本文主要是介绍爬取豆瓣电影top250的电影名称(完整代码与解释),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在爬取豆瓣电影top250的电影名称之前,需要在安装两个第三方库requests和bs4,方法是在终端输入:
pip install requestspip install bs4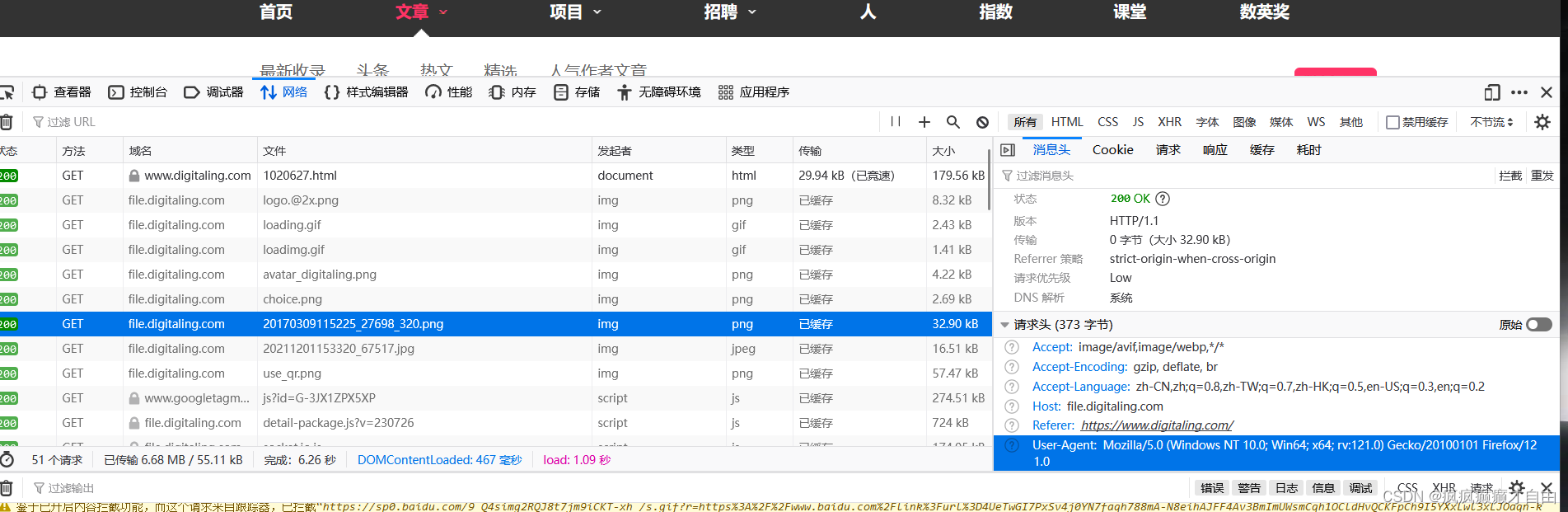
截几张关键性图片:


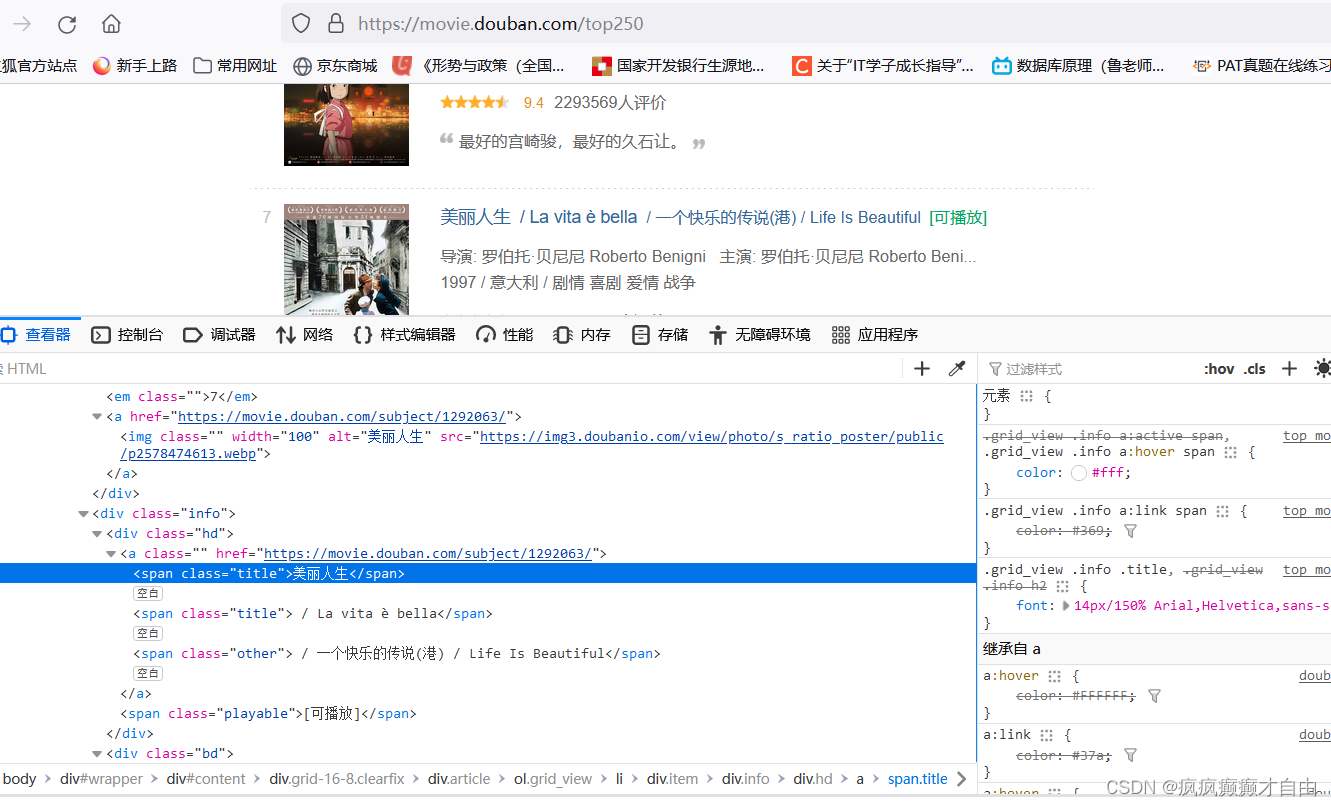
豆瓣top250电影网页
运行结果
测试html文件标签的各个方法的作用:
# import requests# response = requests.get("https://movie.douban.com/top250")# print(response)import requests
#引入模块 requestsfrom bs4 import BeautifulSoup
# 从模块bs4中引入类 BeautifulSoup
# beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
# beautifulsoup:是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
}# User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,
# 可以伪装成浏览器;如果不加很可能被识别出为爬虫# 由于豆瓣不对程序进行回应,故要伪装成浏览器进行请求,方法是在浏览器中随便打开一个网页,右击鼠标,点击
# 检查,出现页面后,刷新一下网页,随便点击一个请求报文,查看"User-Agent":后面的信息,并且复制该信息到
# headers中的"User-Agent":后,这就可以伪装成浏览器发送的请求response = requests.get(f"https://movie.douban.com/top250", headers = headers)# requests的get方法返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
# response响应的属性:
# response.status_code 响应的状态码
# response.headers:响应头信息
# response.encoding 编码格式信息
# response.cookies cookies信息
# response.url 响应的url信息
# response.text 文本类型,通常是html文本
# response.content bytes型也就是二级制数据,如图片/视频/音频等print(response)
print(response.status_code)#print(response.text)html = response.text
soup = BeautifulSoup(html, "html.parser")
# soup=beautifulsoup(解析内容,解析器)
# 常用解析器:html.parser,lxml,Xml,html5lib# [BeautifulSoup默认支持Pythonl的标准HTML解析库,但是它也支持一些第三方的解析库:如图]
# (https://s2.51cto.com/images/blog/202104/05/d369a62192f243f59879d10173b68e86.png?x-oss-process=image/format,webp)all_titles = soup.find_all("span", attrs = {"class" : "title"})
