本文主要是介绍【二】AI Studio 项目详解【VisualDL工具、(二)环境使用说明、(二)脚本任务、图形化任务、在线部署及预测】PARL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关文章
【一】-环境配置+python入门教学
【二】-Parl基础命令
【三】-Notebook、&pdb、ipdb 调试
【四】-强化学习入门简介
【五】-Sarsa&Qlearing详细讲解
【六】-DQN
【七】-Policy Gradient
【八】-DDPG
【九】-四轴飞行器仿真
飞桨PARL_2.0&1.8.5(遇到bug调试修正)
一、AI Studio 项目详解【VisualDL工具】
二、AI Studio 项目详解【环境使用说明、脚本任务】
三、AI Studio 项目详解【分布式训练-单机多机】
四、AI Studio 项目详解【图形化任务】
五、AI Studio 项目详解【在线部署及预测】
1.AI Studio 项目详解【环境使用说明/脚本任务】
编辑区 Code Cell
Code Cell是Notebook的代码编写单元。用户在Code Cell内编写代码(支持Python2、Python3)和shell命令,代码/命令在云端执行,并返回结果到Code Cell.
命令/编辑模式
绿色代表块内容可编辑状态-编辑模式(比如输入代码),蓝色代表块可操作状态-命令模式(比如删除Cell,必须回到蓝色),与linux编辑器vi/vim类似,编辑模式和命令模式之间可以用Esc和Enter来切换。
Linux命令
运行Linux命令的方式是在Linux命令前加一个!,就可以在块里运行
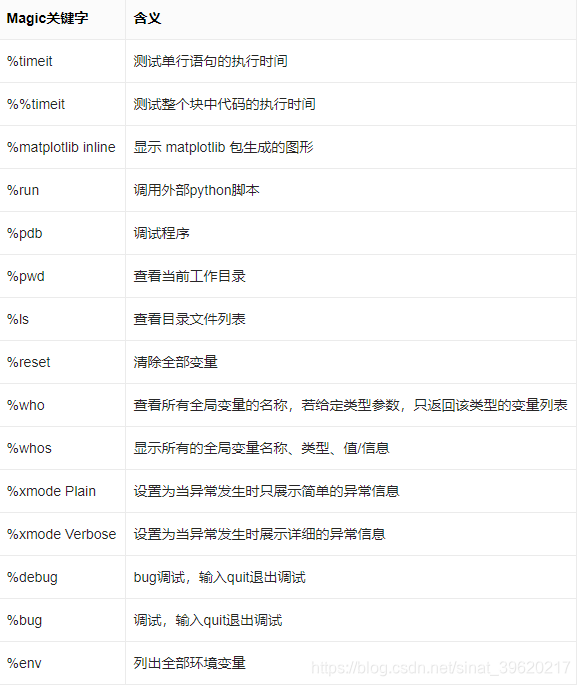
! pip xxxxMagic关键字
Magic关键字是可以运行特殊的命令. Magic 命令的前面带有一个或两个百分号(% 或 %%), 分别代表行Magic命令和Cell Magic命令. 行Magic命令仅应用于编写Magic命令时所在的行, 而Cell Magic命令应用于整个Cell.
侧边栏---文件夹
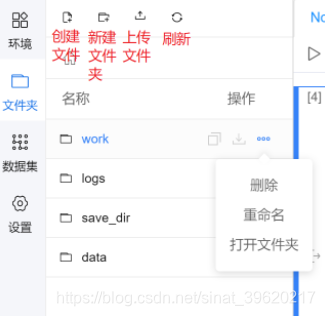
按照树形结构展示/home/aistudio路径下的文件夹和文件。可以在该目录下进行如下操作:
- 文件夹操作: 创建新的文件夹. 鼠标悬浮在文件夹条目上, 会出现操作按钮, 包括删除文件夹、重命名文件夹、路径复制.
- 文件操作: 创建上传文件(上传的单个文件最大 150 MB). 鼠标悬浮在文件条目上, 会出现操作按钮, 包括下载文件、重命名文件、路径复制.
- 更新操作:如果在代码运行过程中磁盘里的文件更新了,可以手动刷新, 在侧边栏查看文件更新的状态.
- 注意:
/home/aistudio/data是非持久化目录,请不要将您的文件放到该目录下,重启后,文件将会丢失.
版本管理--用于保存项目空间中的重要文件, 以及恢复.--用户最多可以生成5个版本, 并制定不同的版本名称.
