本文主要是介绍pytorch训练报OSError: [WinError 1455] 页面文件太小,无法完成操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在windows下用pytorch训练的时候,比如用yolov5(yolov8等等也一样,只要是涉及到多进程,如dataloader的num_workers设的比较大),就有可能会遇到“OSError: [WinError 1455] 页面文件太小,无法完成操作”的错误。
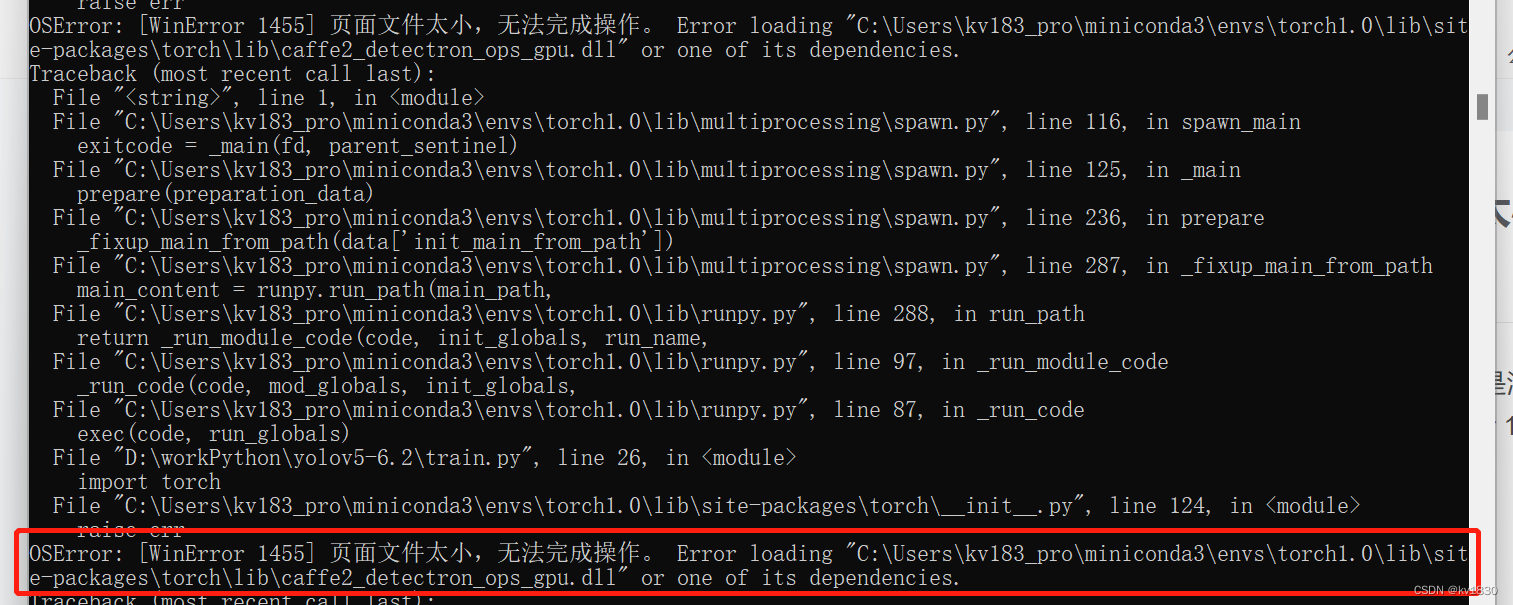
上图就是用yolov5训练报的错,训练命令为:
python train.py --data data/worker_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 16 --epochs 200 --cache
这里只指定了batch-size为16,workers没设,用的默认值就是8,实际num_workers取的是逻辑cpu核数(我的是16)、batch-size、workers三者的最小值,那就是取8啦。不过训练集、验证集的dataloader都会用到多进程。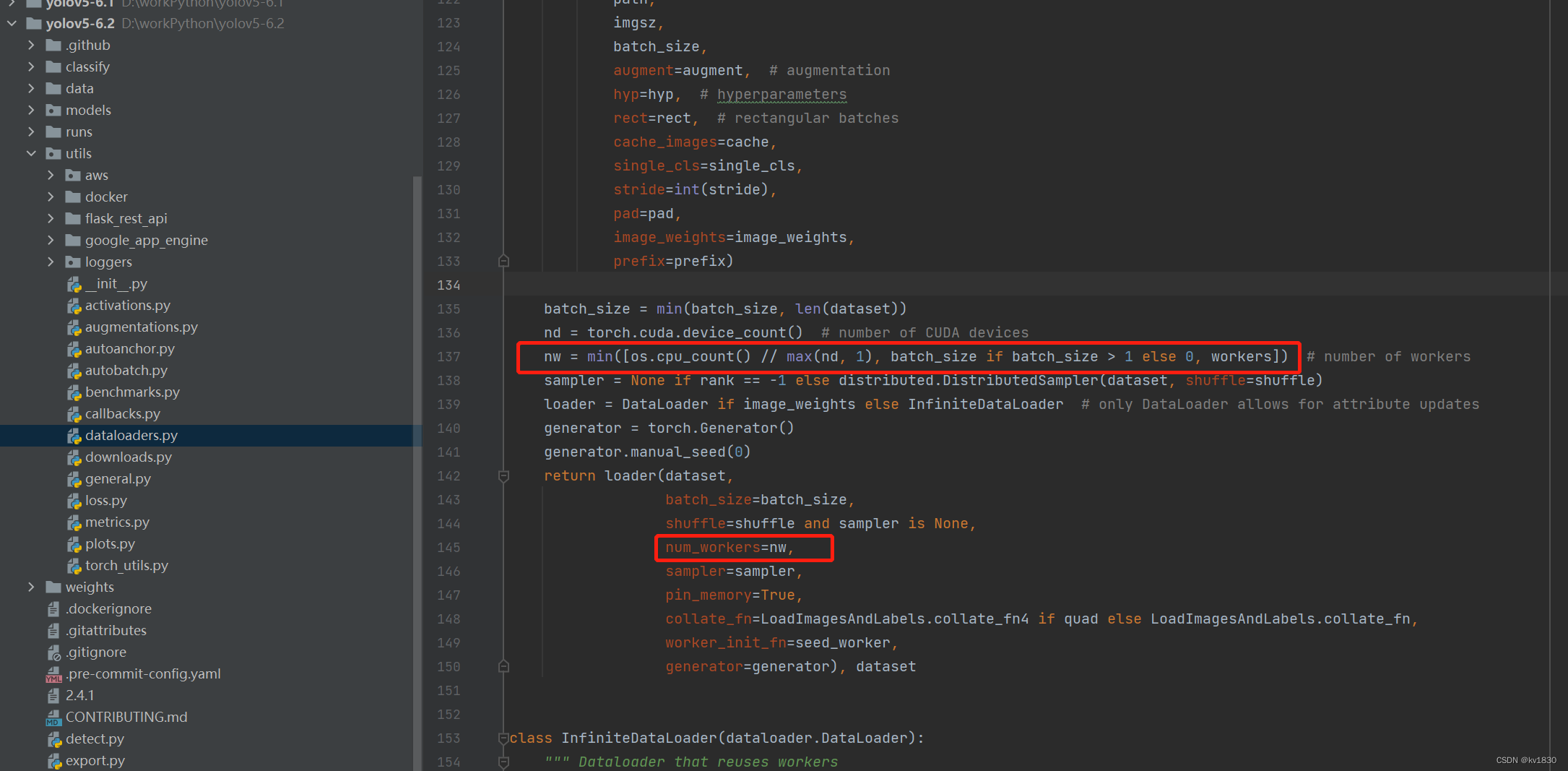
如果把batch-size改小,或者是把workers改小,那就有可能不报这个错啦,但是这明显不是解决问题的好办法,因为太小的batch-size或者workers都会降低你的训练速度。
一。问题原因
完整的来龙去脉可以看这个issue:[WinError 1455] The paging file is too small for this operation to complete. Error loading "C:\ProgramData\Anaconda3\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies · Issue #1643 · ultralytics/yolov3 · GitHub
简述一下,就是pytorch里面有一些cuda相关的dll文件非常大,并且只要你导入了pytorch相关的包,就会去加载这些文件,而且在开启多进程的时候,每个进程都会去加载这些文件,实际上可能并没有用到,所以在windows下用的是虚拟内存。但如果你的虚拟内存不够大的话,那就会报页面文件太小的错了。下图就是我报错的时候截的图,我的内存是32G,虚拟内存设的是20G,全占满了。

