本文主要是介绍强化学习_06_pytorch-TD3实践(CarRacing-v2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0、TD3算法原理简介
详见笔者前一篇实践强化学习_06_pytorch-TD3实践(BipedalWalkerHardcore-v3)
1、CarRacing环境观察及调整
| Action Space | Box([-1. 0. 0.], 1.0, (3,), float32) |
| Observation Space | Box(0, 255, (96, 96, 3), uint8) |
动作空间是[-1~1, 0~1, 0~1], 状态空间是 96 × 96 × 3 96\times96\times3 96×96×3 的图片。
1.1 图片裁剪及跳帧
环境初始的时候有40-50帧是没有意义的,可能还会影响模型训练。同时图片下面黑色部分也是没有太多意义,所以可以直接对图片截取s = s[:84, 6:90]
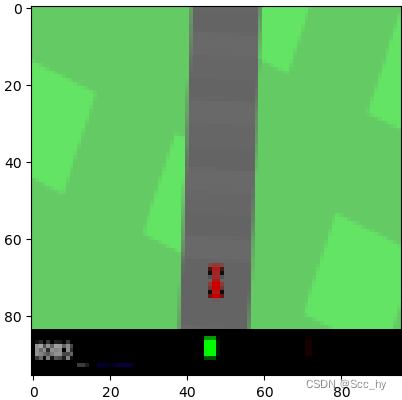
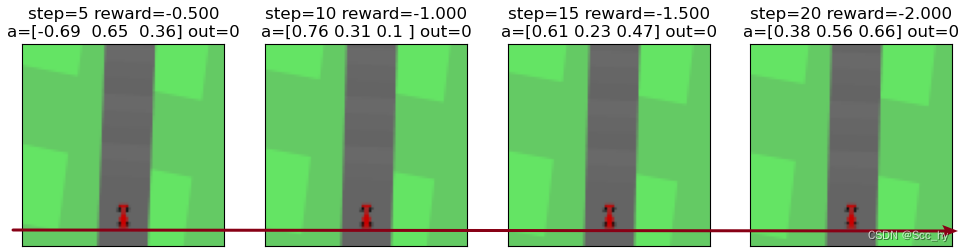
对环境进行简单观察会发现,一个step是一帧,一帧很难捕捉动作产生的影响(移动量,奖励等)。所以我们进行跳帧观察(1个action进行n个step,期间累计奖励),从红线看,每隔5帧已经可以看出小车在移动。
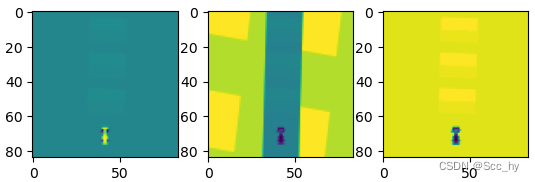
1.2 车驶离赛道判断 & reward调整
我们可以看出在gymnasium的CarRacing-V2连续的环境中没有驶出赛道终止的设定,所以我们可以基于像素进行判断是否驶离赛道。观察三个channel,我们可以看出在第二个channel中可以基于大约75行左右的一行像素进行是否行驶出去的判断。
经过试验我们可以直接用s[75, 35:50, 1] 前2个和后2个像素点来判断是否行驶到赛道外。
def judge_out_of_route(self, obs):s = obs[:84, 6:90, :]out_sum = (s[75, 35:48, 1][:2] > 200).sum() + (s[75, 35:48, 1][-2:] > 200).sum()return out_sum == 4
在加入了是否行驶到赛道外的判断后,如果判断出了赛道则reward=-10
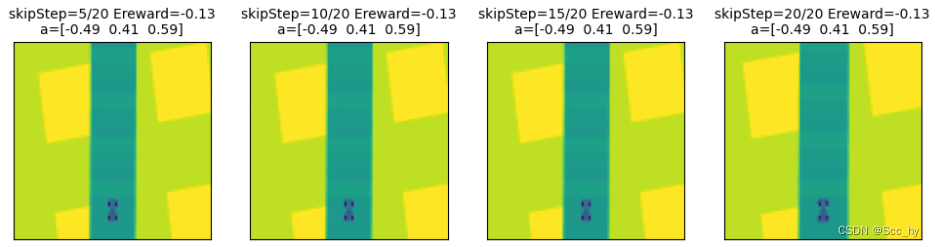
1.4 对多个输出进行通道叠加FrameStack
进行跳帧可以看出车辆的移动,但是只有多张的连续输入,CNN才能感知连续的动作。所以我们这两将4次跳帧组成一个observe,即最终20个step返回一个observe和叠加reward
1.5 最终环境构建python code
import gymnasium as gym
import torch
import numpy as np
from torchvision import transforms
from gymnasium.spaces import Box
from gymnasium.wrappers import FrameStackclass CarV2SkipFrame(gym.Wrapper):def __init__(self, env, skip: int):"""skip frameArgs:env (_type_): _description_skip (int): skip frames"""super().__init__(env)self._skip = skipdef step(self, action):tt_reward_list = []done = Falsetotal_reward = 0for i in range(self._skip):obs, reward, done, info, _ = self.env.step(action)out_done = self.judge_out_of_route(obs)done_f = done or out_donereward = -10 if out_done else reward# reward = -100 if out_done else reward# reward = reward * 10 if reward > 0 else rewardtotal_reward += rewardtt_reward_list.append(reward)if done_f:breakreturn obs[:84, 6:90, :], total_reward, done_f, info, _def judge_out_of_route(self, obs):s = obs[:84, 6:90, :]out_sum = (s[75, 35:48, 1][:2] > 200).sum() + (s[75, 35:48, 1][-2:] > 200).sum()return out_sum == 4def reset(self, seed=0, options=None):s, info = self.env.reset(seed=seed, options=options)# steering gas breakinga = np.array([0.0, 0.0, 0.0])for i in range(45):obs, reward, done, info, _ = self.env.step(a)return obs[:84, 6:90, :], infoclass SkipFrame(gym.Wrapper):def __init__(self, env, skip: int):"""skip frameArgs:env (_type_): _description_skip (int): skip frames"""super().__init__(env)self._skip = skipdef step(self, action):total_reward = 0.0done = Falsefor _ in range(self._skip):obs, reward, done, info, _ = self.env.step(action)total_reward += rewardif done:breakreturn obs, total_reward, done, info, _class GrayScaleObservation(gym.ObservationWrapper):def __init__(self, env):"""RGP -> Gray(high, width, channel) -> (1, high, width) """super().