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title";# 使用find和find_all方式
# find(name,attrs,recursive,text,**kwargs)
# 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
# find_all(name, attrs, recursive, text, **kwargs)
# 根据参数来找出对应的标签,但只返回所有符合条件的结果。
# BeautifulSoup对象的find_all()方法返回的是一个由匹配的标签元素组成的列表。如果没有匹配的元素,返回一个空列表# 筛选条件参数介绍:
# name:为标签名,根据标签名来筛选标签
# attrs:为属性,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
# text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用.
# recursive:指定筛选是否递归,当为Falsel时,不会在子结点的后代结点中查找,只会查找子结点。cnt = 0;
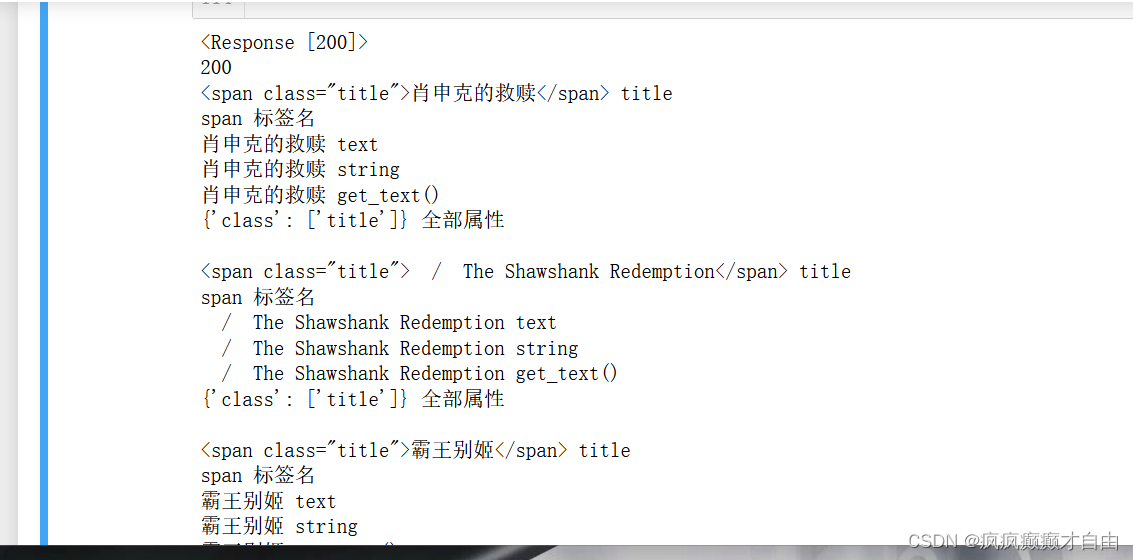
for title in all_titles:print(title, "title")print(title.name, "标签名")print(title.text, "text")print(title.string, "string")print(title.get_text(), "get_text()")print(title.attrs, "全部属性")print("")title_string = title.stringcnt += 1if(cnt >= 3):break#由于all_titles 是find_all的返回内容,他是一个列表,列表中的每个元素就是html文件中的一行,就相当于一个标签# 一.使用标签名查找# 1)使用标签名来获取结点:
# Soup.标签名# 2)使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
# soup.标签.name# 3)使用标签名来获取结点属性:
# soup.标签.attrs(获取全部属性)
# soup.标签.attrs[属性名](获取指定属性)
# soup.标签[属性名](获取指定属性)
# soup.标签.get(属性名)# 二.使用标签名来获取结点的文本内容:
# soup.标签.text
# soup.标签.string
# soup.标签.get text()# if "/" not in title_string:
# print(title_string)# 由于我们只想要电影中文名,所以我们将不符合条件的字符串不打印出来,
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title",不难发现,就在中文电影名的下面有一个原版的
# 电影名,或者英文,或者其他国家的语言,但是我们不想要,再仔细观察会发现原版电影名前有一个字符 '/',而中文电影名没有字符'/';
# 所以可以用一个if 语句判断是否打印字符;二。爬取豆瓣电影top250的电影名称完整代码与解析:
解释全在代码中:
import requests
#引入模块 requests
# requests模块作用,发送http请求,获取响应数据from bs4 import BeautifulSoup
# 从模块bs4中引入类 BeautifulSoup
# beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
# beautifulsoup:是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
}# User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,
# 可以伪装成浏览器;如果不加很可能被识别出为爬虫# 由于豆瓣不对程序进行回应,故要伪装成浏览器进行请求,方法是在浏览器中随便打开一个网页,右击鼠标,点击
# 检查,出现页面后,刷新一下网页,随便点击一个请求报文,查看"User-Agent":后面的信息,并且复制该信息到
# headers中的"User-Agent":后,这就可以伪装成浏览器发送的请求for start_num in range(0, 250, 25):response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers = headers)# 由于一个页面只展示25个电影,所以要爬取250个电影名字要爬取多个页面,用一个for循环结合range函数便可实现;if(start_num == 0):print(response.status_code, "status_code")print(response.headers, "headers")print(response.encoding, "encoding")print(response.cookies, "cookies")print(response.url, "url")# print(response.text, "text") #text 