本文主要是介绍可狱可囚的爬虫系列课程 08:中国新闻网即时新闻获取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本篇文章中我带大家针对前面所学 Requests 和 BeautifulSoup4 进行一个实操检验。
相信大家平时或多或少都有看新闻的习惯,那么我们今天所要爬取的网站便是新闻类型的:中国新闻网,我们先来使用爬虫爬取一些具有明显规则或规律的信息,在中国新闻网这个网站中,有一个即时新闻精选的板块,就是我们今天的目标,这是链接:https://www.chinanews.com/scroll-news/news1.html,爬取内容如图所示,我们要爬取每一条新闻的新闻类型、新闻标题、跳转链接、发布时间。

一、网页源代码的获取
接下来我直接应用 Requests 库,先将此网页的源代码请求下来。
注意:通过结果的打印,我们发现存在乱码问题,随即添加了纠正乱码的代码。
import requestsURL = 'https://www.chinanews.com/scroll-news/news1.html'
Headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=URL, headers=Headers)
response.encoding = 'utf-8'
html_source = response.text if response.status_code == 200 else '状态码异常'
print(html_source)
二、源代码的解析
利用 BeautifulSoup4 库,针对请求到的源代码进行解析。
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_source, 'html.parser')
三、开发者工具的使用
为什么要使用开发者工具?
相信大家已经仔细看过了 PyCharm 中打印的网页源代码,是不是感觉非常的杂乱,没有办法直观的找寻到网页结构,那么我们在写爬虫时,就需要参考开发者工具给的一些建议。请大家在需要爬取信息的页面打开开发者工具并查看 Elements 标签页。

在 Elements 标签页,大家也能够看到网页对应的源代码,并且我们在此处能更加直观的看清楚网页标签间的层级结构,更便于后续 CSS 选择器的编写。
检查元素
接下来我们要使用到开发者工具的另一个工具“检查元素”,它在 Elements 标签页左边,外形是一个方框加一个鼠标,使用这个工具我们可以比较精准的定位元素在源代码中的位置及所属层级结构,请看如下动图:

在这个动图中,给大家展示的步骤是,先点击“检查元素”这个按钮,然后在网页上移动鼠标便可以看到源代码位置也在同步定位,如果要找某块内容的位置可以直接在此内容上点击鼠标左键一键定位。
四、新闻信息获取
第一步:查看目标新闻的存在形式
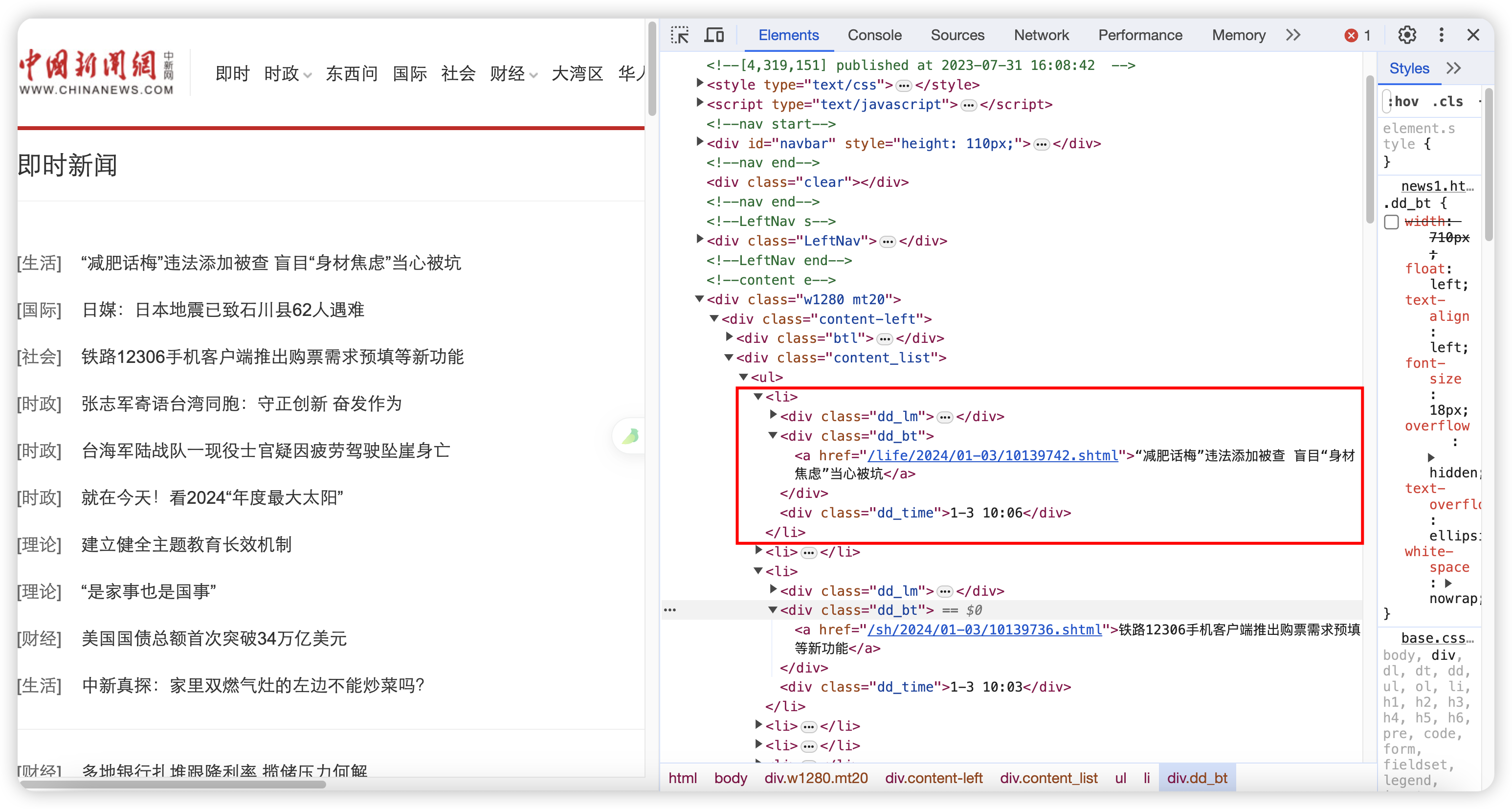
经过寻找发现,目标新闻都属于如图所示位置 ul 标签下的一个个 li 标签,每一个 li 标签是一条完整的新闻。
第二步:逐级递进,层层缩减
我们在爬取数据时应遵循:从大范围逐级递减到小范围的原则循序渐进。所以我们先获取到所有目标新闻 li 标签,在开发者工具中根据层级结构书写 CSS 选择器。
li_list = soup.select('body > div.w1280.mt20 > div.content-left > div.content_list > ul > li')
print(li_list)

第三步:准确性判断&数据剔除
在第二步的基础上,判断获取出的所有 li 标签是否完全正确,如若存在错误数据,保证第二步书写 CSS 选择器正确无误条件下,进行错误数据的剔除。本爬虫通过判断,发现部分 li 标签并不存在目标新闻,通过检查,发现如图问题所在,每隔 10 条新闻便会出现一个分割横线,我们通过判断将其剔除。

for li in li_list:if str(li) != '<li class="nocontent"></li>':
第四步:准确信息提取
我们继续延续第三步的代码,在分支结构的基础上直接获取具体信息。同时我们发现获取的跳转链接不完整,我们将其一并不全。经过最终对比,爬取到的新闻与网页中的新闻无异。
for li in li_list:if str(li) != '<li class="nocontent"></li>':news_type = li.select_one('li > .dd_lm > a').textnews_title = li.select_one('li > .dd_bt > a').textnews_link = 'https://www.chinanews.com' + li.select_one('li > .dd_bt > a').attrs['href']news_time = li.select_one('li > .dd_time').textprint(news_type, news_title, news_link, news_time)

五、完整源代码
import requests
from bs4 import BeautifulSoupURL = 'https://www.chinanews.com/scroll-news/news1.html'
Headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=URL, headers=Headers)
response.encoding = 'utf-8'
html_source = response.text if response.status_code == 200 else '状态码异常'
# print(html_source)soup = BeautifulSoup(html_source, 'html.parser')li_list = soup.select('body > div.w1280.mt20 > div.content-left > div.content_list > ul > li')
# print(li_list)for li in li_list:if str(li) != '<li class="nocontent"></li>':news_type = li.select_one('li > .dd_lm > a').textnews_title = li.select_one('li > .dd_bt > a').textnews_link = 'https://www.chinanews.com' + li.select_one('li > .dd_bt > a').attrs['href']news_time = li.select_one('li > .dd_time').textprint(news_type, news_title, news_link, news_time)
这篇关于可狱可囚的爬虫系列课程 08:中国新闻网即时新闻获取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



