本文主要是介绍使用飞桨实现的第一个AI项目——波士顿的房价预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
part1.首先引入相应的函数库:
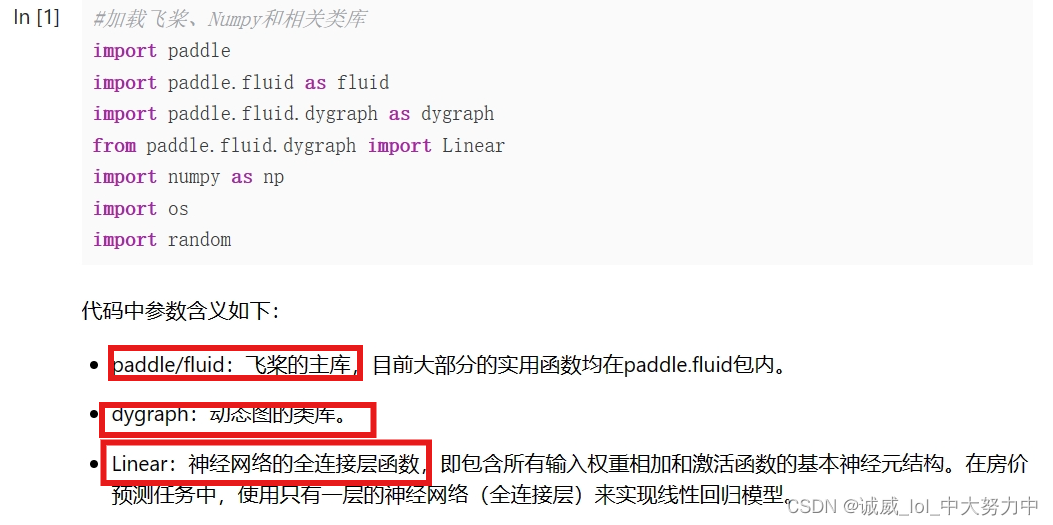
值得说明的地方:
(1)首先,numpy是一个python库,主要用于提供线性代数中的矩阵或者多维数组的运算函数,利用import numpy as np引入numpy,并将np作为它的别名
part2.(一步步慢慢来,从0到1,只要突破了,就会有1到100的发生,所以,慢慢来)下面我们一点点分析“数据处理”部分的代码:
(1)
![]()
这里,就是python中用得最多的函数模块定义,反正下面就是定义了一个load_data()函数
(2)
![]()
![]()
首先,定义一个路径变量(可能是string类型,反正python中变量没有类型),这个路径从这个平台页面的左上角可以查看到./work/house.data里面就是我们需要用到的空气中各个指标的数据

关于这个numpy.fromfile函数的用法和参数说明:
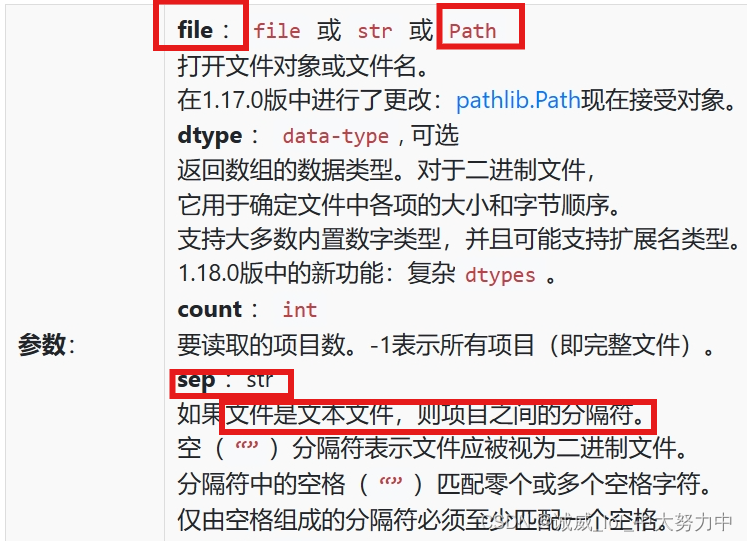
我觉得,这里sep用' '一个空格作为参数,就是用作分隔符的作用
(3)
首先,创建一个names名称字符串数组feature_names,这个数组一共有14个值,前13个值是空气中的各个指标成分,最后一个是房屋价格的中位数
然后,调用len(数组)这个函数取出这个数组的长度14给到变量feature_num
(4)