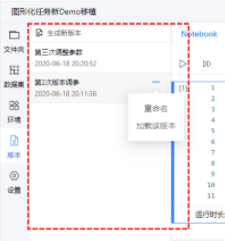
注意: 加载版本时, 执行的是全量覆盖操作, 即先清空该项目空间中全部内容, 然后把版本内容复制进去. 如果您当前项目环境中存在A文件, 但历史版本中不含有A文件, 则加载后A文件会消失.
后台任务
由于Notebook有高级版(GPU)环境每周运行总时长限制(70小时/周), 以及Notebook离线运行时长最多2小时, 如果需要突破这两种限制, 可以使用Notebook中的后台任务.
后台任务基于一个版本, 可以将全部版本内容提交至后台的GPU服务器上进行运行, 然后可以将运行后的结果全量返回并再次导入Notebook环境中的一种机制.
后台任务不依赖当前Notebook的硬件环境, 因此无论在普通版(CPU)环境, 还是在高级版(GPU)环境中, 均可以创建并提交.
后台任务运行于后台GPU单卡服务器上, 因此从运行开始即消耗GPU算力卡时长. 同样, 提交该任务需要用户算力卡余额>0.
当任务完成后, 用户可以将任务生成结果导入Notebook空间中, 其中, 如Notebook文件的Code Cell执行后, 返回结果将直接写入Notebook Code Cell下方的输出区.
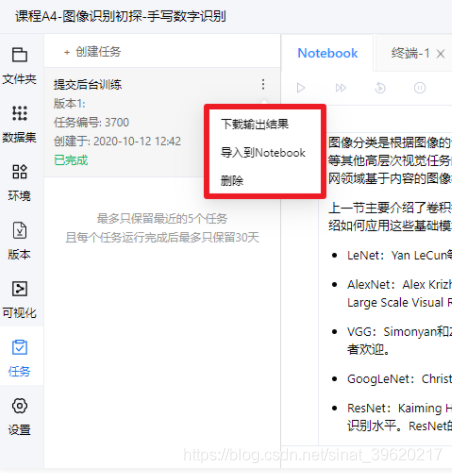
任务根据其状态, 可以将结果导入Notebook环境中, 或下载到用户本地电脑. 任务可以删除. 同时, 在项目预览页面中, 用户也可以管理已经提交任务, 进行中止, 删除, 或下载运行后的结果.
Limit: 每个任务最大运行时长72小时(不含排队时间). 每个任务最大输出结果20GB. 超过会导致任务失败.
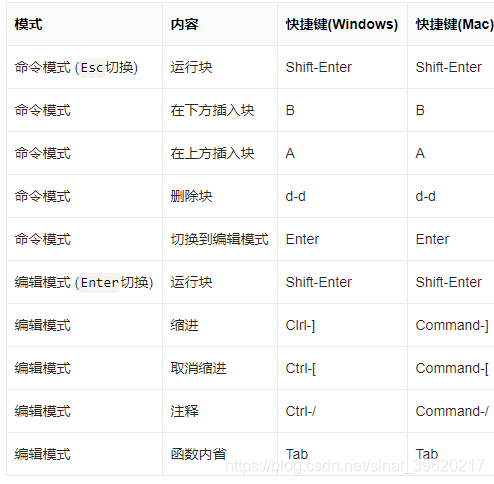
快捷键操作
2.脚本任务
脚本任务项目的任务执行由GPU集群作为支撑, 具有实时高速的并行计算和浮点计算能力, 有效解放深度学习训练中的计算压力, 提高处理效率.用户可以先在Notebook项目中, 利用在线的Notebook功能, 完成代码的编写与调试, 之后在脚本任务项目中运行, 从而提高模型训练速度.
