本文主要是介绍AI绘画风格化实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在社交软件和短视频平台上,我们时常能看到各种特色鲜明的视觉效果,比如卡通化的图片和中国风的视频剪辑。这些有趣的风格化效果其实都是图像风格化技术的应用成果。
风格化效果举例
MidLibrary 这个网站提供了不同的图像风格,每一种都带有鲜明的特色。
MidLibrary
它总共包含了以下几大类别的样式:
- 艺术技法(Artistic Techniques):367种
- 艺术流派和题材(Genres + Art Movements):286种
- 标题(Titles):256种
- 画家(Painters):1308种
- 插画师(Illustrators):820种
- 摄影师(Photographers):637种
- 各种艺术家(Various Artists):254种
- 雕塑家和装置艺术家(Sculptors + Installation Artists):212种
- 设计师(Designers):145种
- 时装设计师(Fashion Designers):125种
- 导演(Filmmakers):104种
- 建筑师(Architects):100种
- 街头艺术家(Street Artists):57种
- 版画家(Printmakers):34种
总共有4705种不同的艺术风格被收录在这个库中。从具体的艺术家,画派,题材等多个维度对 Midjourney 的图片风格进行了分类和汇总,可以说是非常全面和系统的一个Midjourney样式参考库。这对使用Midjourney的用户来说可以提供很大的便利和灵感。



图生图代码实战
关于图生图背后的原理,前面文章有讲过。在 ControlNet 提出之前,我们在各种短视频平台上看到的图像风格化效果,大多是使用图生图的方法来完成的。我们简单回顾一下图生图背后的原理。在图生图中,我们对原始图像进行加噪,通过重绘强度这个参数控制加噪的步数,并把加噪的结果作为图像生成的初始潜在表示,然后使用你提供的 prompt 来引导输出图像的风格。
AI绘画Stable Diffusion关键技术解析
import requests
import torch
from PIL import Image
from io import BytesIOfrom diffusers import StableDiffusionImg2ImgPipelinedevice = "cuda"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("zhyemmmm/ToonYou")
pipe = pipe.to(device)url = "https://ice.frostsky.com/2023/08/26/2c809fbfcb030dd8a97af3759f37ee29.png"#
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((512, 512))prompt = "1girl, fashion photography"images = []# 我们的重绘强度分别设置为0.05, 0.15, 0.25, 0.35, 0.5, 0.75
