本文主要是介绍总结 : 论文--Financial Distress Prediction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 数据获取与处理
- 实验方法与模型
- 论文写作技巧
- Word使用技巧
前言
本文对近期完成的一篇小论文做些总结,以后大论文估计也是基于此研究来进行改进,现对论文完成的整个经过包括实验部分以及论文写作等部分做出总结,以防忘却。论文题目为:《Adaboost ensemble with PSO-SVM for financial distress prediction》。主要思想是将粒子群算法(PSO)优化过的支持向量机(SVM)作为弱分类器,通过集成的方式,将弱分类器集合成强分类器从而提高预测分类精度。
数据获取与处理
本实验所使用的数据来自于CSMAR经济金融研究数据库。取上市公司的财务指标数据作为研究样本。
本实验利用python进行数据处理:
(1)导出Excel格式创建Matlab数据,即.xls格式的数据,然后直接用 pd.read_excel() 将数据读取出。在读.csv格式的数据时遇到一个Bug:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
这里的意思是read_csv以utf-8的编码格式不能正确读取数据,在用linux file 命令查看过数据文件的编码格式后,设置encoding='UTF-16’后就能正确读出数据来了。
(2)使用 pd.concat() 将经营受损(AB)和两年亏损(AD)的公司进行合并,从而得到标签数据集。
(3)python的pandas库中的 isin() 函数很好用,可以用来做各种判断。~ 符号通常可以和isin()搭配使用,可以起到反向选取的作用。详解参考:pandas.DataFrame.isin
(4)to_datetime() 函数能够将数据转换成时间日期。时间日期之间也是可以直接比较滴。详解参考:pandas.to_datetime
(5)保存文件时,可以通过变量转字符串的方式 str(i) 插入到文件名中,代码如下:
for i in range(2014,2019):st = st_target_1418[(st_target_1418['Annoudt'] >= pd.datetime(i,1,1)) & (st_target_1418['Annoudt'] <= pd.datetime(i,12,31))]st.to_csv('./data/ST/st_target_' + str(i) + '.csv', encoding='UTF-8-sig')
(6)可以用 dataframe.columns.values 或 dataframe.index.values 来获取dataframe的行索引名值和列名值。tolist( ) 可以将这些数据转换成列表。
(7)pd.merge() 函数可以让python实现数据库方式的数据合并,包括内、外连接等。详解参考:pandas.DataFrame.merge
(8)describe(include=‘all’) 可以对所有类型的数据进行描述。
(9)使用 lambda 表达式实现标签数据的0、1转换,代码如下:
data_2014['ST'] = data_2014.Stkcd.apply(lambda x: 1 if x in id_2014_st_ else 0)
(10)random.sample(sequence,k) 可以从指定序列中随机获取指定长度的片段。sample函数不会修改原有的序列。
(11)通过groupby函数,按照对应年份分组后求各列值的平均值,代码如下:
columns_data_2015 = data_2015.columns.values.tolist()[4:]
data_2015_new = data_2015.groupby('Stkcd')[columns_data_2015].mean()
(12)corr() 函数检查变量之间的相关性,本文采用Pearson相关系数法对变量之间的相关性做出检验。详解参考:corr
(13)np.percentile() 可以获取数列的百分比点的数。
实验方法与模型
1、数据降维
本实验首先使用主成分分析法(PCA)对数据进行降维处理。相关代码如下:
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X_data, y_data, random_state=123)
pca = PCA(n_components=0.9, whiten=True).fit(X_train)# 使用pca的transform方法获得降维之后的数据
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
2、模型方法
(1)调用sklearn中的SVM模型,time可以用来计算代码块运行的时间,代码如下:
from sklearn.svm import SVC
from time import timet0 = time()