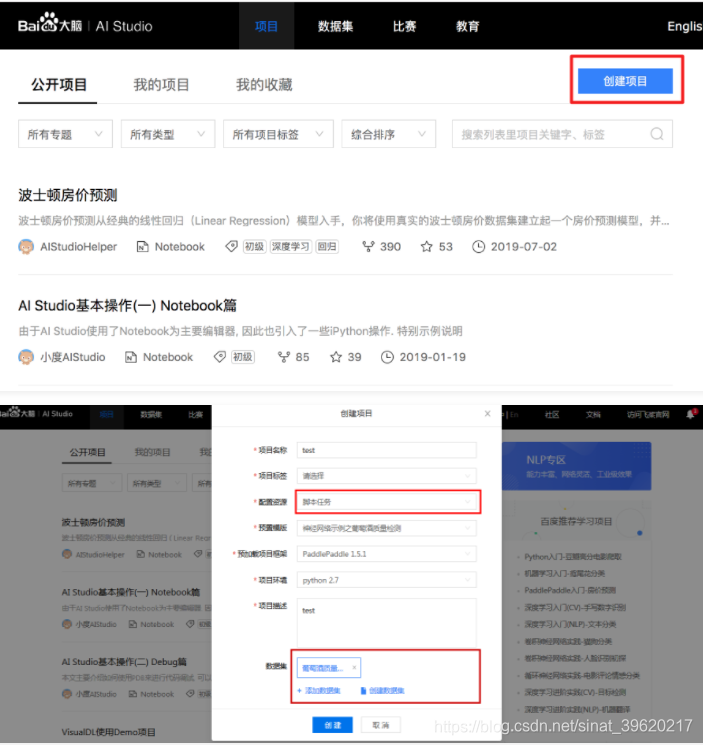
在脚本任务项目详情页中, 用户可以浏览自己创建的项目内容, 编辑项目名称及数据集等信息, 查看集群历史任务信息等
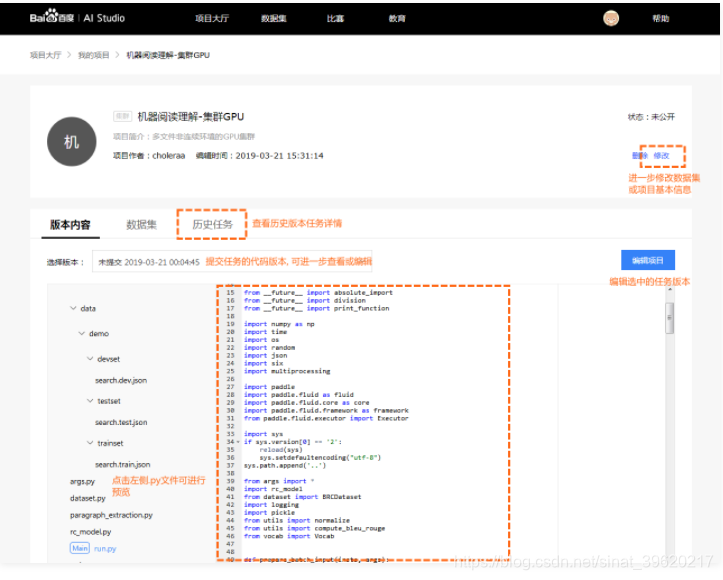
- 版本内容: 默认展示当前Notebook最新内容. 初始化状态为脚本任务项目示例代码. 用户可以手动选择提交任务时对应的历史版本.
- 数据集: 项目所引用的数据集信息.
- 历史任务: 每一次执行任务的记录.
代码编辑:
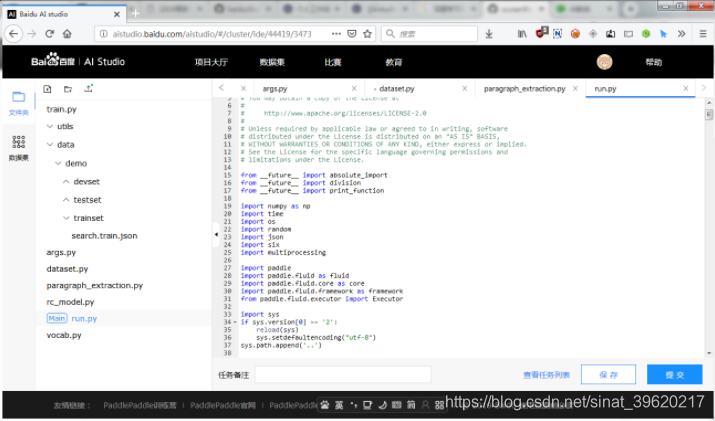
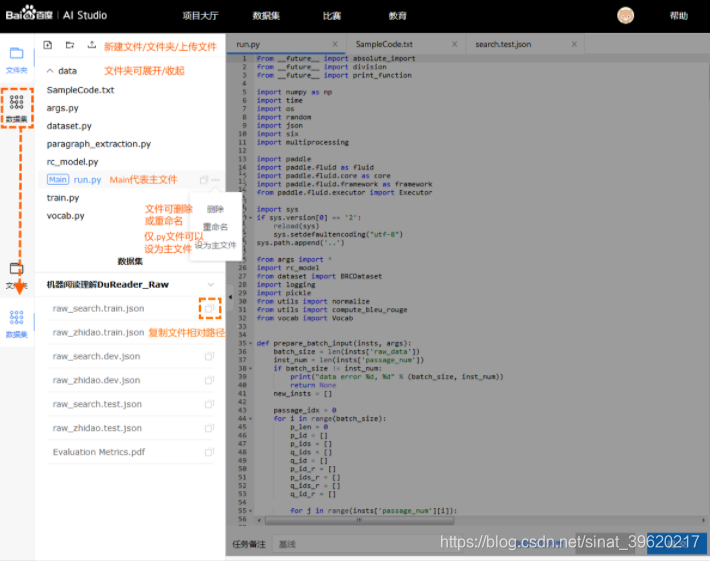
左侧文件管理和数据集
文件管理
- 用户可以手动创建文件/文件夹, 对文件/文件夹进行重命名或删除.