而在linux下就不会有这个问题,这也是很多人可能根本就没遇到这个问题的原因,因为他们都是在linux服务器上训练的。在Linux服务器上,如果是申请实际上用不到的内存,那就是表面上申请一下,什么内存都没有分配,自然不存在够不够的问题啦。
二。解决办法
1.调大虚拟内存
很明显,一个简单粗暴的办法就是,调大虚拟内存呗,到于调多大,看你实际的需要啦,反正我上面的情况基本上要分配80G到100G的虚拟内存才够。设置虚拟内存的方法可以参照其它的帖子,我就不赘述了,不过提几点:
(1)C盘空间不够没关系,虚拟内存可以分配到其它分区,而且还能配置到多个分区上
(2)最好用固态硬盘啦,机械硬盘会慢一些
2.升级pytorch版本
办法1其实也不是个好办法啦,硬盘上莫名其妙地就少了100G,有点可惜,而且如果每次它都是实打实地给你把硬盘上的内容写一遍,还是蛮伤硬盘的,尤其是固态硬盘。。。
先直接给出一个最佳方案,正如上面那个issue里所说,这个问题可能跟pytorch有关,也可能跟英伟达有关,反正你们那个dll太大啦,或者别让我每次都得加载这些dll也行。我们可以尝试一下安装更新版本的pytorch,看看这个问题解决了没有!
之前报错的环境是在conda里面,pytorch用的是1.10.1+cu113

