本文主要是介绍BDTC2023:CloudberryDB开源创新与实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中国大数据技术大会(BDTC)由中国计算机学会(CCF)创立于2008年,已经成为国内外极具行业实践的专业大数据交流平台。12月22日-24日,第十七届中国大数据技术大会(BDTC 2023)在广州举行。酷克数据(HashData)研发副总裁杨瑜受邀在“开源数据库”分论坛发表主题演讲,从产业实践和技术发展趋势的角度,介绍了HashData开源的数据库产品Cloudberry Database(简称“CBDB”或“CloudberryDB”)。
CloudberryDB是酷克数据面向分析和AI场景打造的下一代统一型开源数据库,搭载了PostgreSQL 14.4 内核,兼容PostgreSQL和Greenplum生态,采用 Apache License 2.0许可协议。
CloudberryDB支持丰富的数据类型和数仓/AI混合负载,可开展SQL分析、机器学习、全文检索、HTAP等任务,通过数据存储加密、联合⾝份验证等技术手段,帮助企业更方便地自建高效稳定的数据底座。

应需而生 助力企业灵活应对数据新挑战
成立于2016年的酷克数据,是国内最早专注于云原生数仓研发推广的软件企业,公司旗舰产品HashData Enterprise目前已广泛应用于金融、电信运营商、政务、能源、互联网等行业头部客户,其中最大客户规模已超过30000个节点。
在服务众多头部客户的过程中,酷克数据团队发现,企业部署运行的开源项目,存在版本进展缓慢、特性更新不及时、技术支持有限等痛点。凭借对MPP数据库的深度理解、国内大客户的服务实践经验,以及创始团队长期的开源社区参与经历,我们研发并开源了CloudberryDB数仓产品。
CloudberryDB既能满足单机本地快捷部署,也能通过插件自由扩展为云原生架构,具备高弹性、高并发、湖仓一体化、扩缩容灵活等优势。SQL引擎基于并行处理(MPP)架构,支持多计算集群部署,具备强大的并行计算能力,可以轻松支持高并发,有效隔离混合工作负载。
在部署方式上,CloudberryDB采用100%纯软方案,支持裸金属、虚拟机、容器化等多种部署方式,企业开发人员可以使用R、Python、Perl、Java、 pgsql等语言编写用户自定义函数(UDF),面向多计算集群部署,实现专属的业务需求。我们希望通过足够灵活的产品架构与方案,来覆盖不同数据量与场景的多元需求。
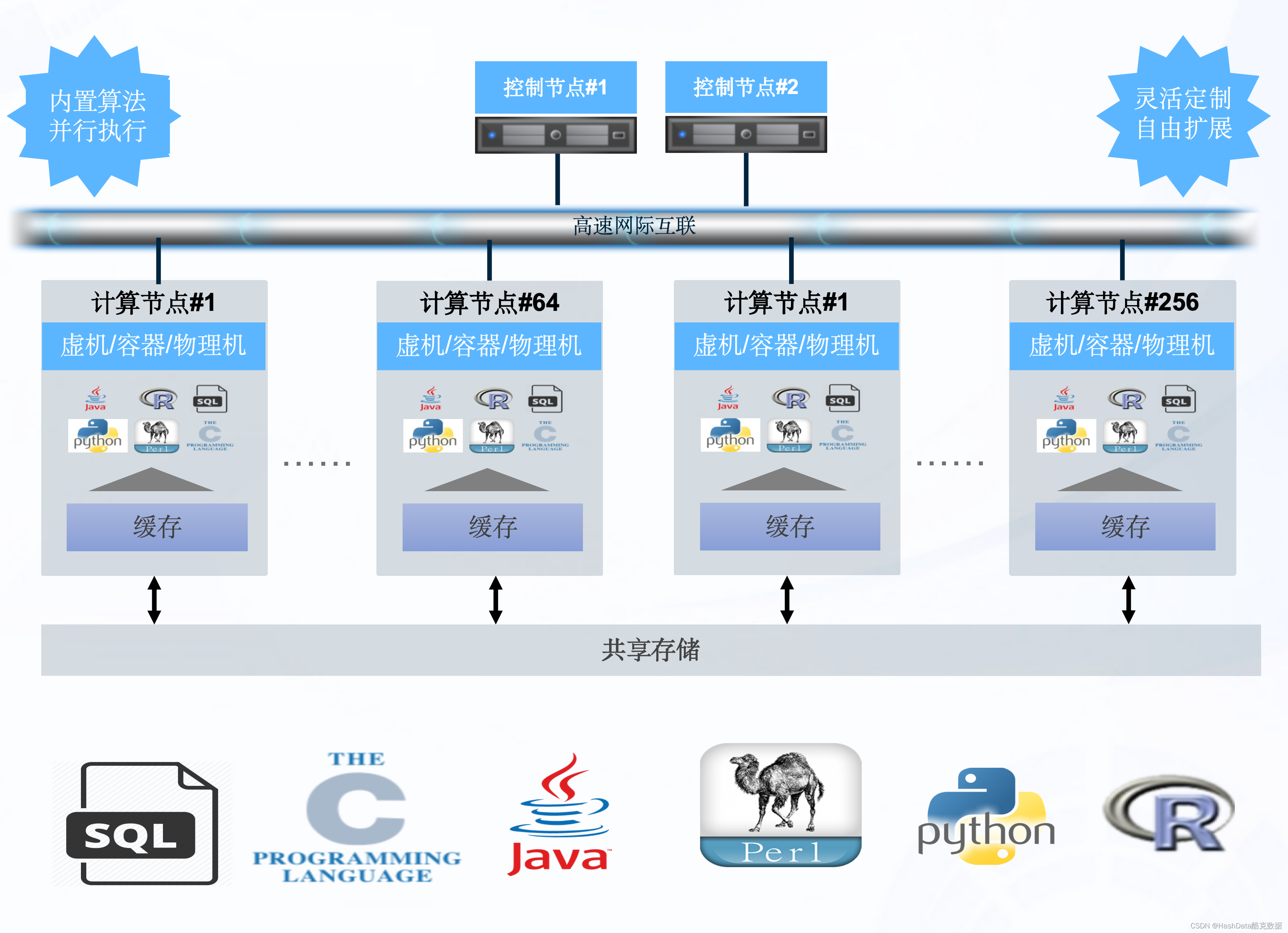
图1:CloudberryDB灵活部署形态
高效易用 让数据更好用起来
CloudberryDB全面集成PstgresQL 14.4,支持ANSI SQL 2011,内置丰富的库内分析模块,具备强大的SQL分析功能,满足企业进行海量数据的复杂分析需求:
- 支持Multi-range 、JSON、JSONB、XML等多种类型,并提供了相关操作、函数支持;
-
支持UPSERT,增加INSERT ... ON CONFLICT语法,在发生约束冲突时可以转换成UPDATE语义,对于数据导入友好;
- 增加新语法方便数据更新:UPDATE tab SET (col1, col2, ...) = (SELECT col1, col2, ...);
-
支持范围、列表、哈希等类型的分区,支持多层分区嵌套,支持分区管理操作;