差点就以为“//”是注释的意思了,
这样的话就好理解了,就是总共有data.shape[0]个数据,除以feature_num得到行,feature_num作为列数,
所以,这一条语句之后,data就变成了一个[N,14]的二维数组了
(5)
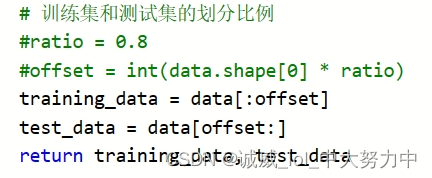
这一部分很容易理解:就是比如说data这个二维数组一共有N行,我们取出前0.8N行构建一个新的二维数组training_data最为训练集数据
(6)
首先,需要了解numpy.max函数中axis参数的含义,axis=0代表取每一列中的最大值,这里的含义就是,总共14个指标,每个指标代表1列,所以就按列分别取出14个列的最大值作为一个大小为14的一维数组,然后给到那个一维数组变量maximums,
同理,minimums也得到一个这样的一维数组,
avgs也是同样,只不过是每一列求和除以行数的平均值
(7)
关于python中的global变量的说明:
(8)
关于“归一化处理”我的理解就是,相对于“某个值”的占比,反正就是为了消除单位的影响

 上面这个代码:就是将data这个数组,for循环是依次按列从列1到列14进行处理,
上面这个代码:就是将data这个数组,for循环是依次按列从列1到列14进行处理,
每个循环就是将1-N所有的行的第i列数据进行归一化处理
(9)
这样看的话,整个def load_data()函数就非常清楚了,
最后就是将“规格化(规格化做的工作就是[N,14]这样)”和“归一化”处理后的二维数组data[N,14]再次分割为前80%作为training_data这个二维数组,后20%最为test_data这个二维数组
(之前有一个代码我觉得是多余的 就是这个,因为最后由定义了一次)
就是这个,因为最后由定义了一次)
part3:模型设计部分
(1)![]()


用法示例:
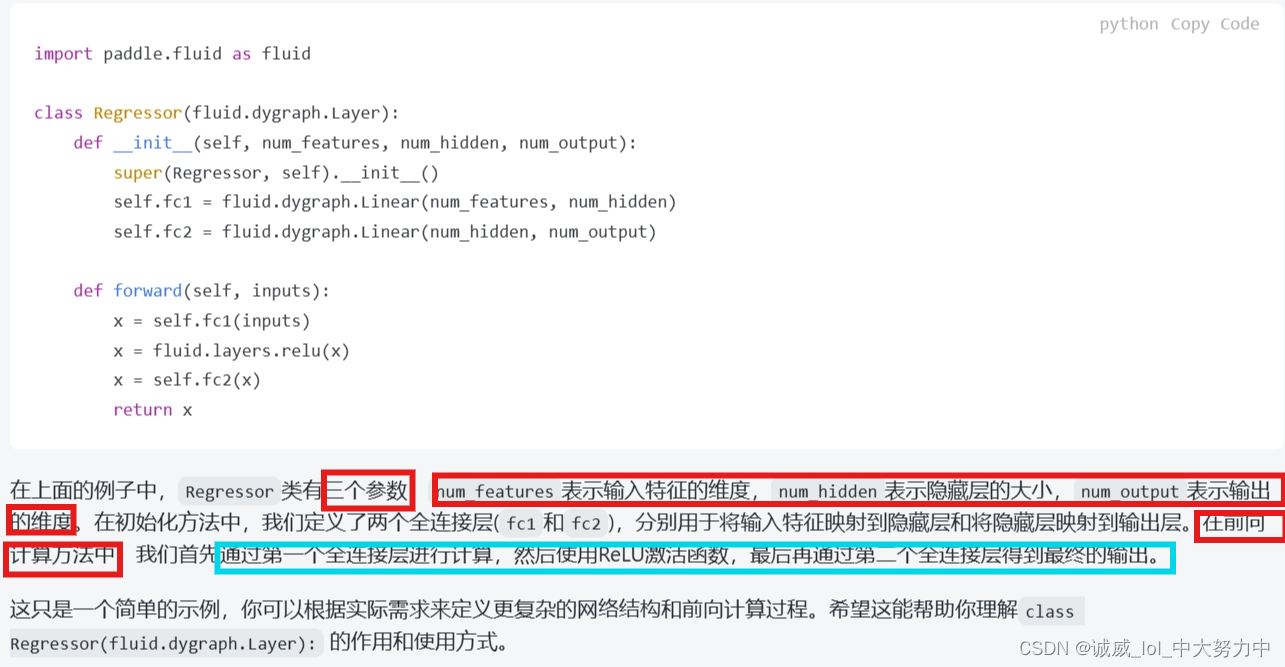
 这里是定义模型的初始化函数,利用super函数继承了父类的的初始化方法,然后定义了一个fc全连接层,里面没有使用激活函数
这里是定义模型的初始化函数,利用super函数继承了父类的的初始化方法,然后定义了一个fc全连接层,里面没有使用激活函数

