本文主要是介绍PaddleSeg的训练与测试推理全流程(超级详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LeNet模型量化
- 参考文档
- 一.下载
- 项目地址:https://gitee.com/paddlepaddle/PaddleSeg/tree/release%2F2.5/
- 特别注意下载版本:
- 二.paddlepaddle-gpu安装
- 1.环境安装参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/install_cn.md
- 2.地址:https://www.paddlepaddle.org.cn/
- 三.测试案例运行
- 1.文档地址:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/quick_start_cn.md
- 四.使用自己数据训练推理
- 参考文档地址
- 1.准备数据
- 2.根据自己实际情况修改配置文件
- 参数type如何选择
- 2.训练
- 1.训练时报错
- 3.导出模型
- 参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/model_export_cn.md
- 4.模型推理预测
- 参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/predict/predict_cn.md
- 5.将模型转为onnx模型
- 参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/model_export_onnx_cn.md
- 五.优化
- Q1:如果一张图特别大 ,而瑕疵占比特别小怎么办,训练的交叉验证结果瑕疵类别的识别IOU等数据都为0怎么办
参考文档
- PaddleSeg 自建训练集训练+评估+模型部署:http://t.csdnimg.cn/Ik5Fr
- PaddleSeg官网:https://gitee.com/paddlepaddle/PaddleSeg
一.下载
项目地址:https://gitee.com/paddlepaddle/PaddleSeg/tree/release%2F2.5/
特别注意下载版本:
我之前找到了一个paddleSeg的链接就下载了,结果调试的时候怎么都不对,会有奇奇怪怪的错误,并且非常棘手,解决不了

结果我后来发现

我原来是0.4版本,太旧了,所以出现各种由于不适配导致的问题,现在已经出到2.8版本了,怕版本太新导致的不适配,我保守的选择了2.5版本
二.paddlepaddle-gpu安装
1.环境安装参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/install_cn.md
2.地址:https://www.paddlepaddle.org.cn/
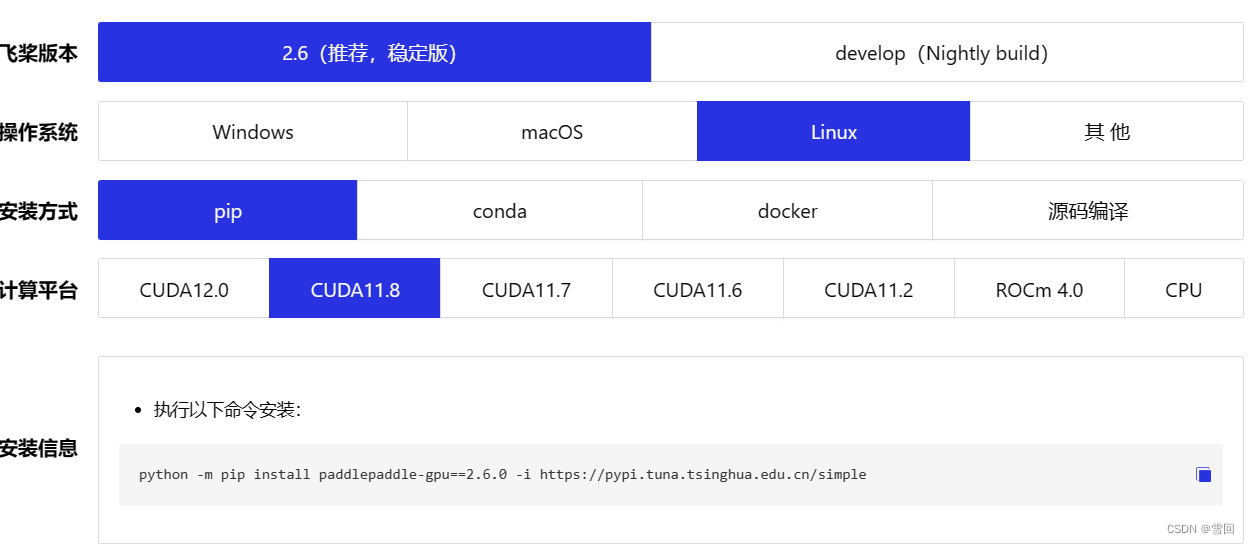
按照自己的cuda版本下载
三.测试案例运行
1.文档地址:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/quick_start_cn.md
四.使用自己数据训练推理
参考文档地址
https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/whole_process_cn.md
1.准备数据
我是用自己的软件标注的,标注出来的图有两类,黑色为背景,白色为瑕疵。后来发现训练这个,标注图像的标签从 0,1 依次取值,不可间隔。若有需要忽略的像素,则按 255 进行标注。
- 报错
The value of label expected >= 0 and < 2, or == 255, but got 70. Please check label value.