- 支持BTree、Bitmap、Hash、GIN、 BRIN、GiST 等多种类型的索引;
- 支持物化视图,支持复杂查询,如:CTE、递归查询;
- postgres_fdw支持聚集下推, 减少传输数据量;
- 允许窗口函数执行增量排序;
- 支持 just-in-time (JIT) 编译;
- 支持创建覆盖索引;
随着大数据场景的深入,地理空间数据成为了重要的数据源。CloudberryDB通过引入PostGIS 2.X插件,进行了企业级的优化改进,实现了对空间数据类型、空间索引和空间函数的支持。
针对当前企业日益增长的实时分析需求,CloudberryDB研发了UnionStore新型存储引擎,通过将Redo日志持久化处理与replay操作来获取数据以提供外部访问,在保持顶层同一套引擎、底层同一套存储与数据的一致性设计的情况下,实现了近事务级的计算与查询实时性。
在CBO优化器方面,CloudberryDB重新打磨了基于代价的查询优化器,使得无论在云环境还是混合负载环境,都能生成更加智能和高效的查询计划。
基于CBO优化器,CloudberryDB支持基于代价模型的聚集下推能力,能够有效减少Join运算的数据量,大幅提升性能。同时利用runtime filter技术,可以在Join运算时利用小表协同过滤大表数据,带来Join运算的进一步提速。
此外,CloudberryDB自主研发了新型行列混存技术,在保证写入效率的情况下,利用查询时跳块过滤和预计算,大幅提升查询性能。CloudberryDB还利用向量化对算子进行了针对性的细致优化,带来了数量级的效率提升收益。
多重保护 让数据安全有保障
为确保企业数据的安全,CloudberryDB采用了统一认证、按需授权、安全存储、动态脱敏等方式,构建了多层级安全体系。企业可以根据自身需求,对数据库、模型、表文件进行加密认证:
- 多种加密:支持MD5、SHA-256、Kerberos authentication多种加密算法;
- 按需授权:针对不同的用户,在不同级别的对象(如:Schema、表、列、视图、函数等)上进行多种类型的权限设定;
- 存储加密:底层存储支持数据加密组件 pgcrypto,实现敏感数据函数加密,支持数据库透明加密(TDE);
- 动态脱敏:对于开发、测试、沙箱等场景,在实现数据高效共享的同时,保证敏感信息的安全防护,支持随机、SHA、自定义函数等多种脱敏算法,实现动态脱敏。
效果导向 让分析与智能更易用
在生态方面,CloudberryDB完美兼容第三方产品,与主流BI工具、挖掘预测工具、ETL工具、J2EE/.NET应用程序以及其他数据源/计算引擎均有良好连通。

图2:CloudberryDB产品兼容生态
大语言模型的兴起带动企业对AI技术的应用需求与日俱增。CloudberryDB内置了分布式并行向量数据存储、索引及检索功能,企业可以通过酷克数据自研的AI开发工具箱HashML,将本地的文本、图像等非结构化数据转化成向量表示,构建分布式大规模多模态向量知识库,让AI应用开发变得更加简单便捷。

图3:基于HashData构建分布式大规模多模态向量知识库
未来,CloudberryDB将以国际标准、高点定位、全球眼光的运营理念,构建开放、友好、中立的开源社区。
这篇关于BDTC2023:CloudberryDB开源创新与实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






