本文主要是介绍【HuggingFace Transformer库学习笔记】基础组件学习:Trainer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基础组件学习——Trainer

导入包
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
加载数据集
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset = dataset.filter(lambda x: x["review"] is not None)
datasetDataset({features: ['label', 'review'],num_rows: 7765
})
划分数据集
datasets = dataset.train_test_split(test_size=0.1)
datasetsDatasetDict({train: Dataset({features: ['label', 'review'],num_rows: 6988})test: Dataset({features: ['label', 'review'],num_rows: 777})
})
数据集预处理
import torchtokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")def process_function(examples):tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)tokenized_examples["labels"] = examples["label"]return tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasetsDatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 6988})test: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 777})
})
创建模型
model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3")
model.configBertConfig {"_name_or_path": "hfl/rbt3","architectures": ["BertForMaskedLM"],"attention_probs_dropout_prob": 0.1,"classifier_dropout": null,"directionality": "bidi","hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"layer_norm_eps": 1e-12,"max_position_embeddings": 512,"model_type": "bert","num_attention_heads": 12,"num_hidden_layers": 3,"output_past": true,"pad_token_id": 0,"pooler_fc_size": 768,"pooler_num_attention_heads": 12,"pooler_num_fc_layers": 3,"pooler_size_per_head": 128,"pooler_type": "first_token_transform","position_embedding_type": "absolute","transformers_version": "4.35.2","type_vocab_size": 2,"use_cache": true,"vocab_size": 21128
}
创建评估函数
import evaluateacc_metric = evaluate.load("accuracy")
f1_metirc = evaluate.load("f1")
def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = predictions.argmax(axis=-1)acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metirc.compute(predictions=predictions, references=labels)acc.update(f1)return acc
创建TrainingArguments
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹per_device_train_batch_size=64, # 训练时的batch_sizeper_device_eval_batch_size=128, # 验证时的batch_sizelogging_steps=10, # log 打印的频率evaluation_strategy="epoch", # 评估策略save_strategy="epoch", # 保存策略save_total_limit=3, # 最大保存数learning_rate=2e-5, # 学习率weight_decay=0.01, # weight_decaymetric_for_best_model="f1", # 设定评估指标load_best_model_at_end=True) # 训练完成后加载最优模型
train_argsTrainingArguments(
_n_gpu=8,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=2e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./checkpoints/runs/Jan13_18-37-43_wg-100-52,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=f1,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
output_dir=./checkpoints,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=128,
per_device_train_batch_size=64,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=None,
run_name=./checkpoints,
save_on_each_node=False,
save_safetensors=True,
save_steps=500,
...
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.01,
)
创建Trainer
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model, args=train_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=eval_metric)
模型训练
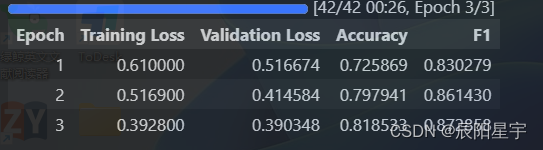
trainer.train()
模型评估
trainer.evaluate(tokenized_datasets["test"]){'eval_loss': 0.3903481960296631,'eval_accuracy': 0.8185328185328186,'eval_f1': 0.872858431018936,'eval_runtime': 0.4418,'eval_samples_per_second': 1758.732,'eval_steps_per_second': 2.263,'epoch': 3.0}
