本文主要是介绍解决两大难题,TDengine 助力亿咖通打造自动驾驶技术典范,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小 T 导读:在安全解决方案 SuperCloud 中,亿咖通面临着磁盘占用量大、车辆最新状态实时查询难以实现两个核心问题。最终,他们选择了让 TDengine Database 承担数据中台的重要角色,负责车辆实时数据的写入、存储以及实时查询。本文讲述了研发团队在前期使用 Apache HBase 时遇到的具体难点、为什么没有坚持选择 OpenTSDB,以及选择 TDengine 的过程和成效。
企业简介
亿咖通科技是一家汽车智能化科技公司,在武汉、杭州、上海、苏州、马来西亚吉隆坡、英国伦敦等国内外多地设立有分支机构和研发中心,致力于持续打造行业领先的智能网联生态开放平台,全面为车企赋能,创造更智能、更安全的出行体验。
项目介绍
为实现高水准的自动驾驶能力,亿咖通科技(ECARX)打造了一整套安全解决方案 SuperCloud,该方案旨在利用人工智能技术以及摄像头、雷达、声纳等多种传感器技术来保证驾乘者的安全。自动驾驶的核心数据就是设备的影子数据和状态数据,对设备进行精准的数据控制和采集,再结合高精地图的数据,是完成自动驾驶的两个重要环节。值得一提的是,亿咖通也是目前国内为数不多的拥有高精地图资质的企业。
在 SuperCloud 项目当中,TDengine Database 承担着数据中台的重要角色,负责车辆实时数据的写入、存储以及实时查询。
选型经过
在此之前,我们使用的存储架构是 Kafka + Flink + HBase,但随着业务的发展,逐渐发现 HBase 的 Key-Value 存储模型并不适合我们的场景,究其原因,是因为落地到数据库的都是结构化的数据,Key-Value 存储模型会导致磁盘占用量特别大,并且性能上也无法实现车辆最新状态的实时查询,这也是亟待解决的两个核心问题。
经过调研,我们发现时序数据库才是正确的选择方向,而且核心数据也符合时序数据的种种特点,因此,我们决定在 InfluxDB、TDengine 和 OpenTSDB 之间进行产品选型。
事实上,一开始我们选择的是 OpenTSDB,因为它基于 HBase,所以我们很方便上手。但成也萧何败也萧何,也正因为要依赖 HBase,OpenTSDB 并没有解决 HBase 遗留的性能、压缩率等问题。而 InfluxDB 由于单机性能并不够卓越,而且集群功能没有开源,所以也没有被采纳。最终经过各种维度的对比后,我们毅然选择了国产、开源、支持 SQL 的时序数据库 TDengine。
TDengine 非常符合我们现在的业务场景,尤其是超级表的概念,甚至可以说是为我们量身定做的。我们为每辆车都分配了一个子表,用以接收 IHU 设备产生的数据。(注:IHU 是亿咖通投入研发的第一代整车计算平台产品,于 2017 年第二季度投放市场使用,是一款采用车载专用处理器、基于车身总线系统和第三方应用服务打造而成的多媒体娱乐系统,能实现包括地图导航、多媒体娱乐、车辆信息等一系列信息娱乐功能及车联网服务。)
优化后的新架构为:Kafka + Flink + TDengine。Flink 上游的数据可分为 2 类,一类是用 json 存储的结构化数据,还有一类是如图片、视频一类的非结构化数据。上游如果是结构化的 json 数据,则通过如下链路写入 TDengine:Kafka—>Flink—>TDengine,如果是非结构化的数据,则会直接存储到 S3 上,然后把这些视频图片的文件路径通过如下链路写入 TDengine:S3—->Kafka —-> Flink—>TDengine。
搭建与效果
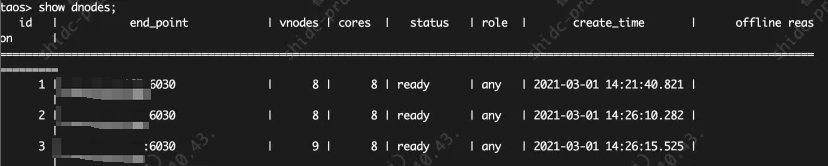
我们以单副本模式落地了一个三节点的集群,机器配置为 8C + 16G + 500G 机械硬盘,备份用其他方式完成。当前环境下有 3 张超级表、276571 张表。
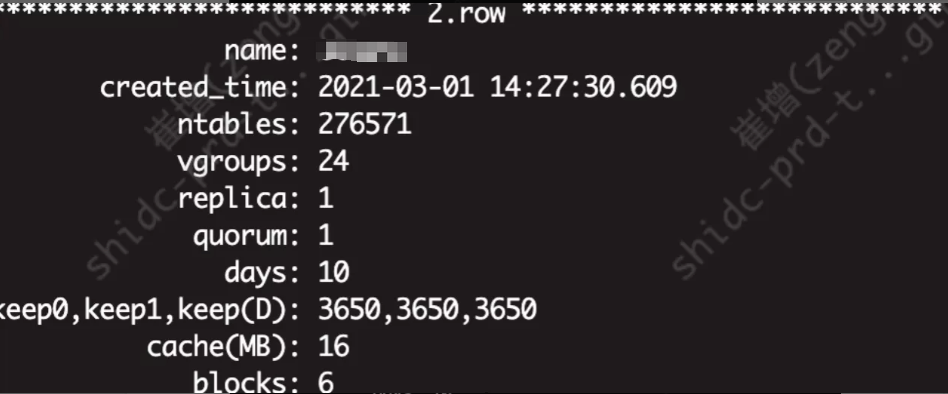

