本文主要是介绍构建高效PythonWeb:GraphQL+Sanic,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.1 简介:在当今快速发展的技术时代,Web应用的性能和灵活性变得越来越重要。在众多技术中,GraphQL和Sanic以其独特的优势脱颖而出。GraphQL,作为一个强大的数据查询语言,为前端和后端之间的通信提供了极大的灵活性。而Sanic,则是一个快速的异步Web框架,专为快速HTTP响应设计。本文将探索如何将GraphQL与Sanic结合使用,以创建高效、灵活的Python Web应用。
2.1 历史攻略:
gin框架:安装使用、restful增删改查
sanic:view - restful普通和异步的写法
API-restful规范
3.1 GraphQL:GraphQL是由Facebook开发的一种数据查询和操作语言,主要用于API。与传统的REST API相比,GraphQL的主要优点在于其灵活性和效率。它允许客户端准确指定所需的数据,避免了过度获取或欠缺获取数据的问题。此外,GraphQL支持实时数据更新,非常适合需要实时功能的现代应用。
3.2 GraphQL的核心特性:
精准的数据获取:客户端可以请求所需的确切数据,无需额外负载。
单一终点:所有数据请求都通过单一API终点处理,简化了数据交互流程。
类型系统:GraphQL拥有强类型系统,使得数据模型更加清晰和健壮。
4.1 安装依赖:注意要相应版本,太新的可能不兼容。
pip install sanic == 20.12.0
pip install graphene == 2.1.9
pip install graphene sanic-graphql == 1.1.0
4.2 案例源码:
# -*- coding: utf-8 -*-
# time: 2024/01/05 09:54
# file: graphql_demo.py
# 公众号: 玩转测试开发import graphene
from sanic import Sanic
from sanic_graphql import GraphQLView# 定义一个人物信息的GraphQL类型
class Person(graphene.ObjectType):name = graphene.String()age = graphene.Int()address = graphene.String()class Query(graphene.ObjectType):hello = graphene.String()fruit = graphene.List(graphene.String) # 定义为字符串列表person_info = graphene.Field(Person) # 使用Person类型def resolve_hello(self, info):return "World"def resolve_fruit(self, info):return ["apple", "orange"] # 返回一个字符串列表def resolve_person_info(self, info):# 返回一个Person实例return Person(name="Tom", age=30, address="UK")app = Sanic("GraphQLApp")app.add_route(GraphQLView.as_view(schema=graphene.Schema(query=Query),graphiql=True),'/graphql',methods=['GET', 'POST'] # 允许 GET 和 POST 请求
)if __name__ == '__main__':app.run()
4.3 后端运行:
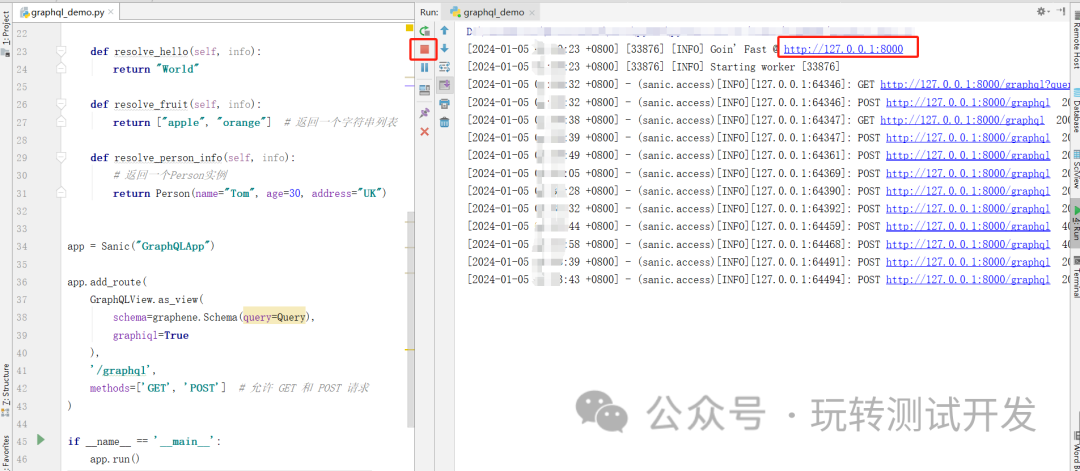
5.1 客户端访问:http://127.0.0.1:8000/graphql