for strength in [0.05, 0.15, 0.25, 0.35, 0.5, 0.75]:image = pipe(prompt=prompt, image=init_image, strength=strength, guidance_scale=7.5).images[0]images.append(image)
1.导入需要的库:requests用于网络请求,torch为深度学习框架,PIL用于图像处理,BytesIO用于在内存中读取网络图片。
2.初始化Stable Diffusion的图片到图片模型,加载一个预训练的卡通化模型。
3.定义设备为GPU。将模型加载到GPU上。
4.定义网络图片URL,发送请求获取图片,读取为PIL Image格式。调整图片大小为512x512。
5.定义prompt,表示目标风格,这里是"1girl, fashion photography",意为单人女性时尚照。
6.定义一个空列表images,用于保存生成图片。
7.循环生成图片:分别设置不同的strength参数,代表噪声重绘强度,值越大表示风格迁移越完整。调用模型pipe生成图片,添加到images中。
8.循环结束后,images列表中即为不同程度风格迁移的图片。

ControlNet-使用边缘轮廓条件
我们仍旧以蒙娜丽莎的图片为例,分别使用 SDXL 模型的 Canny 控制模式和 SD1.5 模型的指令级修图控制模式。
首先,我们可以加载蒙娜丽莎的图片,并使用 Canny 算子提取图片的轮廓线。
# 加载原始图片,这里你也可以使用自己的图片
original_image = load_image("https://ice.frostsky.com/2023/08/26/2c809fbfcb030dd8a97af3759f37ee29.png").convert('RGB')# 提取Canny边缘
image = np.array(original_image)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
image = Image.fromarray(image)

然后,我们使用 SDXL-1.0 模型和 Canny 控制条件的 ControlNet 模型。
# 加载ControlNet模型
controlnet = ControlNetModel.from_pretrained("diffusers/controlnet-Canny-sdxl-1.0-mid", torch_dtype=torch.float16) # 加载VAE模型
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)# 创建StableDiffusionXLControlNetPipeline管道
pipe = StableDiffusionXLControlNetPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, vae=vae, torch_dtype=torch.float16)# 启用CPU卸载加速