超级表表结构如下:
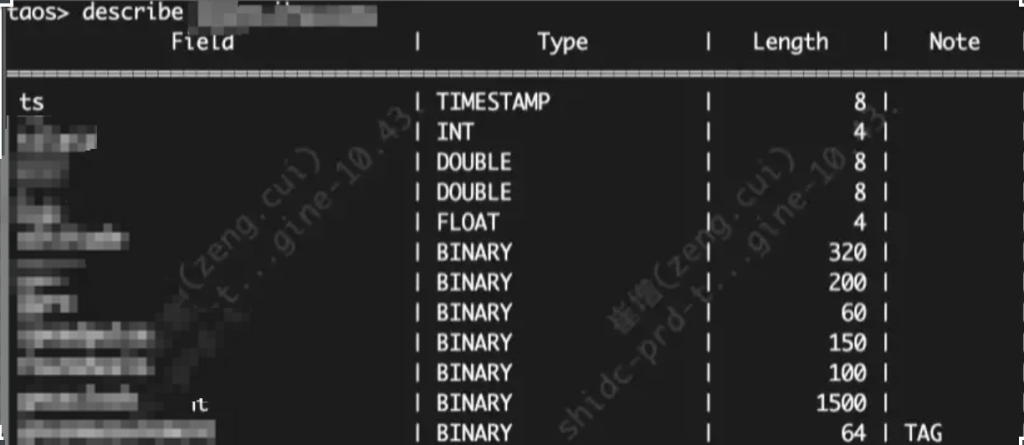
由于我们的 json 较大,所以选择使用 protobuf 进行压缩后再写入 TDengine,这样只需要 1500 字节的长度就可以容纳该类 json,取出进行反序列化后以供使用。
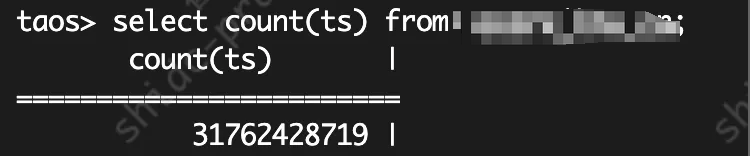
当前最大的一张超级表已经存有 300 多亿条数据,每行 2362 字节。粗略估算,项目运行至今,总数据量大概有 68T 左右,但实际的磁盘占用量只有 1.4T,以前 20 天就能写满 15T 的磁盘,但现在基本已经不再需要考虑磁盘的问题了。资源使用率相比以前节省了近百倍。

此外,困扰我们许久的数据实时查询问题也有望得到解决,TDengine 的 last 函数可以实现毫秒级返回设备最新状态。由于我们当前使用的版本还是比较老旧的 2.0.18,这一版还没有针对 last 函数的缓存,TDengine 的工作人员表示后续会有针对这个函数专门的优化,等日后版本升级后再做体验。 最常用的查询车辆实时位置的 SQL 是这样的,全部都是毫秒级别返回结果:

写在最后
总体而言,TDengine Database 的独特设计帮助我们解决了传统架构磁盘存储占用过高,以及性能上不能支持车辆状态实时查询这两大痛点,在实现降本增效方面名副其实。不止如此,我们后续要实现的设备统计需求也在应用 TDengine 之后得到了解决。在 TDengine 的官方社区中,所提出的问题也都可以得到支持人员的快速反馈,事无巨细,这帮我们极大降低了项目落地的难度。 TDengine 的应用,不仅完全解决了我们当前业务上存在的痛点,也匹配上了后续业务发展的需求。随着业务的快速发展,我们希望和涛思数据后续可以在更多维度上通力合作,共同打造自动驾驶的行业技术典范。
想了解更多TDengine 的具体细节,欢迎大家在GitHub上查看相关源代码。

这篇关于解决两大难题,TDengine 助力亿咖通打造自动驾驶技术典范的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