注意,这里的父类就是那个fluid.dygraph.Layer这个类

关于这个forward函数,就我目前看来,主要是用来组合_init_中定义的全连接层,最终返回一个结果,比如这里就是调用了_init定义的fc全连接层,输入inputs参数,返回一个x结果
part4:训练的配置阶段

其实这里主要做的,就是:
(1)声明之前定义的Regreesor类的实例model,然后开启model的训练模式
(2)调用之前定义好的load_data()函数,将所有的数据加载到train_data和test_data中
(3)最后设置fluid库中的optimizer模块中的SGD模板函数的参数0.01,model中的各个参数,
设置好参数的模板函数得到实例函数opt留到之后使用
part5:模型训练过程
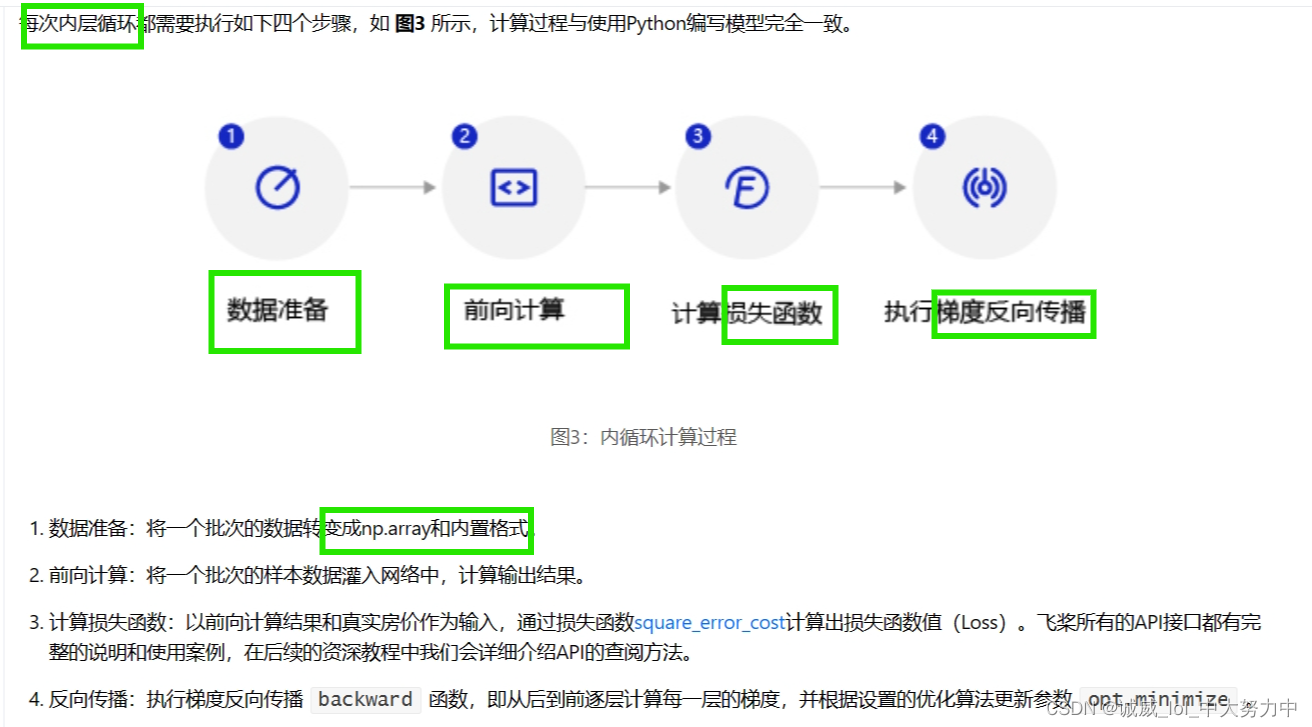 (1)
(1)
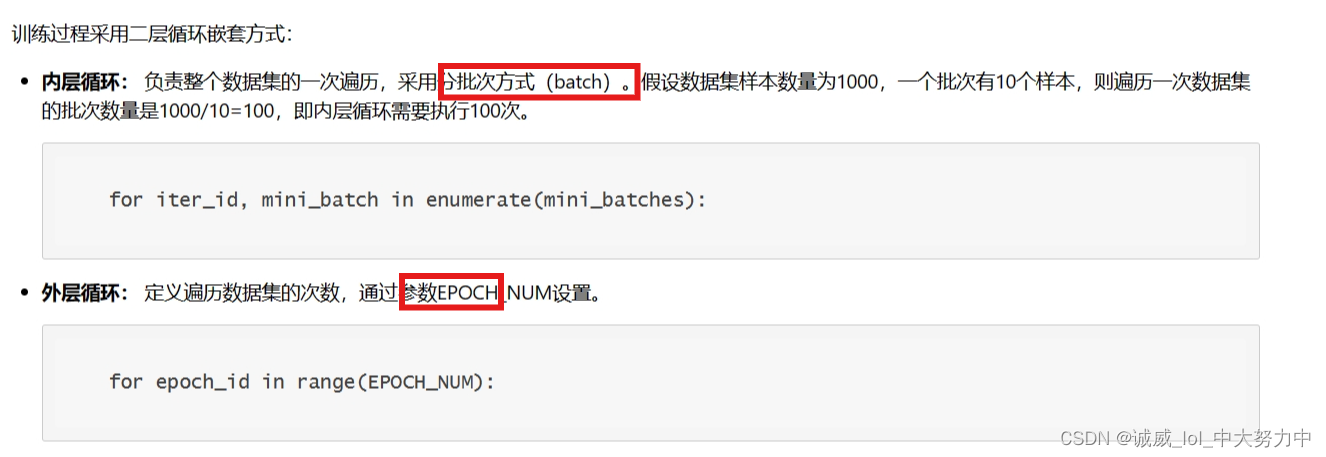
这里就是说明了使用的资源是CPU,然后设置epoch的次数和batch的大小
(2)
外层循环干的事:首先将这一轮所有的训练数据shuffle打乱,然后,将training_data中的每10条数据作为一个batch,所有的batch放到min_batches这个数组中,这个数组的元素就是单个batch,而单个batch其实是10*14的二维数组
(3)
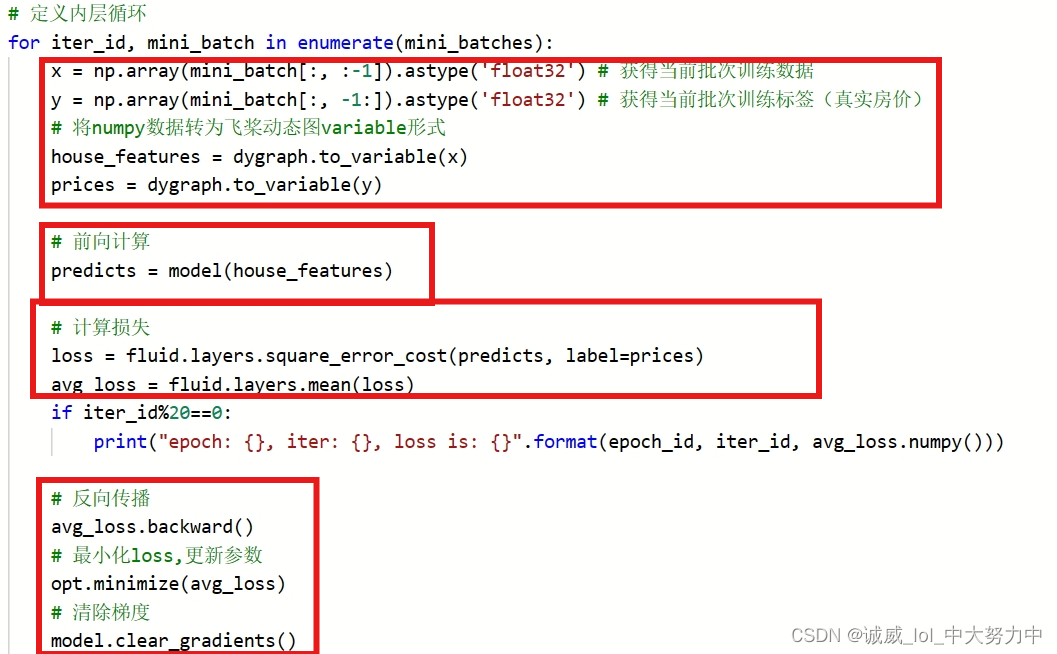
这里面的就是内层循环的主要训练代码了,
