成一块,HDFS的设计思想扩展到集群节点的所有磁盘,将所有节点的所有磁盘做了一个类似的大Raid,将所有的存储资源整合到一起管理,数据存储到HDFS时,会使用所有的磁盘资源保障存储数据的安全、稳定和容错;
然后是运行资源这块,yarn使用NodeManger将每个节点运行时资源管理起来,使用ResourceManager统筹所有计算资源,当任务运行时,将内存和CPU资源自定义分配给运行任务;
最后是数据处理任务,MapReduce调用yarn分配的资源,将数据从HDFS上按分片(split)读到内存,按照分配的内存和CPU数量,按照MapReduce的任务分成多个小任务,将Map阶段多个计算任务处理落盘,Reduce再读盘将结果合并,输出分布式计算的最终结果。
MapReduce的数据处理的分布式架构如下:
后续按照分布式数据处理路线发展的技术,就是按照内存磁盘的使用效率、计算逻辑的处理性能以及使用简便性上做的优化,存储上从存储格式、压缩效率上优化;计算上优化内存磁盘的交互,与shuffle的管理;CPU上使用单机线程的计算方式,没有太大区别。
1.2 MPP架构分析
1.2.1 MPP介绍
MPP (Massively Parallel Processing),意思是大规模并行处理。
这个架构有几个基本特性:
- 支持数据处理并行执行;
- 资源私有,每个节点都有独立的磁盘和内存资源;
- 分布式计算,在私有内存中计算完后,直接写入私有的物理磁盘;
- Shared Nothing,每个节点资源都是独立的,不存在分布式架构统筹资源的概念;
MPP的数据处理的架构如下:

总结下来就是,MPP + Shared Nothing的分布式架构;
单节点将磁盘和内存分为多个私有部分,集群将每个节点的内存和磁盘当作私有资源,将CPU资源公用,然后靠CPU并行处理和私有资源处理,加快数据处理速率。
1.2.2 MPP架构发展历史
MPP路线的发展路线:从单机MPP到大数据领域的MPP应用;
单机MPP中间件:最开始PostgreSQL、Teradata部署在单机节点上;将磁盘上的数据集和内存分成多个私有资源,然后通过多CPU核并行计算的方式,加快一个数据集数据的计算速率,最后由控制线程汇聚结果;
集群MPP:后来大数据领域引入了MPP技术思想,并做了架构上的调整,将单机上划分小的数据集和内存,扩大到私有节点独自的磁盘和内存资源;
其中的先驱就是Greenplum,基于PostgreSQL研发了集群版本的MPP;在应用过程中依然有不如意的部分,后续又有多个技术团队,分别基于不同应用需求,研发了如impala、TITB、ClickHouse、Doris、StarRocks等大数据场景的MPP数据库。
二、分布式架构和MPP架构的应用
2.1 数据处理场景有哪些应用需求
大数据全生命周期包括,数据集成,数据处理,数据存储,数据分析,数据展示;对于分布式和MPP,相似的应用需求在数据处理和数据分析;
分布式处理需要经历读数据,处理数据,shuffle落盘,读数据处理,合并前阶段计算,结果数据落盘这五个阶段,大量的落盘读内存和shuffle操作,导致分布式处理的操作在秒级别;
MPP处理,只需要在每个节点将数据读到内存,在内存并行计算后,将计算结果汇总到管理节点,将结果计算汇总输出就行,整个过程从读到处理展示结果可以到亚秒级;
2.2 应用场景分析
从一个任务周期的视角去看,MPP仿佛优于分布式架构的性能;但是从一个任务的生命周期跳出来从架构的视角去看。
分布式每次计算需要大量准备,但是它把资源,磁盘和计算逻辑都单独解耦出来,对于灵活性和可移植性上有天然的优势,可以在分布式架构中做各种MPP架构无法处理自定义存写算的操作。
MPP架构将功能包装到管理进程,能提供什么功能,只有先开发包装再使用;好在是大数据的应用需求场景基本是固定的,所以这种可能,有技术团队可以把90%的功能都集成到MPP数据库管理功能中;解决自定义包装的问题和扩展节点、磁盘存储等突破磁盘存储限制,但是MPP架构在数据处理的时候,本身对CPU和内存的使用方案,导致难以做到分布式弹性的资源隔离,多个并发任务读写操作的时候,同样的节点,分布式处理的稳定性和并行任务处理数优于MPP架构技术产品。
2.3 应用总结
大数据技术栈目前依然没有哪一种技术能覆盖所有应用场景,依然有可用性和性能等问题,对于分布式架构和MPP架构两条路线发展的数据处理技术能力,特性上各有优势。
从大数据需求的各个模块来看:
- 分布式框架在做大数据基础存储和处理阶段更有优势,如:数据集成,数据开发,预计算,安全,洞察等;
- MPP架构在数据应用层更有优势,如:统计、单点查询等。
技术的应用不能统一而论,技术的应用和成本、熟悉度、简易性等各种非技术架构原因也会影响技术的选择,但总体来说两种架构本身不一样,虽然解决的应用场景有重叠,发展到后期,依然有合并的可能,将彼此最优秀的特性合并到一个系统中。
这篇关于MPP架构和分布式架构的区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





