本文主要是介绍中文分词工具jieba:代码之分词、词性标注、关键词提取与两个问题一个注意。问题一:安装jieba库成功但导入失败,问题二:paddle模式使用不了。注意:关闭paddle模式的控制台信息提示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、官方入口
jieba官方项目入口:fxsjy/jieba: 结巴中文分词 (github.com)
二、两个问题:
问题一:已经通过命令行或者pycharm安装成功jieba,但是运行代码报错说“ModuleNotFoundError:No module named 'jieba' ”
解决方案:再次打开命令行输入pip install jieba,提示已经成功安装,记下路径后找到2个文件夹“jieba”和“jieba-0.42.1.dist-info”。将这两个文件夹放到我们工程文件的.py文件的同一目录下。
问题二:用paddle模式需要安装百度飞桨paddlepaddle,但是后者仅支持3.6到3.10版本的python,且要求pip 版本为 20.2.2 或更高版本。
解决方案:1、去paddle官网复制pip代码(如下),在pycharm的终端运行。
python -m pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple2、在pycharm里写上如下代码:
import paddle
paddle.enable_static()
jieba.enable_paddle() 三、注意事项
每次打开paddle模式,控制行都会输出很长的信息提示,如下:
想要减少其信息提示,可以在代码中增加如下两行:
import logging # 用来关闭jieba在控制台中默认打印的很长一串提醒信息的
jieba.setLogLevel(logging.WARNING) # 用来关闭jieba在控制台中默认打印的很长一串提醒信息的之后就只会输出如下的信息了:

四、demo代码
text文件准备:
“哇!”危丽站在一栋新实验楼前,和旁边长大的小丽一起仰头打量半天,忍不住感叹,“以后我就在这里工作?”第九农学基地进行了两年的扩建,新实验楼共建七栋,因为转来的研究员不多,目前只有两栋开放,但每栋实验楼规模都不小。“我们是第一批搬来的研究员,可以选实验室。”严静水拖着行李,“听说这里的实验室很不错。”从中央农学研究院转到第九农学基地,他们还是第一批,也算是领头人,未来这里发展状况,还得看之后的成果。“你们来了。”赵离浓的声音从后方传来。两人回头看去,便见到她衣袖叠高,露出小臂,双手上还带着水珠,应该是刚洗完手,脚上穿着一双黑色雨靴,鞋底扒了厚厚一层黄泥。“小赵,好几个月没见了!”危丽直接扑过去抱住赵离浓,蹭过去的脸被推开,也丝毫不在意,“我带了风干鸡肉,晚上一起吃!”旁边严静水根本没眼看下去:“别磨蹭了,我们去选实验室。”“我换双鞋。”赵离浓立刻转移话题,在实验大楼门口鞋柜换了鞋子才进去。严静水等在旁边,发了张清单给她:“我们这次过来,带了几样实验仪器,体积比较大,装在货运列车上,明天下午三点到。”赵离浓点开一看,全是他们现在缺的实验设备,她低头笑了笑,很高兴:“明天我让人去对接,搬到实验室。”严静水还带来了一些别的消息:“罗家虽然出了事,但经调查罗翻雪没有牵扯其中,所以她还留在中央研究院,身份不变。”不过,高级研究员通道打开,这次她没有升上去,后面只能靠自己再去争取,一直在申请基地外工作。实验室选好后,严静水和危丽也算彻底安定下来,以后的发展就在这边。危丽很快活,这里面积广,很适合她遛鸡,不像在中央基地,她时刻都得照顾其他人的心理承受能力。但很快,她收到了第九demo代码:
import jieba
import jieba.posseg as pseg
import paddle
import jieba.analyse
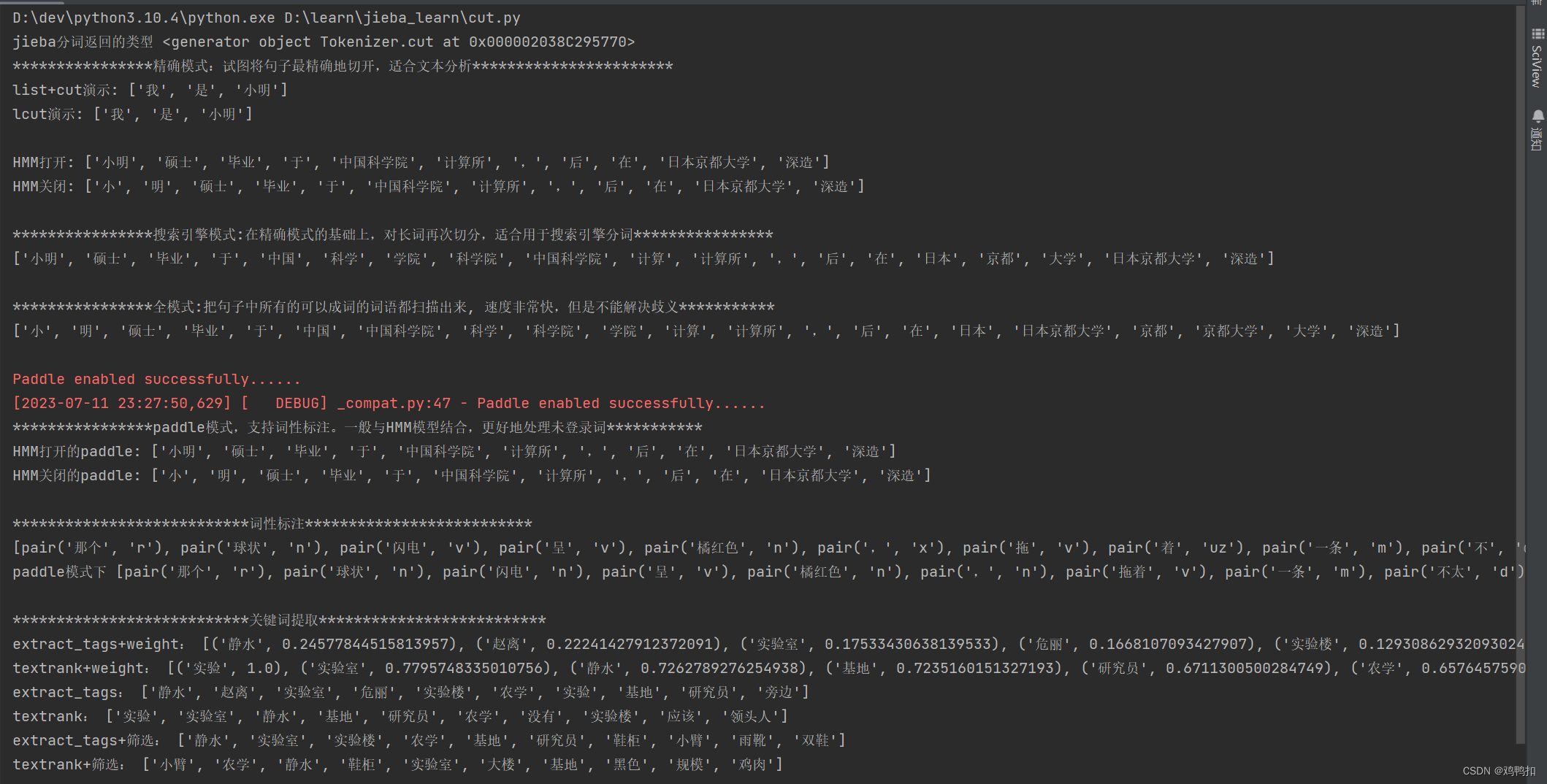
import logging # 用来关闭jieba在控制台中默认打印的很长一串提醒信息的paddle.enable_static()jieba.setLogLevel(logging.WARNING) # 用来关闭jieba在控制台中默认打印的很长一串提醒信息的print("jieba分词返回的类型", jieba.cut("我是小明"))print("****************精确模式:试图将句子最精确地切开,适合文本分析***********************")# jieba.lcut以及jieba.lcut_for_search直接返回list