因为这个paddleSeg的标注图像是按照像素来的,有几类像素就有几个类别,我的原标注图是灰度图,与config文件里写的两个类别不符,所以会报这个错
于是我先将所有标注图片二值化,参考这个博文,http://t.csdnimg.cn/y4Ian,后来才发现需要忽略的像素才标注为255像素,也就是白色,所以我将原二值化的代码稍微改动了下,使得背景像素值为0,背景像素值为1,标注出来的图片近乎全黑,肉眼是看不到区别的
- cv2.threshold()函数解读:http://t.csdnimg.cn/hm3Ud

import cv2
import osdef read_path(file_pathname):#遍历该目录下的所有图片文件for filename in os.listdir(file_pathname):print(filename)image = cv2.imread(file_pathname+'/'+filename)####change to gray#(下面第一行是将RGB转成单通道灰度图,第二步是将单通道灰度图转成3通道灰度图)image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) # 二值化函数 cvtcolor不能有中文路径!!!# cv2.threshold(image, 140, 255, 0, image) # 二值化函数# retval, dst = cv2.threshold(image, 0, 1, cv2.THRESH_OTSU)#像素值小于50的全都设置为0,像素值大于50的设置为1 retval, dst = cv2.threshold(image, 50, 1, cv2.THRESH_BINARY)# # 腐蚀和膨胀是对白色部分而言的,膨胀,白区域变大,最后的参数为迭代次数# dst = cv2.dilate(dst, None, iterations=1)# # 