- 其中用户可以选择指定文件, 并设置为主文件. 用作整个项目运行的入口.
- 用户也可以手动上传文件(体积上限为20MB, 体积巨大的文件请通过数据集上传).
- 用户可以双击文件, 在右侧将新建一个tab. 用户可以进一步查看或编辑该文件的内容. (目前仅支持.py文件和.txt文件; 同时预览文件的体积上限为1MB)
数据集管理
- 用户可以查看数据集文件, 并复制该文件的相对路径. 最后拼合模板内置绝对路径, 即可使用. 下方有详细介绍.
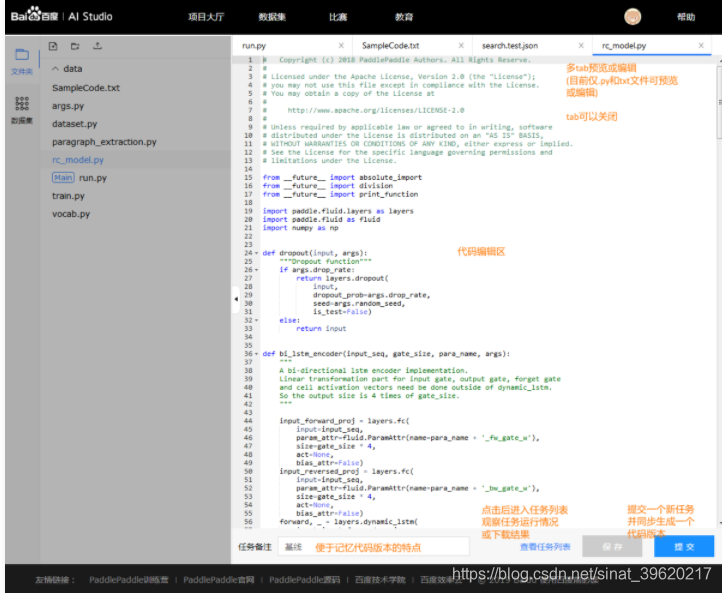
右侧文件预览编辑和提交任务
- 当多个文件被打开时, 用户可以将它们逐一关闭, 当至最后一个文件时即不可关闭
- 选中文件对应的tab即可对文件内容进行预览和编辑, 但当前仅支持.py和.txt格式的文件
- 点击保存按钮, 会将所有文件的改动信息全部保存, 如用户不提交任务, 直接退出, 则自动保存为一个"未提交"版本
- 提交任务前, 建议写一个备注名称, 方便未来进行不同版本代码/参数的效果比较
*2.1 PaddlePaddle脚本任务训练说明
PaddlePaddle基于集群的分布式训练任务与单机训练任务调用方法不同。基于pserver-trainer架构的的分布式训练任务分为两种角色: parameter server(pserver)和trainer.
在Fluid 中, 用户只需配置单机训练所需要的网络配置, DistributeTranspiler模块会自动地根据 当前训练节点的角色将用户配置的单机网路配置改写成pserver和trainer需要运行的网络配置:
t = fluid.DistributeTranspiler()
t.transpile(trainer_id = trainer_id,pservers = pserver_endpoints,trainers = trainers)
if PADDLE_TRAINING_ROLE == "TRAINER":# 获取pserver程序并执行它trainer_prog = t.get_trainer_program()...elif PADDLE_TRAINER_ROLE == "PSERVER":# 获取trainer程序并执行它pserver_prog = t.get_pserver_program(current_endpoint)...- 目前脚本任务项目中提供的默认环境
PADDLE_TRAINERS=1(PADDLE_TRAINERS是分布式训练任务中 trainer 节点的数量) - 非PaddlePaddle代码请放到
if PADDLE_TRAINING_ROLE == "TRAINER":分支下执行, 例如数据集解压任务
链接:单机多机训练:https://www.paddlepaddle.org.cn/documentation/docs/zh/1.6/user_guides/howto/training/cluster_quick_start.html。
数据集与输出文件路径说明
- 脚本任务项目中添加的数据集统一放到绝对路径
./datasets
# 数据集文件会被自动拷贝到./datasets目录下
CLUSTER_DATASET_DIR = '/root/paddlejob/workspace/train_data/datasets/'- 脚本任务项目数据集文件路径的获取
在页面左侧数据集中点击复制数据集文件路径, 得到文件的相对路径, 例如点击后复制到剪切板的路径为data65/train-labels-idx1-ubyte.gz.
