本文主要是介绍机器学习降维技术全面对比评析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
在机器学习领域,处理高维数据带来了与计算效率、模型复杂性和过度拟合相关的挑战。降维技术提供了一种解决方案,将数据转换为低维表示,同时保留基本信息。本文旨在比较和对比一些突出的降维技术,涵盖线性和非线性方法。

线性技术
主成分分析(PCA)
-
线性投影:PCA 执行线性投影以捕获数据中的最大方差。 -
计算效率:高效且广泛使用,但假设线性关系。
线性判别分析 (LDA)
-
有监督的降维:LDA 结合了类别信息来找到最好地分离类别的线性组合。 -
分类重点:对于分类任务特别有用。
随机投影
-
计算简单性:随机投影提供了一种计算有效的降维方法。 -
近似保留:虽然计算效率高,但它仅提供成对距离的近似保留。
非线形技术
t-Distributed Stochastic Neighbor Embedding (t-SNE)
-
非线性嵌入:t-SNE 对于在低维空间中可视化高维数据非常有效。 -
计算成本:计算成本昂贵,限制了其在大型数据集中的使用。
Uniform Manifold Approximation and Projection (UMAP)
-
效率:UMAP 的计算效率比 t-SNE 更高,使其适用于更大的数据集。 -
全局和局部保留:有效保留数据中的局部和全局结构。
自动编码器
-
神经网络方法:自动编码器使用神经网络来学习高维空间和低维空间之间的非线性映射。 -
表示学习:能够学习分层表示,但可能对超参数敏感。
Isomap(等轴测图)
-
测地距离的保留:Isomap 专注于保留测地距离,捕获数据的内在几何形状。 -
对噪声的敏感性:对噪声和异常值敏感,需要仔细的预处理。
局部线性嵌入 (LLE)
-
本地关系:LLE 专注于保留数据点之间的本地关系。 -
参数敏感性:对邻居的选择敏感,并且可能难以保存全局结构。
Code
下面是一个完整的 Python 代码,使用流行的 scikit-learn 库将各种降维技术应用于 Iris 数据集,并用绘图可视化结果。确保您的 Python 环境中安装了 scikit-learn 和 matplotlib:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.manifold import TSNE
from sklearn.manifold import Isomap
from sklearn.manifold import LocallyLinearEmbedding
from sklearn.manifold import MDS
from sklearn.manifold import SpectralEmbedding
from umap import UMAP
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
# Load Iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
X_std = StandardScaler().fit_transform(X)