# 而jieba.cut以及jieba.cut_for_search返回一个迭代器。
print("list+cut演示:", list(jieba.cut("我是小明")))
print("lcut演示:", jieba.lcut("我是小明"))
print()# HMM模型是用来处理未登录词的,直接lcut(s)是默认关闭HMM模型的。
print("HMM打开:", jieba.lcut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=True))
# print()print("HMM关闭:", jieba.lcut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=False))
print()print("****************搜索引擎模式:在精确模式的基础上,对长词再次切分,适合用于搜索引擎分词****************")
print(jieba.lcut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造"))
print()print("****************全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义***********")
print(jieba.lcut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", cut_all=True))
print()jieba.enable_paddle()
print("****************paddle模式,支持词性标注。一般与HMM模型结合,更好地处理未登录词***********")
print("HMM打开的paddle:", jieba.lcut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=True))
print("HMM关闭的paddle:", jieba.lcut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=False))
print()print("***************************词性标注**************************")
s = "那个球状闪电呈橘红色,拖着一条不太长的尾巴"
print(pseg.lcut(s))
print("paddle模式下", pseg.lcut(s, use_paddle=True))
print()print("***************************关键词提取**************************")
text = ''
with open('in.txt', 'r', encoding='utf-8') as inf:text = inf.read()
# extract_tags和textrank是两种提取关键词的算法
print("extract_tags+weight:", jieba.analyse.extract_tags(text, topK=10, withWeight=True))
print("textrank+weight:", jieba.analyse.textrank(text, topK=10, withWeight=True))
print("extract_tags:", jieba.analyse.extract_tags(text, topK=10))
print("textrank:", jieba.analyse.textrank(text, topK=10))
print("extract_tags+筛选:", jieba.analyse.extract_tags(text, topK=10, allowPOS=('n',)))
print("textrank+筛选:", jieba.analyse.textrank(text, topK=10, allowPOS=('n',)))
结果展示:
这篇关于中文分词工具jieba:代码之分词、词性标注、关键词提取与两个问题一个注意。问题一:安装jieba库成功但导入失败,问题二:paddle模式使用不了。注意:关闭paddle模式的控制台信息提示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