pipe.enable_model_cpu_offload()# 后面可以通过pipe生成控制网络图
完成这些准备工作后,我们就可以通过prompt来控制生成图像的风格了。例如可以使用下面4条prompt,依次将蒙娜丽莎图像转换为卡通风格、梵高风格、赛博朋克风格和机器人风格。当然,也建议你发挥创造力,实现更多有趣的风格转换。
# 结合ControlNet进行文生图# 这里可以更换为你想要的风格,只需要修改prompt即可
prompt = "a smiling woman, winter backbround, cartoon style"
# prompt = "a smiling woman, summer backbround, van gogh style"
# prompt = "a smiling woman, busy city, cyberpunk style"
# prompt = "a smiling robot"# 设置随机种子
generator = torch.manual_seed(1025) # 设置负prompt,避免生成不合需求的内容
negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, Normal quality, jpeg artifacts, signature, watermark, username, blurry"# 设置ControlNet条件缩放参数
controlnet_conditioning_scale = 0.6 # 生成图像
images = pipe([prompt]*2, # 提示 num_inference_steps=50, negative_prompt=[negative_prompt]*2, image=image, controlnet_conditioning_scale=controlnet_conditioning_scale,generator = generator
).images
ControlNet-使用指令级修图模式
指令修图模式下,只需提供指令式提示,说明执行的转换操作,ControlNet 即可生成目标图像。比如让图像着火,无需添加复杂信息,在指令修图模式中说明“add fire”,整个画面立即燃起火焰。显然,指令修图模式更加灵活高效,无需额外控制条件输入(如轮廓线等),即可生成新图像。这种能力是否可用于图像风格化?当然可以。
我们仍以蒙娜丽莎画像为例,先加载 SD1.5 基础模型和对应的 ControlNet 指令修图模型。
# 加载ControlNet模型
checkpoint = "lllyasviel/control_v11e_sd15_ip2p"
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)# 创建StableDiffusionControlNetPipeline管道
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16) # 启用CPU卸载加速
pipe.enable_model_cpu_offload() # 定义prompt
prompt = "make it spring"