首先是house_features里面就是10*13的变量,prices就是10*1的值
然后,调用model函数,传参house_features得到10*1的predicts
之后,计算predicts和prices之间的loss,并且计算这10个数据的mean平均avg_loss
最后,也是比较迷惑的:
这里有关于backward()函数的说明,就我看来就是根据loss数据对模型的那些还不确定的参数进行更新
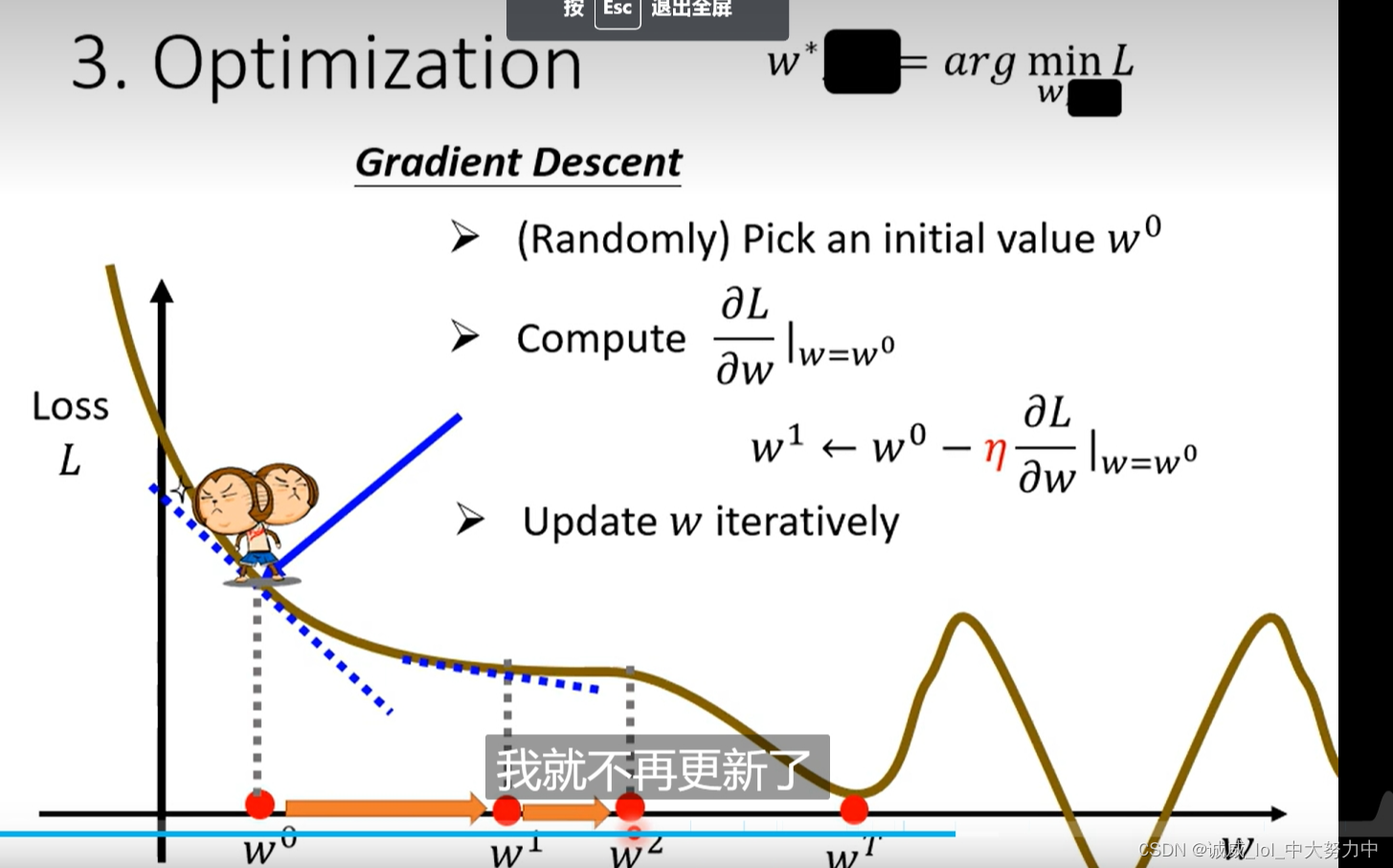
我真的很想将backward()函数和minimize函数当作同一个作用的东西,反正,就是李宏毅在线性模型的的w' = w - η*(dL/dw)这个东西,