腐蚀,白区域变小# dst = cv2.erode(dst, None, iterations=4)# cv2.namedWindow("Image") # 图片显示框的名字 这行没啥用# cv2.imshow("Image", dst) # 图片显示# cv2.waitKey(0)cv2.imwrite('/home/wjp/PaddleSeg-release-2.5/data/mianhua_128/savelabel/'+filename, dst) # 保存当前灰度值处理过后的文件# 图像的二值化,就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的只有黑和白的视觉效果。# 一幅图像包括目标物体、背景还有噪声,要想从多值的数字图像中直接提取出目标物体,常用的方法就是设定一个阈值T,用T将图像的数据分成两部分:大于T的像素群和小于T的像素群。这是研究灰度变换的最特殊的方法,称为图像的二值化(Binarization)。# Python-OpenCV中提供了阈值(threshold)函数:# cv2.threshold()# 函数:# 1. src 指原图像,原图像应该是灰度图。# 2. x 指用来对像素值进行分类的阈值。# 3. y 指当像素值高于(有时是小于)阈值时应该被赋予的新的像素值# 4. Methods 指不同的阈值方法,
read_path("/home/wjp/PaddleSeg-release-2.5/data/mianhua_128/savelabel0")2.根据自己实际情况修改配置文件
最一般需要改的几个参数是batch_size,iters,type,dataset_root,train_path,num_classes,val_path,crop_size
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大。如果使用多卡训练,总得batch size等于该batch size乘以卡数。
