本文主要是介绍单链表整表创建的两种方法(头插法和尾插法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
线性表可分为顺序存储结构和链式存储结构
顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。而单链表和顺序存储结构就不一样,它的每个数据的存储位置不需要像数组那样集中,它可以很散,是一种动态结构。对于每个链表来说,它所占用的空间大小和位置并不需要预先分配划定,可以根据系统的情况和实际的需求即时生成。所以,创建单链表的过程就是一个动态生成链表的过程。即从“空表”的初始状态起,一次建立各元素结点,并逐个插入链表。
单链表的整表创建
单链表的整表创建主要有两种方法,即头插法和尾插法,下面分别对这两种方法进行介绍
头插法创建单链表(含有头结点)
头插法创建单链表的步骤:
1. 声明一指针变量p和计数器n;
2. 初始化一空链表L;
3. 让L的头结点的指针指向NULL,即建立一个带头结点的单链表;
4. 循环:
- 生成一新结点赋值给p;
- 随机生成一个数字赋值给p的数据域;
- 将p插入到头结点与前一新结点之间。
头插法实现的代码如下:
#include<stdio.h>
#include<malloc.h>
#include<time.h>
#include<stdlib.h>struct node //建立结构体{int data; //elementype表示一种数据类型,可能是int/char等等struct node *next; //next 指针,用于链表结构指向下一个节点};typedef struct node node; //重定义struct node类型为nodenode* Creat(int Count) //创建链表{node *p,*head;int n;srand(time(NULL)); //生成种子head = (node*)malloc(sizeof(node));head->data = Count;head->next = NULL; //头结点储存链表长度for (n = 0;n < Count;n++){p = (node*)malloc(sizeof(node));p->data = rand()%1000;p->next = head->next; //头插法单链表创建的关键两行代码head->next = p; }return(head);}void List(node* head) //打印链表{node *p1;p1 = head;while(p1!= NULL){printf("%4d",p1->data);p1 = p1->next;}}int main() //主函数{node* head;int Num;printf("Enter the number of linked list nodes:\n");scanf("%d",&Num);head = Creat(Num);printf("\n");printf("List:\n");List(head);printf("\n");}这段算法代码中,我们其实用的是插队的办法,就是始终让新结点在第一的位置。如下图所示:
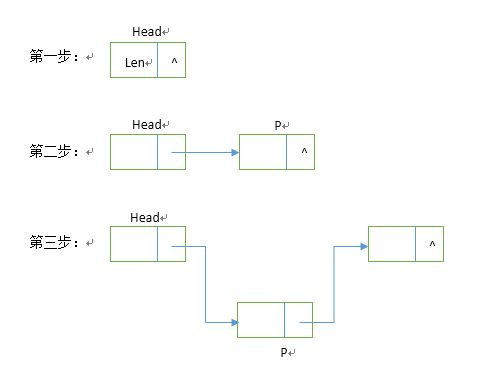
每一个新结点都插在头结点之后的位置,所谓插入,实际上就是为新建立的结点解决两个问题:它指向谁和谁指向它,在代码中分别由
p->next = head->next; //新结点指向原来头结点的后面一个结点
head->next = p; //头结点指向新结点这两句代码解决了这两个问题,那么链表的建立也就完成了。由于始终让新结点处在第一的位置,所以这种方法称为头插法。
头插法创建单链表结果展示:
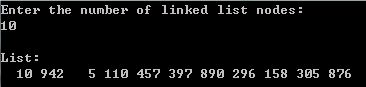
这种方法虽然实现了链表的创建,由于是头插,所以链表的顺序是逆序的,下面介绍的尾插法创建的链表的顺序是正序的。
尾插法创建单链表
#include<stdio.h>
#include<malloc.h>
#include<time.h>
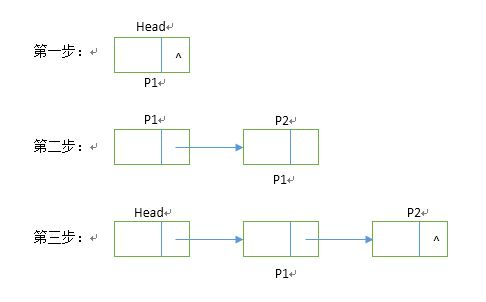
#include<stdlib.h>struct node //创建结构体{int data; //elementype表示一种数据类型,可能是int/char等等struct node *next; //next 指针,用于链表结构指向下一个节点};typedef struct node node; //重定义struct node类型为nodenode* Creat(int Count) //创建链表{node *p1,*p2,*head;int n;srand(time(NULL));//生成种子head = p1 = (node*)malloc(sizeof(node)); //p1为指向表尾结点的指针head->data = rand()%1000; head->next = NULL;for (n = 1;n < Count;n++){p2 = (node*)malloc(sizeof(node)); //p2为新申请的结点p2->data = rand()%1000; p1->next = p2; //将表尾结点的指针指向新结点p1 = p2; //将当前的新结点定义为表尾终端节点}p1->next = NULL; //循环结束后最终的尾结点的指针赋值为NULLreturn(head);}void List(node* head) //打印链表{node *p1;p1 = head;while(p1!= NULL){printf("%4d",p1->data);p1 = p1->next;}}int main() //主函数{node* head;int Num;printf("Enter the number of linked list nodes:\n");scanf("%d",&Num);head = Creat(Num);printf("\n");printf("List:\n");List(head);printf("\n");}在这个算法中,每次新申请的结点都插入到了表尾,所以称为尾插法,注意理解p1=p2这一句代码,它的作用是:只要新结点插入进去了,那么他就会变成尾部结点。然后不断重复这个操作。流程如下:
尾插法创建单链表结果展示:
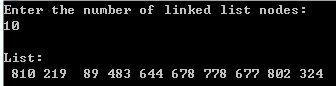
显然尾插法创建的链表是正序的
这篇关于单链表整表创建的两种方法(头插法和尾插法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