模型预测
trainer.predict(tokenized_datasets["test"])Downloading data files: 100%
1/1 [00:00<00:00, 43.99it/s]
Extracting data files: 100%
1/1 [00:00<00:00, 11.15it/s]
Generating train split:
7766/0 [00:00<00:00, 32712.12 examples/s]
Filter: 100%
7766/7766 [00:00<00:00, 66325.06 examples/s]
Dataset({features: ['label', 'review'],num_rows: 7765
})
DatasetDict({train: Dataset({features: ['label', 'review'],num_rows: 6988})test: Dataset({features: ['label', 'review'],num_rows: 777})
})
Map: 100%
6988/6988 [00:01<00:00, 6948.87 examples/s]
Map: 100%
777/777 [00:00<00:00, 7551.30 examples/s]
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 6988})test: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 777})
})
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at project/transformers-code-master/model/rbt3 and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
BertConfig {"_name_or_path": "hfl/rbt3","architectures": ["BertForMaskedLM"],"attention_probs_dropout_prob": 0.1,"classifier_dropout": null,"directionality": "bidi","hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"layer_norm_eps": 1e-12,"max_position_embeddings": 512,"model_type": "bert","num_attention_heads": 12,"num_hidden_layers": 3,"output_past": true,"pad_token_id": 0,"pooler_fc_size": 768,"pooler_num_attention_heads": 12,"pooler_num_fc_layers": 3,"pooler_size_per_head": 128,"pooler_type": "first_token_transform","position_embedding_type": "absolute","transformers_version": "4.35.2","type_vocab_size": 2,"use_cache": true,"vocab_size": 21128
}
TrainingArguments(
_n_gpu=8,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=2e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./checkpoints/runs/Jan13_18-37-43_wg-100-52,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=f1,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
output_dir=./checkpoints,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=128,
per_device_train_batch_size=64,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=None,
run_name=./checkpoints,
save_on_each_node=False,
save_safetensors=True,
save_steps=500,
...
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.01,
)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
Detected kernel version 3.10.0, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
hg/lib/python3.9/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.warnings.warn('Was asked to gather along dimension 0, but all '[42/42 00:26, Epoch 3/3]
Epoch Training Loss Validation Loss Accuracy F1
1 0.610000 0.516674 0.725869 0.830279
2 0.516900 0.414584 0.797941 0.861430
3 0.392800 0.390348 0.818533 0.872858
hg/lib/python3.9/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.warnings.warn('Was asked to gather along dimension 0, but all '
hg/lib/python3.9/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.warnings.warn('Was asked to gather along dimension 0, but all '
TrainOutput(global_step=42, training_loss=0.4852517715522221, metrics={'train_runtime': 47.1938, 'train_samples_per_second': 444.21, 'train_steps_per_second': 0.89, 'total_flos': 351909933963264.0, 'train_loss': 0.4852517715522221, 'epoch': 3.0})
hg/lib/python3.9/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.warnings.warn('Was asked to gather along dimension 0, but all '