iters: 1000 #模型训练迭代的轮数train_dataset: #训练数据设置type: Dataset #OpticDiscSeg等 #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。dataset_root: data/optic_disc_seg #数据集路径train_path: data/optic_disc_seg/train_list.txt #数据集中用于训练的标识文件num_classes: 2 #指定类别个数(背景也算为一类)mode: train #表示用于训练transforms: #模型训练的数据预处理方式。- type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍min_scale_factor: 0.5max_scale_factor: 2.0scale_step_size: 0.25- type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小crop_size: [512, 512]- type: RandomHorizontalFlip #对原始图像和标注图像随机进行水平反转- type: RandomDistort #对原始图像进行亮度、对比度、饱和度随机变动,标注图像不变brightness_range: 0.5contrast_range: 0.5saturation_range: 0.5- type: Normalize #对原始图像进行归一化,标注图像保持不变val_dataset: #验证数据设置type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。dataset_root: data/optic_disc_seg #数据集路径val_path: data/optic_disc_seg/val_list.txt #数据集中用于验证的标识文件num_classes: 2 #指定类别个数(背景也算为一类)mode: val #表示用于验证transforms: #模型验证的数据预处理的方式- type: Normalize #对原始图像进行归一化,标注图像保持不变optimizer: #设定优化器的类型type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器momentum: 0.9 #设置SGD的动量weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合lr_scheduler: # 学习率的相关设置type: PolynomialDecay # 一种学习率类型。共支持12种策略learning_rate: 0.01 # 初始学习率power: 0.9end_lr: 0loss: #设定损失函数的类型types:- type: CrossEntropyLoss #CE损失coef: [1, 1, 1] # PP-LiteSeg有一个主loss和两个辅助loss,coef表示权重,所以 total_loss = coef_1 * loss_1 + .... + coef_n * loss_nmodel: #模型说明type: PPLiteSeg #设定模型类别backbone: # 设定模型的backbone,包括名字和预训练权重type: STDC2pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet2.tar.gz
参数type如何选择
这个目录下都是数据集type,可在里面找与你的类别相同的数据集直接使用
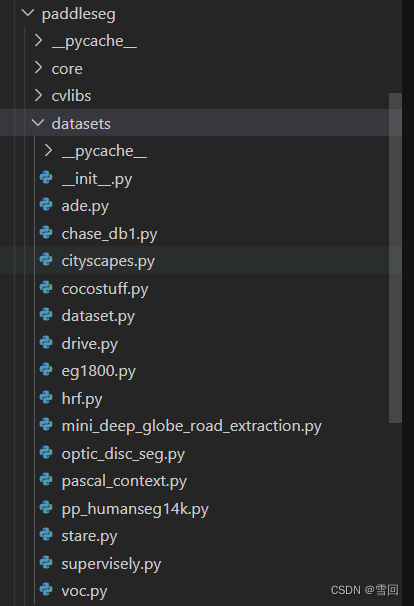