__init__(env)self.observation_space = Box(low=0, high=255, shape=self.observation_space.shape[:2], dtype=np.uint8)def observation(self, observation):tf = transforms.Grayscale()# channel firstreturn tf(torch.tensor(np.transpose(observation, (2, 0, 1)).copy(), dtype=torch.float))class ResizeObservation(gym.ObservationWrapper):def __init__(self, env, shape: int):"""reshape observeArgs:env (_type_): _description_shape (int): reshape size"""super().__init__(env)self.shape = (shape, shape)obs_shape = self.shape + self.observation_space.shape[2:]self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)def observation(self, observation):# Normalize -> input[channel] - mean[channel]) / std[channel]transformations = transforms.Compose([transforms.Resize(self.shape), transforms.Normalize(0, 255)])return transformations(observation).squeeze(0)env_name = 'CarRacing-v2'
env = gym.make(env_name)
SKIP_N = 5
STACK_N = 4
env_ = FrameStack(ResizeObservation(GrayScaleObservation(CarV2SkipFrame(env, skip=SKIP_N)), shape=84), num_stack=STACK_N
)
二、智能体构建
因为是用的CNN,所以需要注意梯度消失的问题。
2.1 actor
主要架构就是CNN + MLP + maxMinScale
- CNN: 因为环境比较简单第一层用MaxPool2d采样,第二层进行AvgPool2d平滑
nn.Sequential(nn.Conv2d(in_channels=4, out_channels=16, kernel_size=4, stride=2),nn.ReLU(),nn.MaxPool2d(2, 2, 0),nn.Conv2d(in_channels=16, out_channels=32, kernel_size=4, stride=2),nn.ReLU(),nn.AvgPool2d(2, 2, 0),nn.Flatten() ) - MLP
- 对cnn提取的特征进行 LayerNorm (一定程度干预梯度消失)
- 对最后层全连接层的输出进行 LayerNorm (一定程度干预梯度消失)
- maxMinScale
- 最后通过tanh激活层action全部归一化到
[-1,1]之间 - 基于环境的动作上线限,用maxMinScale方式将最终的输出映射到
[动作下限,动作上限]
- 最后通过tanh激活层action全部归一化到
actor 网络
class TD3CNNPolicyNet(nn.Module):"""输入state, 输出action"""def __init__(self, state_dim: int, hidden_layers_dim: typ.List, action_dim: int, action_bound: typ.Union[float, gym.Env]=1.0, state_feature_share: bool=False):super(TD3CNNPolicyNet, self).__init__()self.state_feature_share = state_feature_shareself.low_high_flag = hasattr(action_bound, "action_space")print('action_bound=',action_bound)self.action_bound = action_boundif self.low_high_flag:self.action_high = torch.FloatTensor(action_bound.action_space.low)self.action_low = torch.FloatTensor(action_bound.action_space.high)self.cnn_feature = nn.Sequential(nn.Conv2d(in_channels=4, out_channels=16, kernel_size=4, stride=2),nn.ReLU(),nn.MaxPool2d(2, 2, 0),nn.Conv2d(in_channels=16, out_channels=32, kernel_size=4, stride=2),nn.ReLU(),nn.AvgPool2d(2, 2, 0),nn.Flatten())self.cnn_out_ln = nn.LayerNorm([512])self.features = nn.ModuleList()for idx, h in enumerate(hidden_layers_dim):self.features.append(nn.ModuleDict({'linear': nn.Linear(hidden_layers_dim[idx-1] if idx else 512, h),'linear_action': nn.ReLU()}))self.fc_out = nn.Linear(hidden_layers_dim[-1], action_dim)self.final_ln = nn.LayerNorm([action_dim])def max_min_scale(self, act):"""X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))X_scaled = X_std * (max - min) + min"""# print("max_min_scale(", act, ")")device_ = act.deviceaction_range = self.action_high.to(device_) - self.action_low.to(device_)act_std = (act - -1.0) / 2.0return act_std * action_range.to(device_) + self.action_low.to(device_)def forward(self, state):if len(state.shape) == 3:state = state.unsqueeze(0)try:x = self.cnn_feature(state)except Exception as e:print(state.shape)state = state.permute(0, 3, 1, 2)x = self.cnn_feature(state)x = self.cnn_out_ln(x)for layer in self.features:x = layer['linear_action'](layer['linear'](x))device_ = x.deviceif self.low_high_flag:return self.max_min_scale(torch.tanh(self.final_ln(self.fc_out(x))))return torch.tanh(self.final_ln(self.fc_out(x)).clip(-6.0, 6.0)) * self.action_bound
2.2 critic
- CNN: 设计同Actor
- concat状态和action
- 进行observe和action concat 之前对action进行线性变换(一定程度解决梯度消失 及 原地转圈)
class TD3CNNValueNet(nn.Module):"""输入[state, cation], 输出value"""def __init__(self, state_dim: int, action_dim: int, hidden_layers_dim: typ.List, state_feature_share=False):super(TD3CNNValueNet, self).__init__()self.state_feature_share = state_feature_shareself.q1_cnn_feature = nn.Sequential(nn.Conv2d(in_channels=4, out_channels=16, kernel_size=4, stride=2),nn.ReLU(),nn.MaxPool2d(2, 2, 0),nn.Conv2d(in_channels=16, out_channels=32, kernel_size=4, stride=2),nn.ReLU(),nn.AvgPool2d(2, 2, 0),nn.Flatten())self.q2_cnn_feature = nn.Sequential(nn.Conv2d(in_channels=4, out_channels=16, kernel_size=4, stride=2),nn.ReLU(),nn.MaxPool2d(2, 2, 0),nn.Conv2d(in_channels=16, out_channels=32, kernel_size=4, stride=2),nn.ReLU(),nn.AvgPool2d(2, 2, 0),nn.Flatten())self.features_q1 = nn.ModuleList()self.features_q2 = nn.ModuleList()for idx, h in enumerate(hidden_layers_dim + [action_dim]):self.features_q1.append(nn.ModuleDict({'linear': nn.Linear(hidden_layers_dim[idx-1] if idx else 512, h),'linear_activation': nn.ReLU()}))self.features_q2.append(nn.ModuleDict({'linear': nn.Linear(hidden_layers_dim[idx-1] if idx else 512, h),'linear_activation': nn.ReLU()}))self.act_q1_fc = nn.Linear(action_dim, action_dim)self.act_q2_fc = nn.Linear(action_dim, action_dim)self.head_q1_bf = nn.Linear(action_dim * 2, action_dim)self.head_q2_bf = nn.Linear(action_dim * 2, action_dim)self.head_q1 = nn.Linear(action_dim, 1)self.head_q2 = nn.Linear(action_dim, 1)def forward(self, state, action):if len(state.shape) == 3:state = state.unsqueeze(0)try:x1 = self.q1_cnn_feature(state)x2 = self.q2_cnn_feature(state)except Exception as e:state = state.permute(0, 3, 1, 2)x1 = self.q1_cnn_feature(state)x2 = self.q2_cnn_feature(state)for layer1, layer2 in zip(self.features_q1, self.features_q2):x1 = layer1['linear_activation'](layer1['linear'](x1))x2 = layer2['linear_activation'](layer2['linear'](x2))# 拼接状态和动作act1 = torch.relu(self.act_q1_fc(action.float()))act2 = torch.relu(self.act_q2_fc(action.float()))x1 = torch.relu( self.head_q1_bf(torch.cat([x1, act1], dim=-1).float()))# print("torch.cat([x1, action], dim=-1)=", torch.cat([x1, act1], dim=-1)[:5, :])x2 = torch.relu( self.head_q2_bf(torch.cat([x2, act2], dim=-1).float()))return self.head_q1(x1), self.head_q2(x2)def Q1(self, state, action):if len(state.shape) == 3:state = state.unsqueeze(0)try:x = self.q1_cnn_feature(state)except Exception as e:state = state.permute(0, 3, 1, 2)x = self.q1_cnn_feature(state)for layer in self.features_q1:x = layer['linear_activation'](layer['linear'](x))# 拼接状态和动作act1 = torch.relu(self.act_q1_fc(action.float()))x = torch.relu( self.head_q1_bf(torch.cat([x, act1], dim=-1).float()))return self.head_q1(x)
2.3 TD3算法简单调整
- policy_noise: 分布调整为(mean=0, std=每个维度动作范围) * self.policy_noise
- expl_noise: 分布调整为(mean=0, std=每个维度动作范围) * self.train_noise
3、训练
整体训练脚本可以看笔者的github test_TD3.py : CarRacing_TD3_test()
- 对训练做了一些调整: 在训练的过程中增加测试阶段:每隔
test_ep_freq进行测试 - 基于多次测试的奖励均值进行最佳模型参数保存
def CarRacing_TD3_test():env_name = 'CarRacing-v2'gym_env_desc(env_name)env = gym.make(env_name)env = FrameStack(ResizeObservation(GrayScaleObservation(CarV2SkipFrame(env, skip=5)), shape=84), num_stack=4)print("gym.__version__ = ", gym.__version__ )path_ = os.path.dirname(__file__)cfg = Config(env, # 环境参数save_path=os.path.join(path_, "test_models" ,'TD3_CarRacing-v2_test2-3'), seed=42,# 网络参数actor_hidden_layers_dim=[128], # 256critic_hidden_layers_dim=[128],# agent参数actor_lr=2.5e-4, #5.5e-5,critic_lr=1e-3, #7.5e-4, gamma=0.99,# 训练参数num_episode=15000,sample_size=128,# 环境复杂多变,需要保存多一些bufferoff_buffer_size=1024*100, off_minimal_size=256,max_episode_rewards=50000,max_episode_steps=1200, # 200# agent 其他参数TD3_kwargs={'CNN_env_flag': 1,'pic_shape': env.observation_space.shape,"env": env,'action_low': env.action_space.low,'action_high': env.action_space.high,# soft update parameters'tau': 0.05, # trick2: Delayed Policy Update'delay_freq': 1,# trick3: Target Policy Smoothing'policy_noise': 0.2,'policy_noise_clip': 0.5,# exploration noise'expl_noise': 0.5,# 探索的 noise 指数系数率减少 noise = expl_noise * expl_noise_exp_reduce_factor^t'expl_noise_exp_reduce_factor': 1 - 1e-4})agent = TD3(state_dim=cfg.state_dim,actor_hidden_layers_dim=cfg.actor_hidden_layers_dim,critic_hidden_layers_dim=cfg.critic_hidden_layers_dim,action_dim=cfg.action_dim,actor_lr=cfg.actor_lr,critic_lr=cfg.critic_lr,gamma=cfg.gamma,TD3_kwargs=cfg.TD3_kwargs,device=cfg.device)agent.train()train_off_policy(env, agent, cfg, done_add=False, train_without_seed=True, wandb_flag=False, test_ep_freq=100)agent.load_model(cfg.save_path)agent.eval()env = gym.make(env_name, render_mode='human') # env = FrameStack(ResizeObservation(GrayScaleObservation(CarV2SkipFrame(env, skip=5)), shape=84), num_stack=4)play(env, agent, cfg, episode_count=2)
4、训练结果观察及后续工作
由于上传大小限制5MB, 所以对较多直线部分进行了裁剪
最终训练的时候发现会突然陷入低分状态,可以考虑间隔n(可以设置较大比如2000)个episode和最佳的reward比较,分数低于x%个百分点,就重新载入最佳参数,以继续训练。

这篇关于强化学习_06_pytorch-TD3实践(CarRacing-v2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









