本文主要是介绍《向量数据库指南》让「引用」为 RAG 机器人回答增加可信度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在之前的文章中,我们已经介绍了如何用 Milvus 向量数据库以及 LlamaIndex 搭建基础的聊天机器人《Chat Towards Data Science |如何用个人数据知识库构建 RAG 聊天机器人?》《书接上回,如何用 LlamaIndex 搭建聊天机器人?》。
本文将继续使用 LlamaIndex,并在前两篇文章的基础上,修改代码来为我们的结果添加引用。TruEra 在他们的一篇 RAG 评估博客介绍了结果依据(Groundness),有兴趣的朋友可以点击链接查看。
-
准备步骤
首先,安装 llama-index、python-dotenv、pymilvus 和 openai
。
! pip install llama-index python-dotenv openai pymilvus
接着,设置 OpenAI 和 Zilliz Cloud (全托管的 Milvus 向量数据库),用 load_dotenv 函数拉取存储在.env 文件中的环境变量。随后,传入环境变量,使用os获取变量值。我们用 OpenAI 作为 LLM,Zilliz Cloud(https://zilliz.com.cn/cloud) 作为向量数据库。本例中,我们用 Zilliz Cloud 及 Collection 实现数据持久化。
import osfrom dotenv import load_dotenv
import openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
-
设置参数
接下来,定义 RAG 聊天机器人的参数。我们必须设置 3 个参数:Embedding 模型、Milvus向量数据库和 LlamaIndex 数据传入。
首先,设置我们的 Embedding 模型。在本例中,我们用在之前的文章中用到的HuggingFace MiniLM L12 模型来抓取数据并转换为 Embedding 向量,同时可以通过 LlamaIndex 使用 HuggingFaceEmbedding 模块来加载这些数据。
from llama_index.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L12-v2")
其次,设置向量数据库。由于 Zilliz Cloud 可以提供全托管的 Milvus 服务,我们可以使用MilvusVectorStore模块来连接 Zilliz Cloud。在此过程中,需要提供 URI、token 并定义 Collection名称、相似度类型和文本键。
此前,我们已经通过环境变量获取了 Zilliz Cloud URI 和 token,Collection 名称、相似度类型和文本键则沿用之前文章中的设置。
from llama_index.vector_stores import MilvusVectorStore
vdb = MilvusVectorStore(uri = zilliz_uri,token = zilliz_token,collection_name = "tds_articles",similarity_metric = "L2",text_key="paragraph"
)
最后,整合 LlamaIndex 数据抽象。我们需要的两个原生组件是服务上下文(service context)以及向量存储索引(vector store index),服务上下文用于传入一些预定义的服务,向量存储索引用于从向量数据库创建一个 LlamaIndex “索引”。在本例中,我们用服务上下文来传入 Embedding 模型,用现有的 Milvus 向量数据库和创建的服务上下文来创建向量索引。
from llama_index import VectorStoreIndex, ServiceContext
service_context = ServiceContext.from_defaults(embed_model=embed_model)
vector_index = VectorStoreIndex.from_vector_store(vector_store=vdb, service_context=service_context)
-
为聊天机器人回答添加引用
引用和注释(Citation and attribution)能够进一步优化我们的 RAG 应用,可以通过引用和注释,了解回答的数据来源,并依此评估获得的回答有多准确。
LlamaIndex 通过其CitationQueryEngine模块提供了一种实现引用的简便方法,这个模块非常容易上手。用from_args并传入向量索引,便可创建一个引用查询引擎。由于之前在向量索引中定义了文本字段,所以不需要再额外添加任何东西。
from llama_index.query_engine import CitationQueryEngine
query_engine = CitationQueryEngine.from_args(vector_index
)
搭建了查询引擎后,便可以开始发送查询问题了。例如,我们向聊天机器人提问:“What is a large language model?(什么是大语言模型?)”。预期中,我们应该可以从 Towards Data Science 数据集中获取这个问题的答案。
res = query_engine.query("What is a large language model?")
from pprint import pprint
pprint(res)
下图为响应示例,响应中包含了回答和来源文本,我们可以根据来源判断得到的回答的准确性。
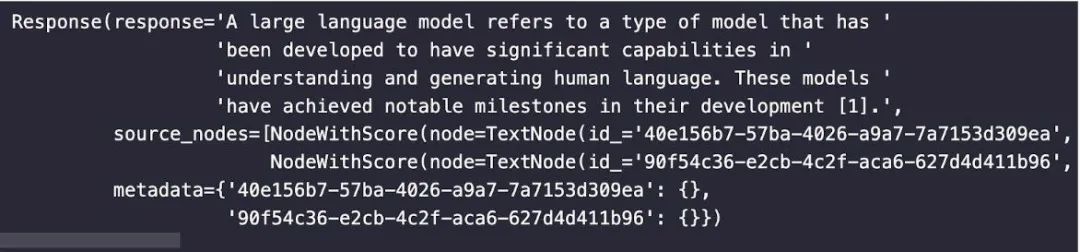
-
总结
本文采用了引用和注释的方法来为机器人的回答增加可信度。可以说,引用和注释解决了 RAG 的两个常见问题,通过引用和注释,我们能够知道数据来源。同时,我们还能根据数据来源评估获得的回答有多准确。此外,我们在文章中还使用了 LlamaIndex 和 Zilliz Cloud,LlamaIndex 能帮我们轻松创建获取来源的引擎,而 Zilliz Cloud 帮我们轻松实现数据持久化。
这篇关于《向量数据库指南》让「引用」为 RAG 机器人回答增加可信度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