比如我的类别是2,我就可以直接使用这个数据集,写type:OpticDiscSeg
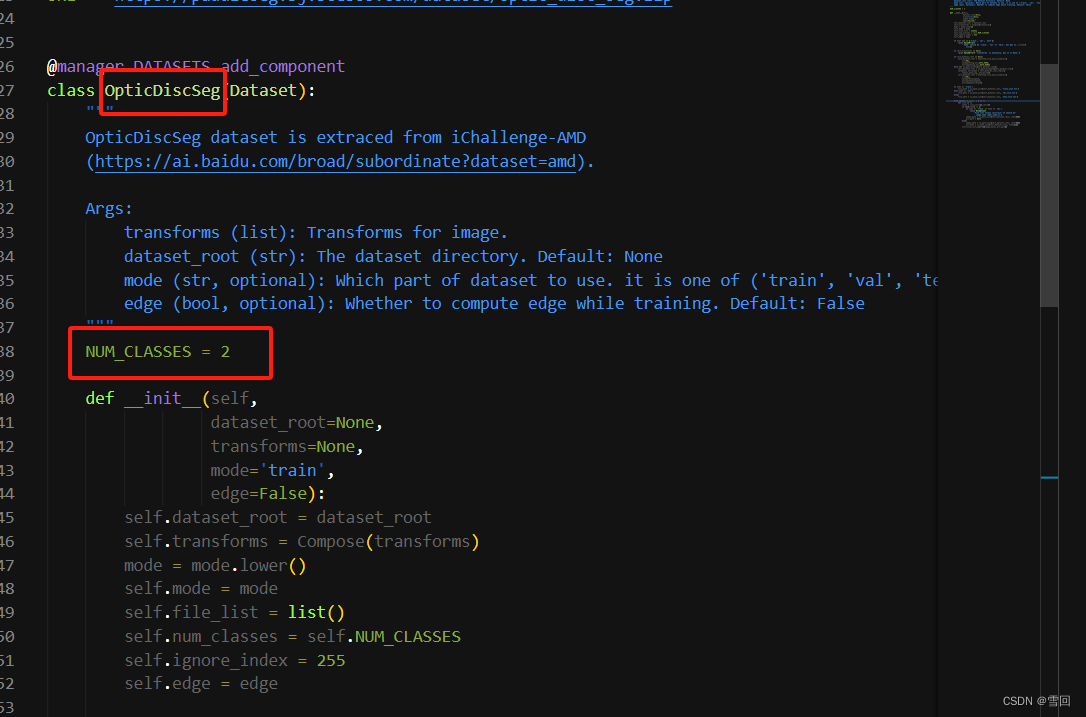
- 每一个yml文件需要的关键字不一样,如果你写了不需要的关键字,就会报KeyError: ‘xxx’
2.训练
export CUDA_VISIBLE_DEVICES=0 # Linux上设置1张可用的卡
# set CUDA_VISIBLE_DEVICES=0 # Windows上设置1张可用的卡python tools/train.py \--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \--save_interval 500 \--do_eval \--use_vdl \--save_dir output
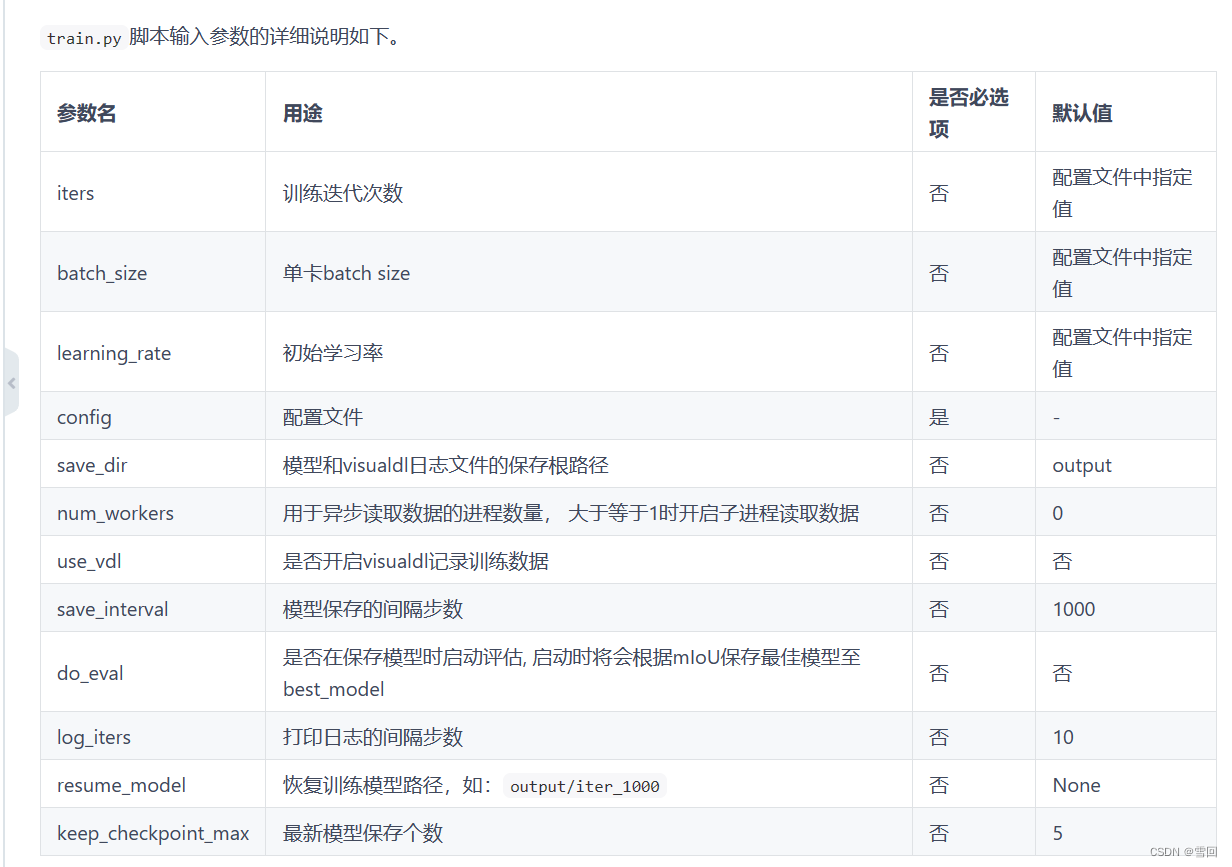
1.训练时报错
valueError: (InvalidArgument) The axis is expected to be in range of [0, 0), but got 0
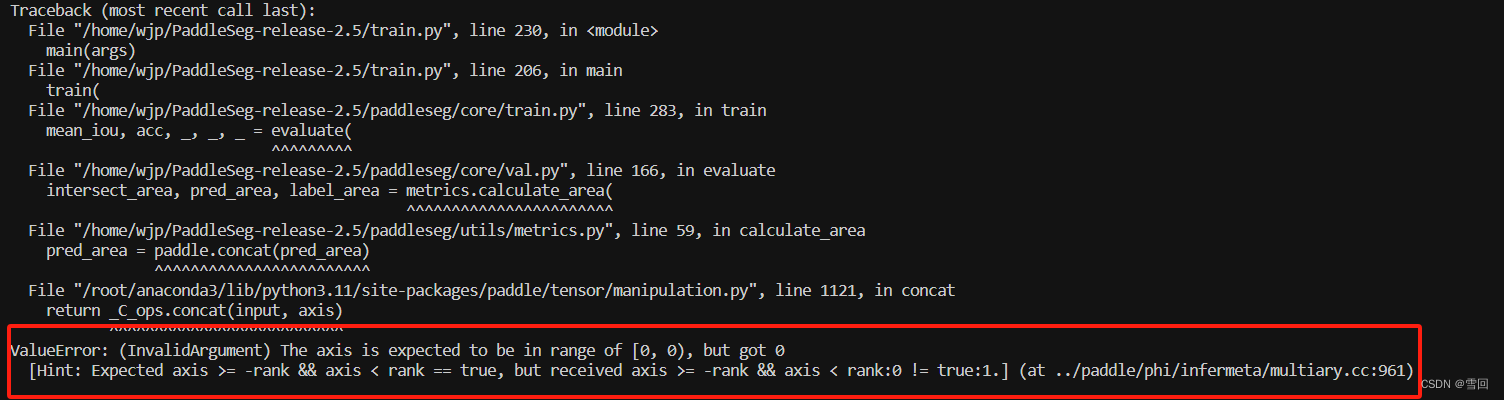
- 解决办法:https://github.com/PaddlePaddle/PaddleSeg/issues/3353
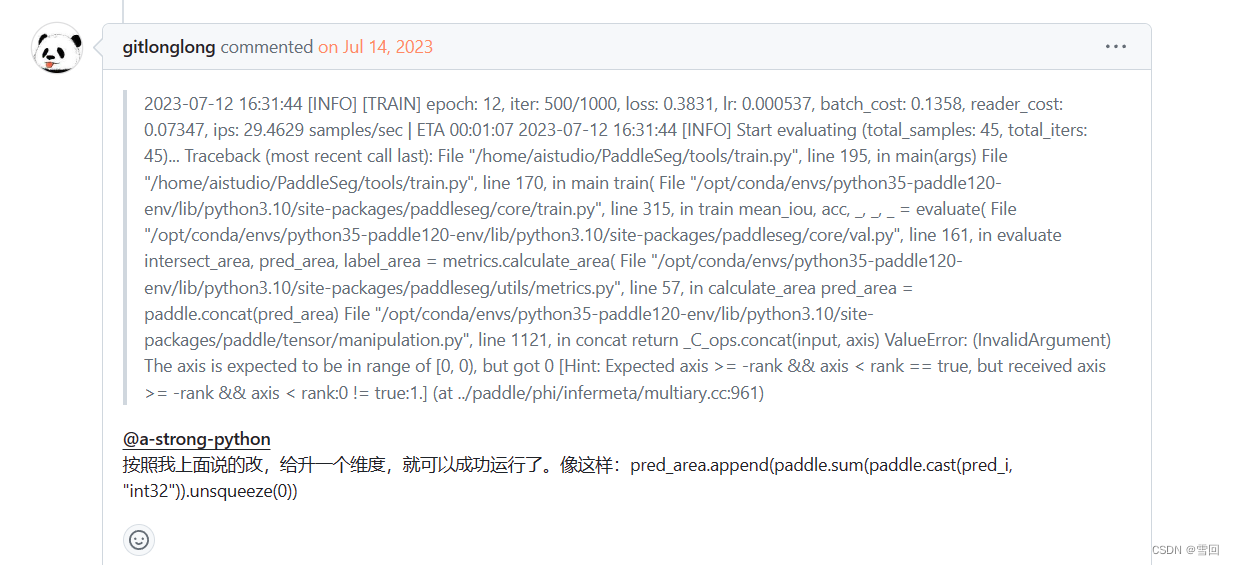
- 源代码

改之后
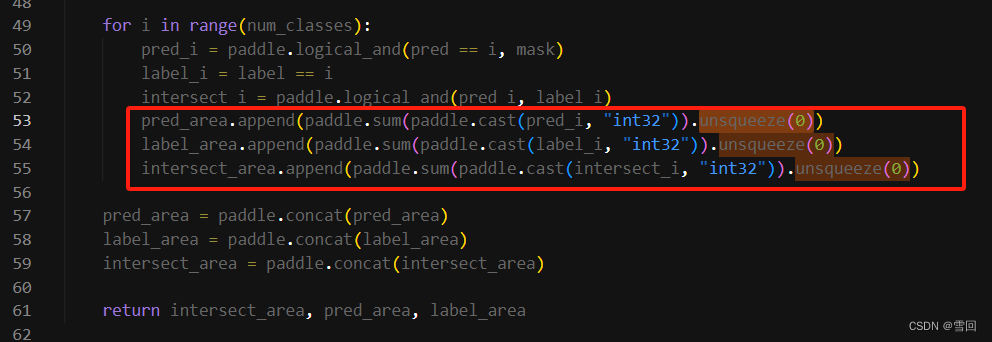
就可以继续正常训练了
3.导出模型
参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/model_export_cn.md