# Define dimensionality reduction techniques
methods = [
('PCA', PCA(n_components=2)),
('LDA', LDA(n_components=2)),
('t-SNE', TSNE(n_components=2)),
('Isomap', Isomap(n_components=2)),
('LLE', LocallyLinearEmbedding(n_components=2)),
('MDS', MDS(n_components=2)),
('Spectral Embedding', SpectralEmbedding(n_components=2)),
('UMAP', UMAP(n_components=2)),
]
# Apply dimensionality reduction and plot results
plt.figure(figsize=(15, 10))
for i, (name, model) in enumerate(methods, 1):
plt.subplot(3, 3, i)
# Modified part for LDA
if name == 'LDA':
reduced_data = model.fit_transform(X_std, y)
else:
reduced_data = model.fit_transform(X_std)
plt.scatter(reduced_data[:, 0], reduced_data[:, 1], c=y, cmap=plt.cm.Set1, edgecolor='k', s=40)
plt.title(name)
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.tight_layout()
plt.show()
此代码片段在 Iris 数据集上使用 PCA、LDA、t-SNE、Isomap、LLE、MDS、Spectral Embedding 和 UMAP 等降维技术,并绘制降维后的数据。您可以在缩小的空间中观察每种技术的不同聚类。请随意尝试其他数据集或根据您的具体需求修改代码。
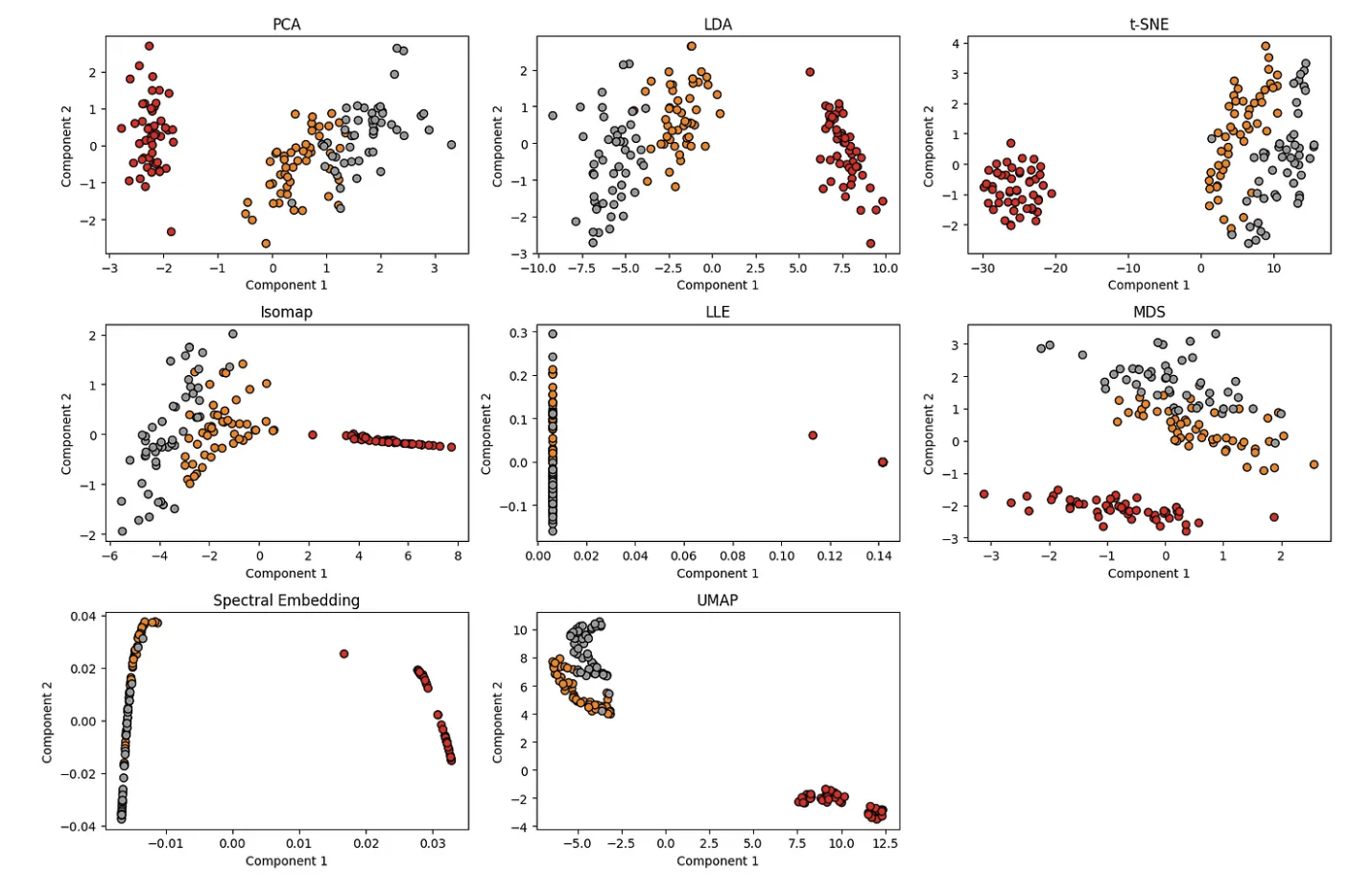
总结
总之,降维技术的选择取决于数据的具体特征和分析的目标。 PCA 和 LDA 等线性方法简单高效,但可能难以处理非线性关系。 t-SNE 和 UMAP 等非线性技术擅长捕获复杂结构,但也带来计算挑战。自动编码器提供了一种灵活的基于神经网络的方法,Isomap 和 LLE 等方法专注于保留特定的几何方面。了解每种技术的优点和局限性对于为给定数据集和任务选择最合适的方法至关重要,从而确保机器学习应用程序获得最佳结果。
本文由 mdnice 多平台发布
这篇关于机器学习降维技术全面对比评析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