和 content信息太多,暂时不打印# print(response.content, "content")# requests的get方法返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
# response响应的属性:
# response.status_code 响应的状态码
# response.headers:响应头信息
# response.encoding 编码格式信息
# response.cookies cookies信息
# response.url 响应的url信息
# response.text 文本类型,通常是html文本
# response.content bytes型也就是二级制数据,如图片/视频/音频等print(response , "这是什么")#response本身是Response对象,并包含返回状态码,Response对象含有从服务器返回的所有的相关资源。html = response.textsoup = BeautifulSoup(html, "html.parser")
# soup=beautifulsoup(解析内容,解析器)
# 常用解析器:html.parser,lxml,Xml,html5lib# [BeautifulSoup默认支持Pythonl的标准HTML解析库,但是它也支持一些第三方的解析库:如图]
# (https://s2.51cto.com/images/blog/202104/05/d369a62192f243f59879d10173b68e86.png?x-oss-process=image/format,webp)# all_titles = soup.find_all("span", attrs = {"class" : "title"})all_titles = soup.findAll("span", attrs = {"class" : "title"})
#这两句find函数都可行# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title";# 使用find和find_all方式
# find(name,attrs,recursive,text,**kwargs)
# 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
# find_all(name, attrs, recursive, text, **kwargs)
# 根据参数来找出对应的标签,但只返回所有符合条件的结果。
# BeautifulSoup对象的find_all()方法返回的是一个由匹配的标签元素组成的列表。如果没有匹配的元素,返回一个空列表# 筛选条件参数介绍:
# name:为标签名,根据标签名来筛选标签
# attrs:为属性,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
# text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用.
# recursive:指定筛选是否递归,当为Falsel时,不会在子结点的后代结点中查找,只会查找子结点。for title in all_titles:title_string = title.string # 提取为字符串#由于all_titles 是find_all的返回内容,他是一个列表,列表中的每个元素就是html文件中的一行,就相当于一个标签# 一.使用标签名查找# 1)使用标签名来获取结点:
# Soup.标签名# 2)使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
# soup.标签.name# 3)使用标签名来获取结点属性:
# soup.标签.attrs(获取全部属性)
# soup.标签.attrs[属性名](获取指定属性)
# soup.标签[属性名](获取指定属性)
# soup.标签.get(属性名)# 二.使用标签名来获取结点的文本内容:
# soup.标签.text
# soup.标签.string
# soup.标签.get text()if "/" not in title_string:print(title_string)# 由于我们只想要电影中文名,所以我们将不符合条件的字符串不打印出来,
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title",不难发现,就在中文电影名的下面有一个原版的
# 电影名,或者英文,或者其他国家的语言,但是我们不想要,再仔细观察会发现原版电影名前有一个字符 '/',而中文电影名没有字符'/';
# 所以可以用一个if 语句判断是否打印字符;参考文献:
爬虫基础篇_headers = {'user-agent': 'mozilla/5.0 (windows nt -CSDN博客
python爬虫之Beautifulsoup模块用法详解_51CTO博客_python爬虫模块
这篇关于爬取豆瓣电影top250的电影名称(完整代码与解释)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