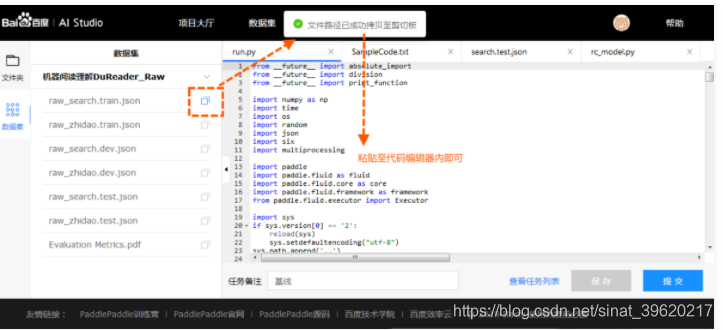
# 数据集文件相对路径
file_path = 'data65/train-labels-idx1-ubyte.gz'真正使用的时候需要将两者拼合 train_datasets = datasets_prefix + file_path
- 脚本任务项目输出文件路径为
./output
# 需要下载的文件可以输出到'/root/paddlejob/workspace/output'目录
CLUSTER_OUTPUT_DIR = '/root/paddlejob/workspace/output'提交任务
点击【运行项目】后进入到任务编辑页面.
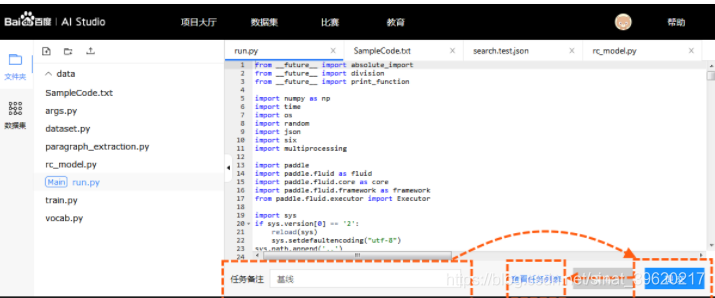
- 提交: 点击提交会发起本次本次任务的执行. 并将代码自动保存为一个版本.
- 任务备注: 任务自定义标识, 用于区分项目内每次执行的任务.
历史任务
历史任务页面如下所示.
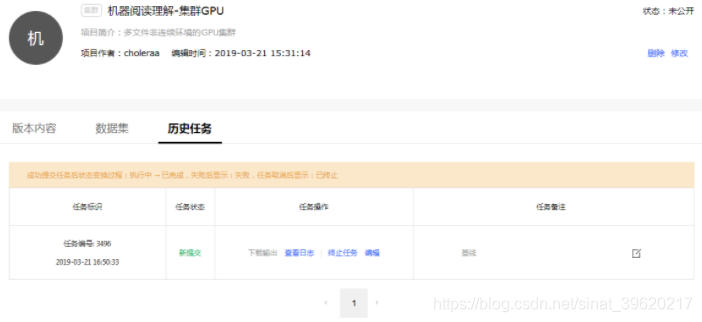
任务操作:
- 下载输出: 下载任务输出文件, 文件格式
xxx(任务编号)_output.tar.gz. - 查看/下载日志: 在任务运行过程中, 点击"查看日志", 可以查看实时日志, 掌握运行进度. 运行结束后, 按钮转为"下载日志". 下载任务执行日志, 日志格式
xxx(任务编号)_log.tar.gz. - 终止任务: 在任务执行过程中, 可以点击终止任务.
- 编辑: 编辑任务对应的代码版本内容.
这篇关于【二】AI Studio 项目详解【VisualDL工具、(二)环境使用说明、(二)脚本任务、图形化任务、在线部署及预测】PARL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