python tools/export.py \--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \--model_path output/best_model/model.pdparams \--save_dir output/infer_model
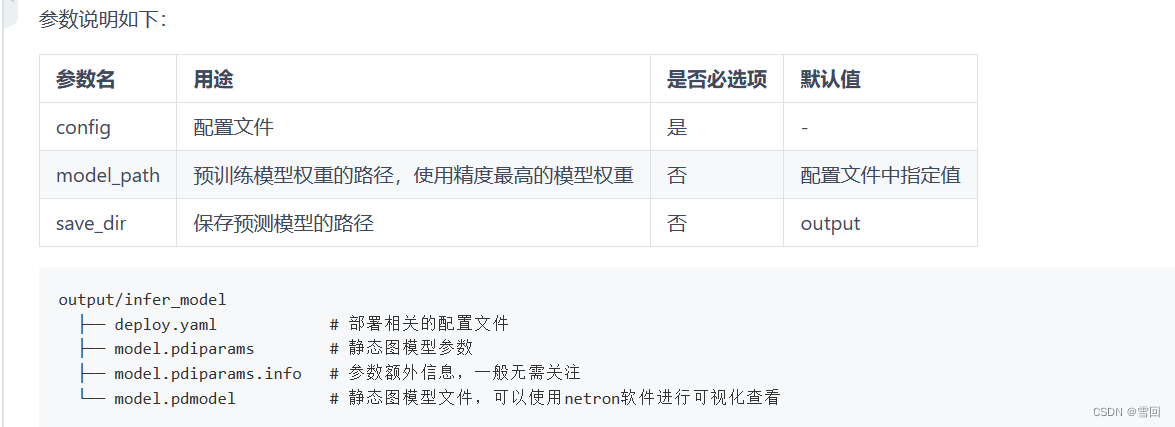

4.模型推理预测
参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/predict/predict_cn.md
python deploy/python/infer.py \--config output/infer_model/deploy.yaml \--image_path data/optic_disc_seg/JPEGImages/H0002.jpg \--save_dir output/result
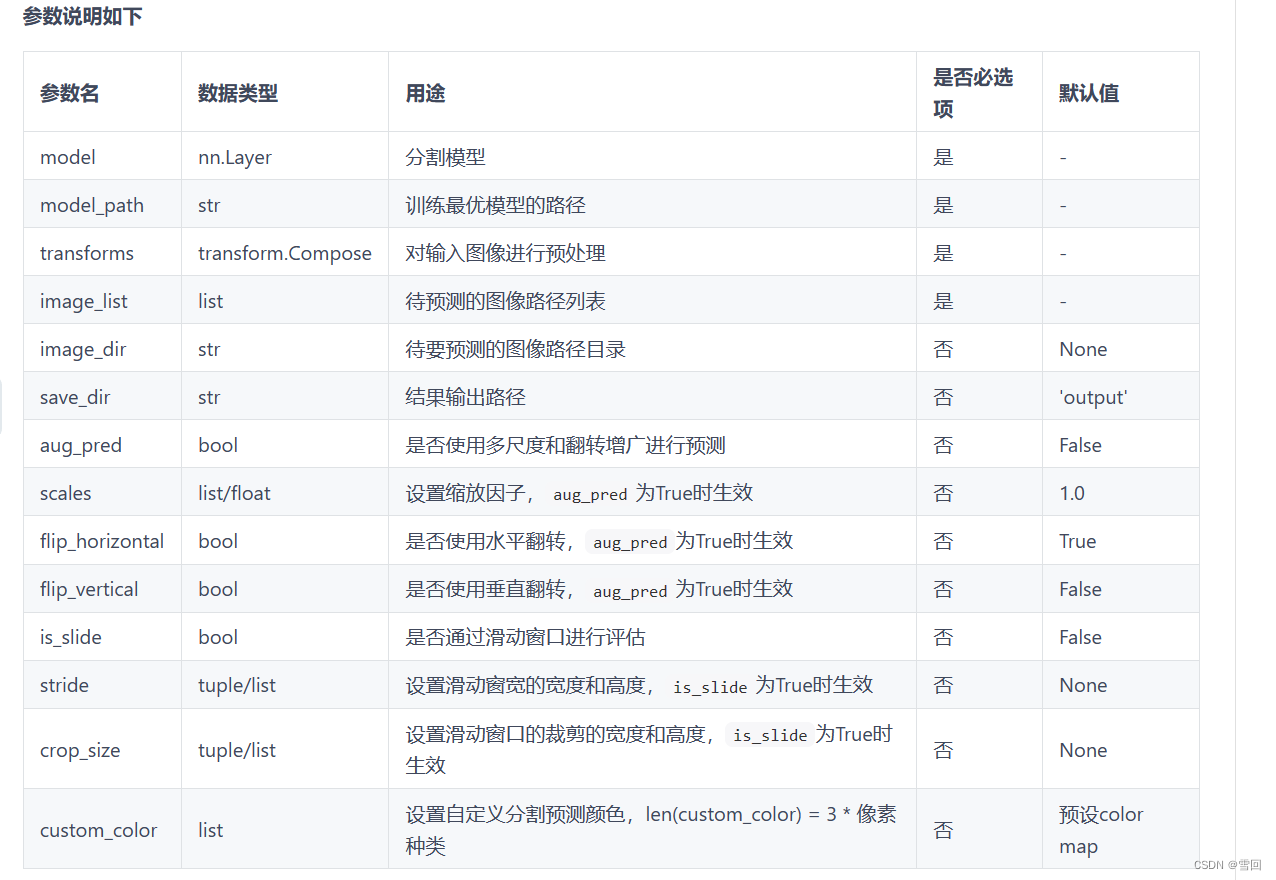
5.将模型转为onnx模型
参考文档:https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.8/docs/model_export_onnx_cn.md
pip install paddle2onnx
paddle2onnx --model_dir output \--model_filename model.pdmodel \--params_filename model.pdiparams \--opset_version 11 \--save_file output.onnx
- 报错
paddle2onnx --model_dir . --model_filename model.pdmodel --params_filename model.pdiparams --save_file model.onnx --enable_dev_version True --opset_version 15
