本文主要是介绍python-查漏补缺笔记-更新中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
包导入时__init__.py中命令的执行顺序和sys.modules变化
ref: https://edu.csdn.net/skill/practice/python-3-6/164
- 在有父包和子包的情况下,父包中的“ __ init__.py”语句会在子包的“ __ init__.py”语句之前执行,然后按下列顺序执行
- 导入子包和模块
- 执行“ __ init__.py”中其他代码
需要注意的是,如果只导入子包,Python解释器会将父包的信息添加到sys.modules中,这样导入子包的时候能知道父包的存在,但是除了父包的__init__.py中的语句,并不会执行其他代码,只有需要访问父包时才会进行真正的导入。
sys.modules是一个字典,记录的是已经导入的模块信息。首次导入一个模块时,python会检查这个模块是否存在于sys.modules中,如果已经存在,会直接返回模块对象;否则导入。
实例
文件结构如下图所示,father包含one、two和three三个包,one包又包含一个one包。每个 __ init__.py中包含的内容只有一条print语句,打印诸如 this is father、this is 1、this is 1.1这样的语句。
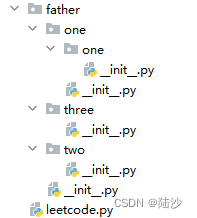
leetcode.py中的内容如下所示:
import sysif __name__ == '__main__':for i in range(2):import fatherimport father.one.oneimport father.two#print(sys.modules.keys())del sys.modules['father']del sys.modules['father.one.one']del sys.modules['father.two']print('-----------\n')''' 输出结果
this is father
this is 1
this is 1.1
this is 2
-----------this is father
this is 1.1
this is 2
-----------
'''这是因为father.one在第一次循环时被加入了sys.modules,后续并没有被删除,所以再次导入时不会执行father.one的__init__.py语句,也就不会输出this is 1。
可变形参:匿名和带关键字的
Python函数的参数可以有4种:
- 按位置顺序指定的参数,如下面的index
- 带默认值的参数,如下面的default
- 没有名字的可选参数,如*args
- 有名字的可选参数,如**kw
实例
# -*- coding: UTF-8 -*-
def dump(index, default=0, *args, **kw):print('打印函数参数')print('---')print('index:', index)print('default:', default)for i, arg in enumerate(args):print(f'arg[{i}]:', arg)# 注意这里要用kw.items()for key,value in kw.items():print(f'keyword_argument {key}:{value}')print('')if __name__=='__main__':dump(0)dump(0,2)dump(0,2,"Hello","World")dump(0,2,"Hello","World", install='Python', run='Python Program')'''输出
打印函数参数
---
index: 0
default: 0打印函数参数
---
index: 0
default: 2打印函数参数
---
index: 0
default: 2
arg[0]: Hello
arg[1]: World打印函数参数
---
index: 0
default: 2
arg[0]: Hello
arg[1]: World
keyword_argument install:Python
keyword_argument run:Python Program
'''
元组tuple
tuple1 = ('红色')
for element in tuple1:print(element)
'''输出
红
色
'''
这个输出是因为tuple1实际不是元组,是str,用type()可知。如果要声明为元组,应该用 tuple1 = (‘红色’,)
这篇关于python-查漏补缺笔记-更新中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