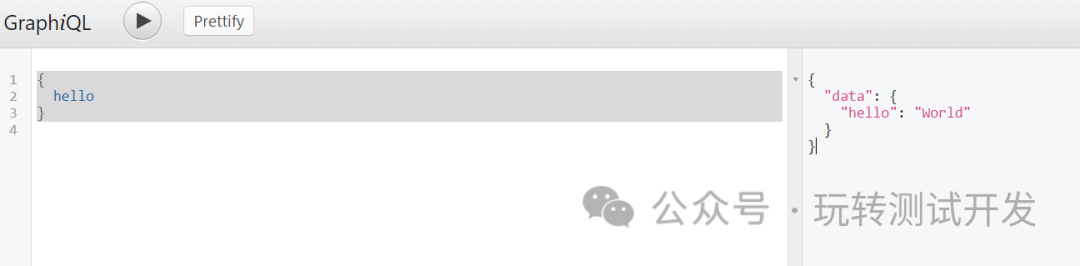
5.2 单个查询:
{hello
}
5.3 单个查询的返回结果:
{"data": {"hello": "World"}
}
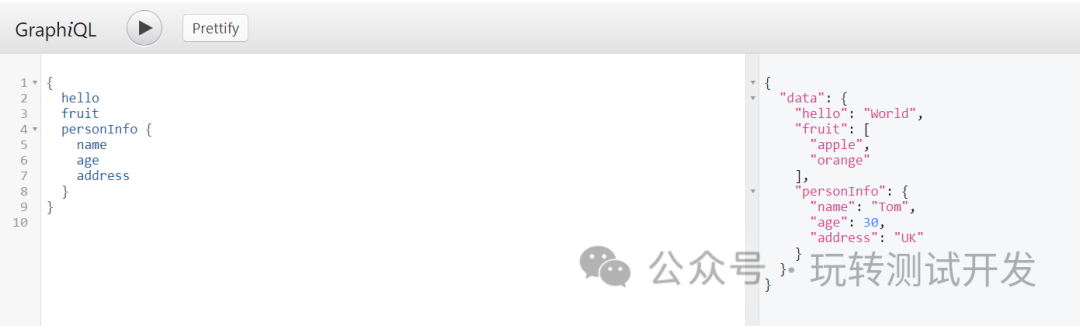
5.4 多个查询:
{hellofruitpersonInfo {nameageaddress}
}
5.5 多个查询的返回结果:
{"data": {"hello": "World","fruit": ["apple","orange"],"personInfo": {"name": "Tom","age": 30,"address": "UK"}}
}
6.1 结合使用GraphQL和Sanic,可以为开发者提供以下优势:
高效的数据处理:GraphQL提供精确数据获取,减少不必要的网络负担。
快速响应时间:Sanic的异步处理能力确保了即使在高负载下能快速响应。
灵活性和可扩展性:GraphQL的灵活查询机制加上Sanic的简洁性,使得应用易于扩展和维护。
7.1 对比:GraphQL和RESTful API是两种流行的Web服务架构风格,它们各有优劣,适用于不同的应用场景。下面是它们之间的一些关键对比:
7.2 GraphQL优势
灵活的数据查询:GraphQL允许客户端指定所需的确切数据,减少了数据的过度获取和不必要的网络开销。
单一终点:所有的操作通过单一的API端点进行,简化了复杂应用的数据管理。
实时数据:支持通过订阅实时更新数据,非常适合需要实时功能的应用。
类型系统:内置强类型系统,有利于API的自我文档化,提高了开发效率和代码的可维护性。
7.3 GraphQL劣势
缓存复杂性:由于每个查询可能都是独特的,标准的HTTP缓存机制不如在REST中那么有效。
查询复杂性:复杂的查询可能导致性能问题,如深度嵌套查询可能对服务器造成压力。
学习曲线:对于新手来说,GraphQL的概念、类型系统和查询语言需要一定时间去学习和适应。
8.1 RESTful API优势
标准化:作为成熟的架构风格,REST具有广泛的支持和社区知识库。
简单的缓存策略:利用HTTP协议的缓存机制,可以轻松实现API响应的缓存。
易于理解和实现:RESTful API的概念直观,易于理解和实现,适用于大多数标准Web应用。
无状态性:每个请求都是独立的,这简化了服务器的设计和扩展。
8.2 RESTful API劣势
过度获取/欠获取数据:客户端可能需要从多个端点获取数据,这可能导致过度获取或欠获取数据。
多个请求:构建复杂界面时,可能需要向多个不同的API端点发送请求,增加了网络延迟。
版本管理:随着API的发展,版本管理可能变得复杂,需要维护不同版本的API。
9.1 综合考虑
应用场景:对于需要高度灵活性和定制化数据请求的应用,GraphQL是更好的选择。而对于简单、标准化的数据交换需求,RESTful可能更合适。
性能考量:如果应用依赖于有效的网络缓存来提高性能,REST可能是更好的选择。对于需要实时数据更新和复杂数据模型的应用,GraphQL可能更适合。
团队熟悉度:考虑团队对这两种技术的熟悉程度也是非常重要的,一个熟悉REST的团队可能更快地实现和维护RESTful API。
最终的选择应该基于特定项目的需求、团队的专长和未来的可扩展性。在某些情况下,结合使用GraphQL和RESTful API,利用两者的优势,也是一种可行的策略。
10. 结论:GraphQL和Sanic的结合为Python Web应用开发带来了前所未有的灵活性和效率。无论是构建小型应用还是大型企业级应用,这种组合都是一个非常有吸引力的选择。随着技术的不断进步,我们期待看到更多创新的应用案例诞生。
这篇关于构建高效PythonWeb:GraphQL+Sanic的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