{'eval_loss': 0.3903481960296631,'eval_accuracy': 0.8185328185328186,'eval_f1': 0.872858431018936,'eval_runtime': 0.4418,'eval_samples_per_second': 1758.732,'eval_steps_per_second': 2.263,'epoch': 3.0}
hg/lib/python3.9/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.warnings.warn('Was asked to gather along dimension 0, but all '
PredictionOutput(predictions=array([[ 0.6721468 , -0.03753865],[-1.1493708 , 1.5108933 ],[ 0.9299763 , -0.3243772 ],...,[-1.2351408 , 1.3719875 ],[ 0.7072362 , 0.33271554],[-1.2782698 , 1.4008656 ]], dtype=float32), label_ids=array([0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0,0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1,0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1,1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1,0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1,0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1,0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1,1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0,1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0,1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1,1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0,1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0,0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1,1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0,0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1,1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1,1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1,0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1,0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0,1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1,1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1,1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1,1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1,1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0,1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0,1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1,1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1,1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1,0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1,1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,0, 1, 0, 1, 1, 1, 1]), metrics={'test_loss': 0.3903481960296631, 'test_accuracy': 0.8185328185328186, 'test_f1': 0.872858431018936, 'test_runtime': 0.3025, 'test_samples_per_second': 2568.929, 'test_steps_per_second': 3.306})
模型推理预测
sen = "我觉得这家酒店不怎么样"
id2_label = {0: "差评!", 1: "好评!"}
model.eval()
with torch.inference_mode():inputs = tokenizer(sen, return_tensors="pt")inputs = {k: v.cuda() for k, v in inputs.items()}logits = model(**inputs).logitspred = torch.argmax(logits, dim=-1)print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
使用pipeline整合
from transformers import pipelinemodel.config.id2label = id2_label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
pipe(sen)[{'label': '好评!', 'score': 0.956095278263092}]
查看训练情况
启动tensorboard查看模型运行情况
cd checkpoints/
ls heckpoint-14 checkpoint-28 checkpoint-42 runs
# 启动
tensorboard --logdir runsTensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.15.1 at http://localhost:6006/ (Press CTRL+C to quit)
进入网页可查看
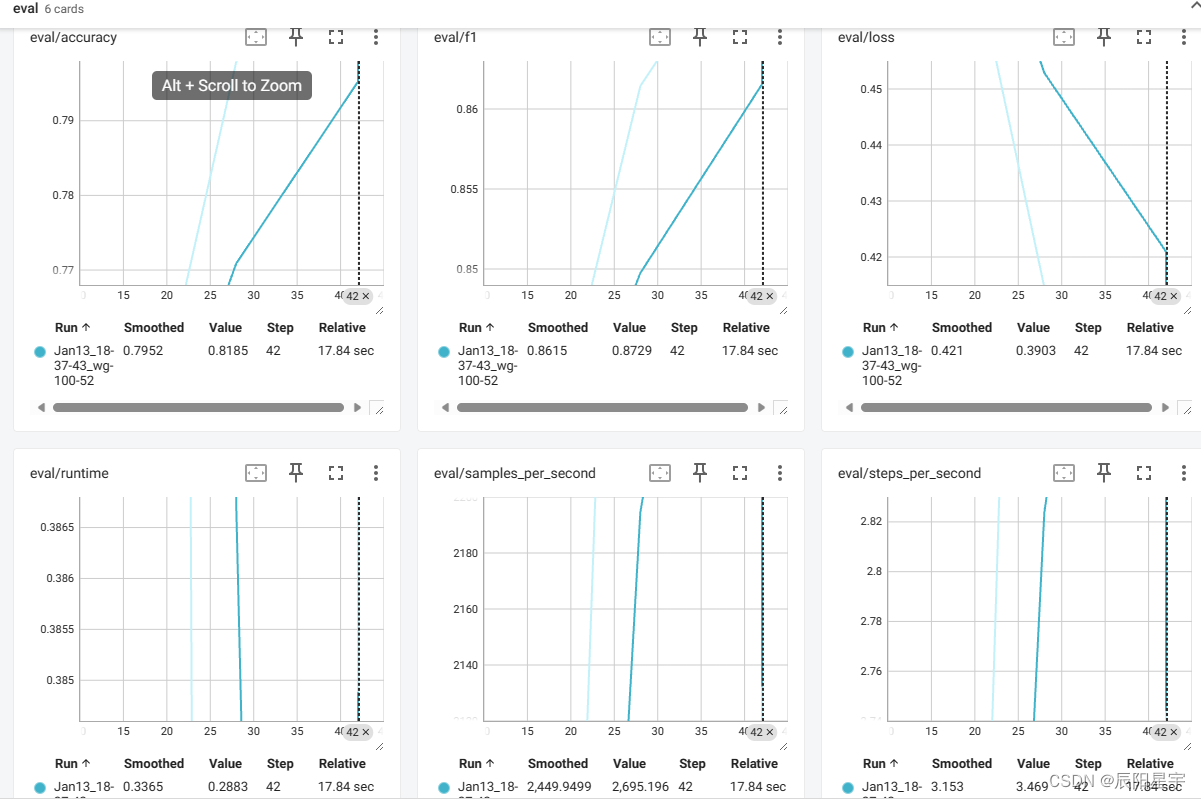
如果使用的是vscode,可直接在vscode中启动,输入Ctrl + shift + p,然后再输入tensorboard(会提示安装),然后再点击在当前工作目录里启动
这篇关于【HuggingFace Transformer库学习笔记】基础组件学习:Trainer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