[ERROR][Paddle2ONNX][pool2d: pool2d_1.tmp_0] Adaptive only support static input shape.
[Paddle2ONNX] Due to the operator: pool2d, this model cannot be exported to ONNX.
[ERROR][Paddle2ONNX][pool2d: pool2d_2.tmp_0] Adaptive only support static input shape.
[Paddle2ONNX] Due to the operator: pool2d, this model cannot be exported to ONNX.
解决办法:https://github.com/PaddlePaddle/Paddle2ONNX/issues/813
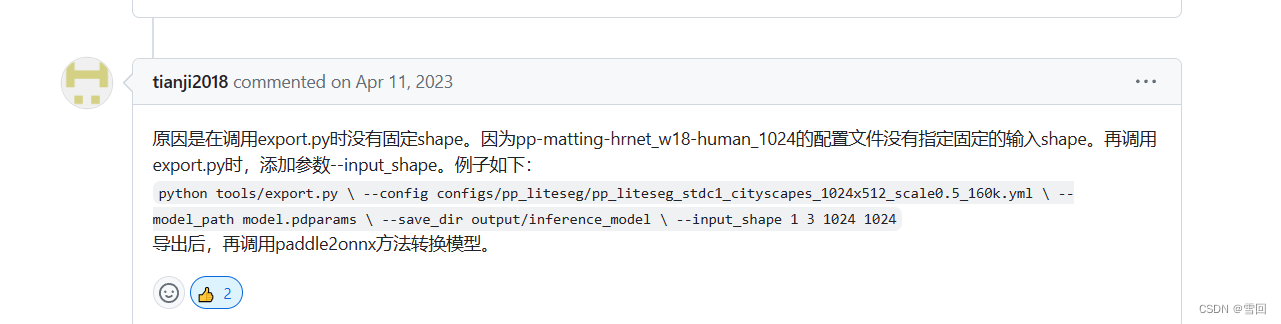
–input_shape 1 3 1024 1024
设置模型的输入shape (NCH*W)
NCHW中,“N”batch批量大小,“C”channels特征图通道数,“H”特征图的高,和“W”特征图的宽。其中N表示这批图像有几张,H表示图像在竖直方向有多少像素,仿团W表示水平方向像素数,C表示通道数(例如黑白图像的通道数C=1,而RGB彩色图像的通道数C=3)
五.优化
Q1:如果一张图特别大 ,而瑕疵占比特别小怎么办,训练的交叉验证结果瑕疵类别的识别IOU等数据都为0怎么办
A1:可以将图片裁剪小,将其中的有瑕疵小图全部挑出来,与无瑕疵小图控制挑出来控制一个比例,再训练,训练后拿这个小图的模型来识别原图,就可以识别出来那些小瑕疵
这篇关于PaddleSeg的训练与测试推理全流程(超级详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