现在来尝试一下1.13.1+cu117(cuda自然也要更新一下啦,没有尝试最新的pytorch2.0是因为yolov5貌似还不支持pytorch2.0)

还是执行上面同样的命令,这次不报错了,虚拟内存用的还是20G,可以看到虽然仍然用了一些虚拟内存,但是跟之前需要的80G甚至100G来说,已经小很多了!
3.使用fixNvPe.py
但是如果由于某些原因,你不能升级pytorch版本,只能用某个版本的pytorch,又不想用那么大的虚拟内存,那就可以参考上面那个issue里的解决方案
https://github.com/ultralytics/yolov3/issues/1643

1.先把fixNvPe.py下下来,比如我就放在D:\ai\pytorch\fixNvPe.py
2.pip install pefile
3.执行fixNvPe.py
cd D:\ai\pytorch\
python fixNvPe.py --input C:\Users\kv183_pro\miniconda3\envs\torch1.0\Lib\site-packages\torch\lib\*.dll
这个dll的路径就是你pytorch里面的lib目录啦,其实都不用你自己去找,仔细看上面那个报错的图,就是红框里这个路径
好,执行完了

下面再试一下,果然可以!而且内存占用比pytorch1.13还要少,牛逼!

这个脚本改动的dll文件都给你备份了一份,脚本作者还是很贴心的~~

脚本的内容并不长,为了防止有人访问不了,我直接给你贴在下面了,文件名fixNvPe.py
# Simple script to disable ASLR and make .nv_fatb sections read-only
# Requires: pefile ( python -m pip install pefile )
# Usage: fixNvPe.py --input path/to/*.dllimport argparse
import pefile
import glob
import os
import shutildef main(args):failures = []for file in glob.glob( args.input, recursive=args.recursive ):print(f"\n---\nChecking {file}...")pe = pefile.PE(file, fast_load=True)nvbSect = [ section for section in pe.sections if section.Name.decode().startswith(".nv_fatb")]if len(nvbSect) == 1:sect = nvbSect[0]size = sect.Misc_VirtualSizeaslr = pe.OPTIONAL_HEADER.IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASEwritable = 0 != ( sect.Characteristics & pefile.SECTION_CHARACTERISTICS['IMAGE_SCN_MEM_WRITE'] )print(f"Found NV FatBin! Size: {size/1024/1024:0.2f}MB ASLR: {aslr} Writable: {writable}")if (writable or aslr) and size > 0:print("- Modifying DLL")if args.backup:bakFile = f"{file}_bak"print(f"- Backing up [{file}] -> [{bakFile}]")if os.path.exists( bakFile ):print( f"- Warning: Backup file already exists ({bakFile}), not modifying file! Delete the 'bak' to allow modification")failures.append( file )continuetry:shutil.copy2( file, bakFile)except Exception as e:print( f"- Failed to create backup! [{str(e)}], not modifying file!")failures.append( file )continue# Disable ASLR for DLL, and disable writing for sectionpe.OPTIONAL_HEADER.DllCharacteristics &= ~pefile.DLL_CHARACTERISTICS['IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE']sect.Characteristics = sect.Characteristics & ~pefile.SECTION_CHARACTERISTICS['IMAGE_SCN_MEM_WRITE']try:newFile = f"{file}_mod"print( f"- Writing modified DLL to [{newFile}]")pe.write( newFile )pe.close()print( f"- Moving modified DLL to [{file}]")os.remove( file )shutil.move( newFile, file )except Exception as e:print( f"- Failed to write modified DLL! [{str(e)}]")failures.append( file )continueprint("\n\nDone!")if len(failures) > 0:print("***WARNING**** These files needed modification but failed: ")for failure in failures:print( f" - {failure}")def parseArgs():parser = argparse.ArgumentParser( description="Disable ASLR and make .nv_fatb sections read-only", formatter_class=argparse.ArgumentDefaultsHelpFormatter )parser.add_argument('--input', help="Glob to parse", default="*.dll")parser.add_argument('--backup', help="Backup modified files", default=True, required=False)parser.add_argument('--recursive', '-r', default=False, action='store_true', help="Recurse into subdirectories")return parser.parse_args()###############################
# program entry point
#
if __name__ == "__main__":args = parseArgs()main( args )这篇关于pytorch训练报OSError: [WinError 1455] 页面文件太小,无法完成操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