svm_clf = SVC(kernel='rbf') # 训练SVM分类器的时候,可以通过网格调参搜索后得到最优拟合器。
svm_clf.fit(X_train_pca, y_train)
print("done in %0.3fs" % (time()-t0))
(2)粒子群优化算法优化SVM的参数c和g,再将优化过的参数重新构建SVM模型,其中PSO算法参考github:https://github.com/shiluqiang/PSO_python/blob/master/PSO_RBF_SVM.py。
(3)Adaboost-SVM模型:条用sklearn.ensemble模块中的AdaboostClassifier方法,通过调整方法中的超参数base_estimator为指定的svc,svc需要设置probability=True才可被adaboost接受,即可构建adaboost-svm算法模型,参考:adaboost with svm。构建的代码如下所示:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV# 接下来我用网格调参来选择adaboost的两个参数,n_estimators和learning_ratesvc=svm.SVC(kernel='rbf', C=6.7143, gamma=0.0152, probability=True)
adaboost_with_svc = AdaBoostClassifier(n_estimators=15, base_estimator=svc, learning_rate=0.5)Ada_Grid = {'n_estimators': [5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,150,200,300,400,500],'learning_rate': [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]}estimator = adaboost_with_svcAdaboost_with_grid_search = GridSearchCV(estimator, Ada_Grid).fit(X_train_pca, y_train)
print(Adaboost_with_grid_search.best_params_)
print(Adaboost_with_grid_search.best_score_)
(4)模型的评价方法:包括roc曲线、auc值、精确度、分类报告、混淆矩阵。这些方法都集成在sklearn.metrics中,导入方法如下:
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
论文写作技巧
1、参考文献的格式转化
为了符合IEEE参考文献的输入格式,本文编写时使用在线格式转化工具对所用参考文献进行符合EI格式的转化。
Word使用技巧
论文使用Word 2016 for mac编写,期间各种格式问题困扰的不要不要的,在此记录一些使用的技巧。
1、行间距再次缩小
word2016 for mac即使设置了1.25倍行距,看起来依然行间距较大,那是因为它默认的每页显示的行数只有33行,这样自然导致了行距过大,通过设置:格式-文档-文档网格-行数 可进行调整,每页多加几行就可以缩小行距了。
2、word中纸张的设置
布局-大小-纸张选择。
3、word中分栏的设置
选中需要分栏的内容,然后布局-分栏。
4、word表格的设置
选中表格-布局-自动调整,可设置根据内容/窗口自动调整表格。
选中表格-段落-缩进和间距-行距设置为固定值*磅可以将表格内的行间距进行缩小。
5、word内容不垮
对所写内容选择对齐文本,可以使得文字内容左右对齐。配合在段落-中文版式-不勾选允许西文在单词中间换行,可以保证每行的内容不夸。
6、word中插入LaTeX公式
参考:word插入LaTeX公式。使用Mathpix Snipping tool工具对公式进行截图,就能转换成LaTeX公式,copy后在mac自带的Pages插入-方程-粘贴LaTeX公式,就能转变成可编辑的公式,再复制公式到word中。
7、word中公式对齐
可插入一个一行三列的表格,左右各占15%(通过右击-表格属性-列-指定宽度为15%,度量单位百分比),中间列插入公式居中对齐,右边列插入编号右对齐。
8、word中输入希腊字母
使用百度输入法自带的数学符号键盘进行输入。
9、参考文献的格式
(1)把准备好的参考文献粘贴到记事本中,在标号和正文之间添加一个制表符/tab键
如下图所示:

(2)把第一步处理好的参考文献粘贴到word中进行如下设置:
开始=》段落=》常规=》对齐方式:两端对齐;
缩进=》特殊格式:悬挂缩进为2个字符
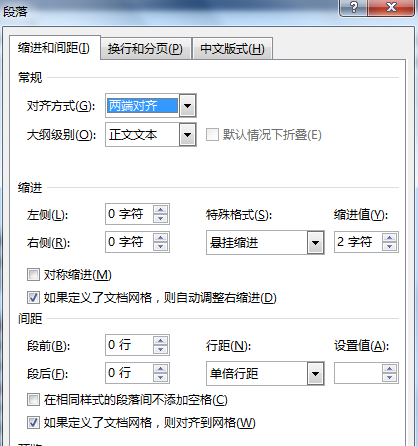
(3)调整后的参考文件就完美对齐了,如下图所示:

这篇关于总结 : 论文--Financial Distress Prediction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






