本文主要是介绍热图分析(这个热力图代表的是不同描述符与pIC50之间的皮尔逊相关系数。),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
案例一:
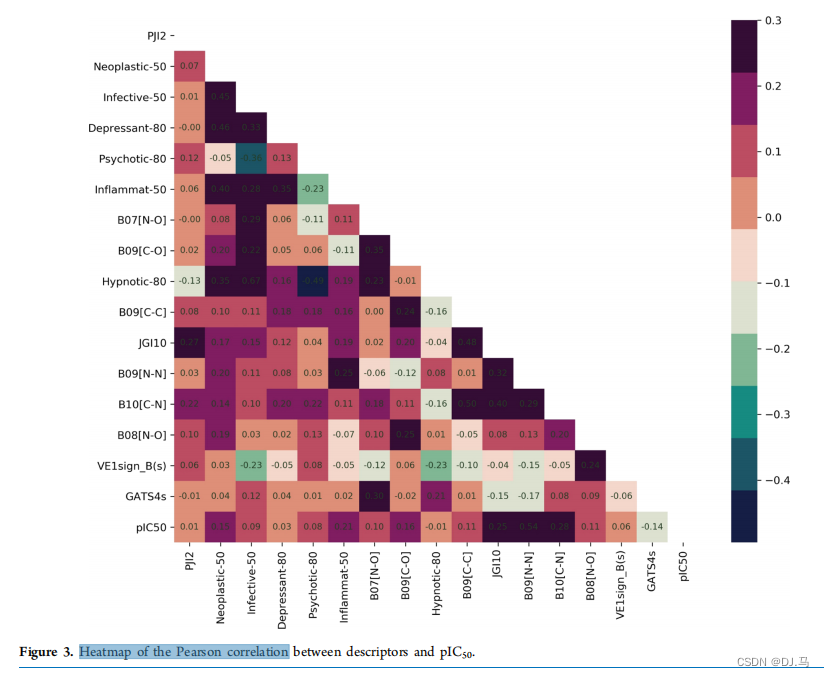
这个热力图代表的是不同描述符与pIC50之间的皮尔逊相关系数。pIC50是一种表示化合物在生物学测定中抑制效果的负对数IC50值,它通常用于药物发现和评估中,用来量化化合物对特定靶标的抑制能力。
要分析这个热力图,你需要关注几个关键点:
-
相关系数的范围:这个图中,相关系数的范围是-0.4到+0.3。相关系数表示两个变量之间的线性关系的强度和方向。接近+1或-1的值表示强烈的正相关或负相关,而接近0的值表示没有或极弱的相关性。
-
颜色标尺:颜色从紫色到红色变化,紫色代表负相关,红色代表正相关。例如,一个接近+0.3的相关系数(暖色)意味着当一个描述符的值增加时,pIC50也倾向于增加;而一个接近-0.4的系数(冷色)则意味着当描述符的值增加时,pIC50倾向于减少。
-
特定值的分析:看到某个特定的单元格有较高的正相关(例如0.35)或负相关(例如-0.23)时,这意味着相应的描述符与pIC50之间存在较强的线性关系。例如,在这个热力图中,"Infective-50"与pIC50之间有一个0.46的相关系数,这是一个较强的正相关,表明"Infective-50"高的时候,pIC50也高。
-
整体趋势的分析:你可以观察整个热力图寻找模式,比如某一列或某一行的颜色是否普遍偏向某一端,这可以提示哪些描述符与pIC50有更强的关联。
-
科学意义:相关系数的大小还需要从科学和生物学的意义上进行解释。即使数值上的相关性很强,也需要进一步的生物学实验或分析来证实这种关系的确存在并且有意义。
-
数据的可信度:在进行任何实际的科学决策之前,还应该评估这些相关系数的统计显著性,通常需要查看p值来判断这些相关系数是否统计显著。
综上所述,这个热力图提供了一种快速可视化不同描述符与pIC50之间关系强度和方向的方法,但是具体的分析和结论需要依据研究的背景和附加的统计测试来做进一步的验证。
2 / 2
在这个热力图中:
-
**横坐标(X轴)和纵坐标(Y轴)**都表示不同的化学描述符。这些描述符可能代表化合物的不同物理化学性质,如亲电性、疏水性、分子大小、极性等,这些都是化学信息学中用来描述化合物特征的参数。
-
pIC50是在热力图的右侧和底部的一个特定描述符。在这个图中,pIC50与自己的相关系数是不显示的,因为它是与其他描述符比较的基准。
每个单元格表示对应横坐标描述符和纵坐标描述符之间的相关系数。例如,纵坐标上的“Neoplastic-50”和横坐标上的“pIC50”交点的单元格中的数字会告诉我们这两个描述符之间的相关程度。
在热力图的右侧,有一个颜色条或色阶,它代表相关系数的值,通常从-1(完全负相关)到+1(完全正相关)。在这个图中,颜色条的范围是从-0.4到+0.3。相关系数的值通过色阶上的颜色来表示:负相关系数通常用冷色(如蓝色或紫色)表示,正相关系数通常用暖色(如红色或粉色)表示,接近零的相关系数通常用中性色(如白色或灰色)表示。
所以,热力图中任意一个单元格的颜色表示了对应描述符与pIC50之间的相关性强度:单元格颜色越接近色阶的顶端(红色),表示正相关越强;颜色越接近色阶的底端(紫色),表示负相关越强。如果一个单元格的颜色是中性的,这意味着对应的两个描述符之间几乎没有或者有很弱的线性关系。
这篇关于热图分析(这个热力图代表的是不同描述符与pIC50之间的皮尔逊相关系数。)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