至于为什么需要清楚梯度,不是很理解。。。

(4)
每一个epoch最后,都要进行模型的保存,虽然也不是很理解
part6:将模型保存到文件中

part7:模型测试
(1)定义一个加载需要test的那一条数据的函数 load_one_example(data_dir),data_dir就是文件的路径,实现功能就是从data的所有数据中选出倒数第10条,13个变量给到data变量,真实结果作为label给到label变量,它们都是“归一化”之后的结果,可以直接用

(2)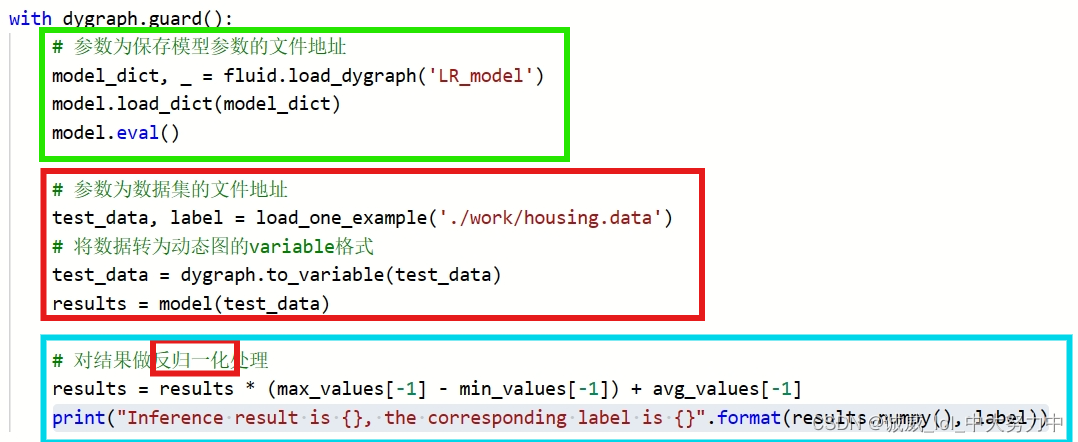
首先,是获取保存在文件中的模型,并且启动eval模式
然后,加载需要测试的test_data,并且传递给model模型,并得到预测的结果results
最后,输出results(“反归一化之后”) 和 真实label
part8:通过参数的调整,得到不同的结果:
1.学习率的调整;
(1)学习率0.05
(2)学习率0.01
(3)学习率0.10
 2.还可以调整batch大小,训练集的比例等等,自己去尝试一下吧!
2.还可以调整batch大小,训练集的比例等等,自己去尝试一下吧!
这篇关于使用飞桨实现的第一个AI项目——波士顿的房价预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