prompt = "make it summer"
prompt = "make it autumn"
prompt = "make it winter"# 设置随机种子
generator = torch.manual_seed(0)# 生成图像
image_style1 = pipe(prompt, num_inference_steps=30, generator=generator, image=original_image).images[0]# 通过pipe和prompt控制生成不同季节风格图片

模型融合的技巧
实际上,除了使用自己训练的模型进行风格化,使用不同SD模型进行融合也是一种常见技巧,可以快速调制出特色鲜明的AI绘画风格。
模型融合本质上是对多个模型进行加权混合,得到一个合并后的新模型。比如希望将Anything V5和ToonYou两个模型进行融合,只需给每个模型的权重分别乘以一个系数,然后相加。在WebUI中,可以选择Checkpoint Merger窗口完成模型融合。例如在Weighted sum模式下,融合后模型权重计算方式如下:
Anything V5模型
ToonYou
*新模型权重 = 模型A (1 - M) + 模型B * M
其中M为加权系数。通过调节系数大小可以控制不同模型在融合模型中的贡献度。
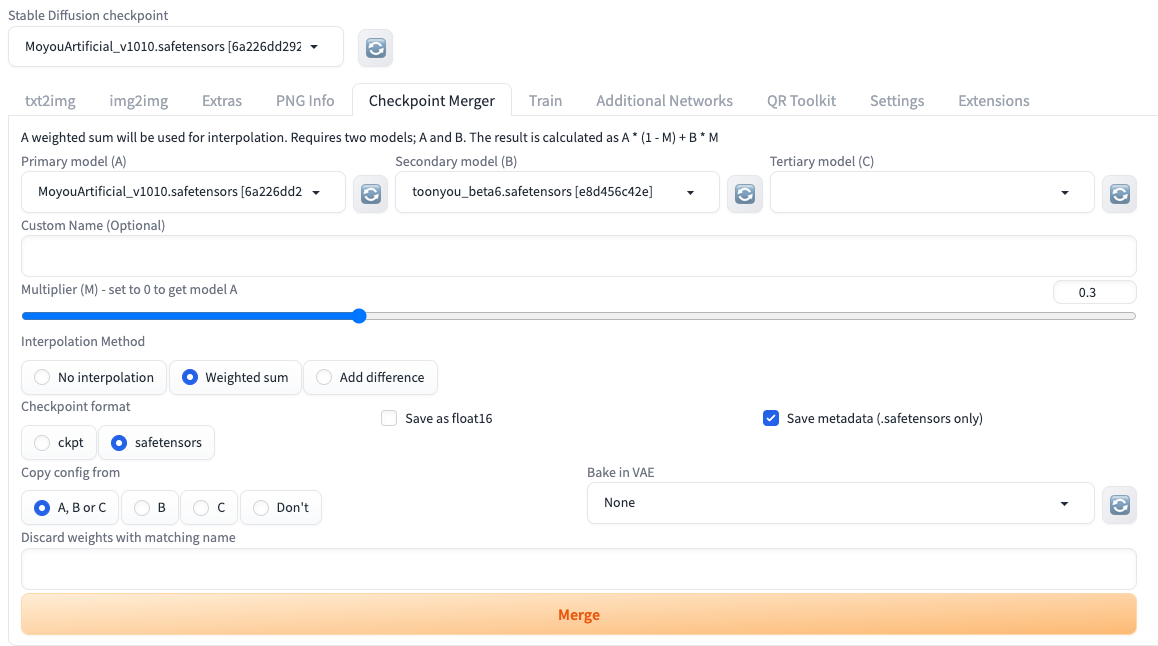
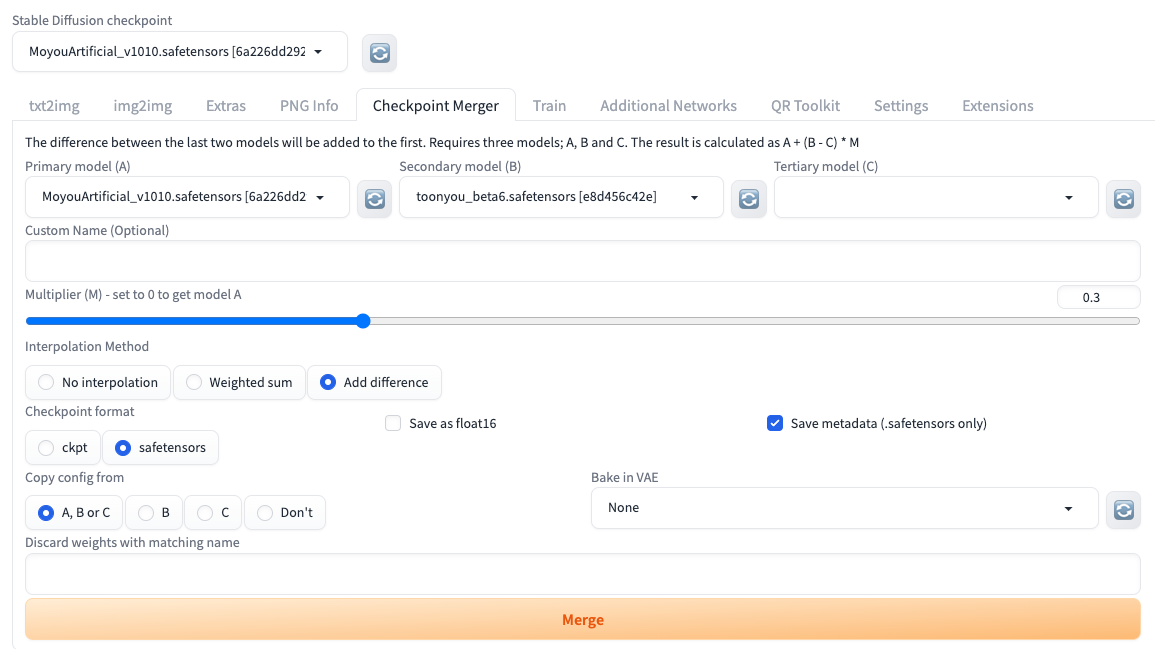
在 Add difference 这个模式下,我们需要提供三个模型,将模型 B 和模型 C 的权重差值以一定的权重加到原始模型 A 上。融合后模型权重的计算方式你可以看后面的公式,公式中的 M 仍是加权系数。
新模型权重 = 模型 A + (模型 B - 模型 C) * M
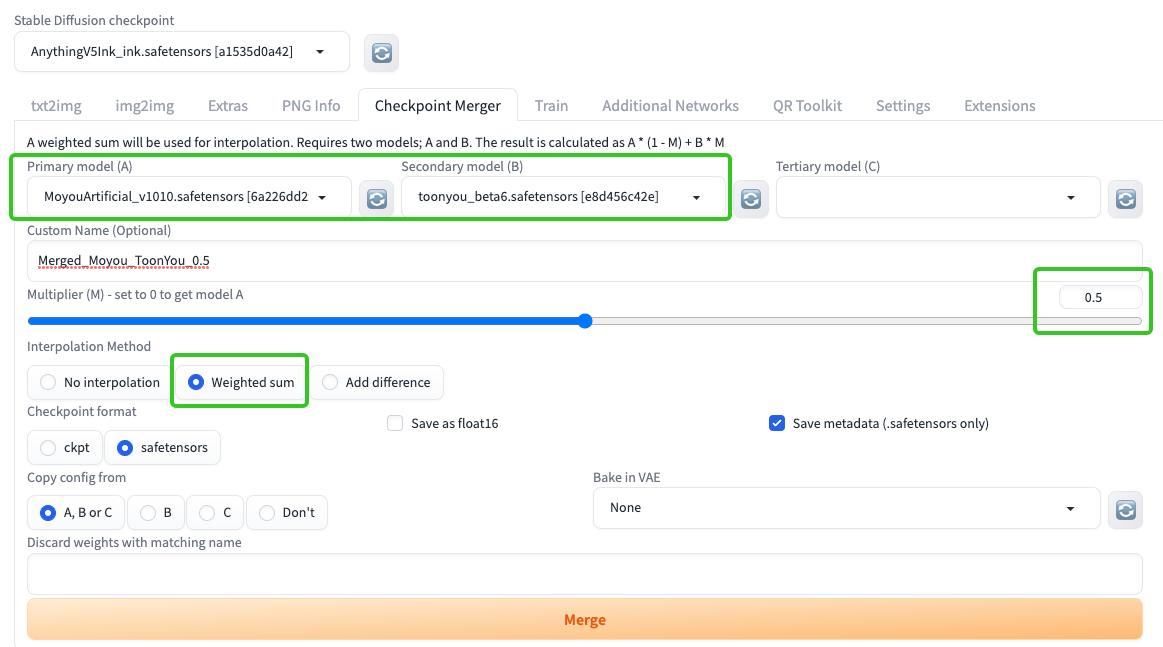
我们可以分别测试一下融合模型的生成效果。对于 Weighted sum 模式,我们将 Anything V5 模型和 ToonYou 模型按照加权系数 0.5 的方式进行融合。你可以点开图片查看我的参数设置。

Prompt:1girl, fashion photography [女生形象]
Prompt:1boy, fashion photography [男生形象]
Negative Prompt:EasyNegative
采样器:Eular a
随机种子:603579160
采样步数:20
分辨率:512x512
CFG Scale: 7
结语
人生如朝露,醒时同放光。众生平等贵,固然艺术家。执笔挥毫处,情怀高下立。非有天分休,谈何尽绚烂。
欢迎留言讨论!
我们分别以图生图、ControlNet 边缘条件和 ControlNet 指令修图为例,完成了图像风格化的项目实战,并探讨了多模型融合调制新模型的原理和 WebUI 操作技巧。
我是李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!
这篇关于AI绘画风格化实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




