本文主要是介绍CornerNet:经典keypoint-based方法,通过定位角点进行目标检测 | ECCV2018,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文提出了CornerNet,通过检测角点对的方式进行目标检测,与当前的SOTA检测模型有相当的性能。CornerNet借鉴人体姿态估计的方法,开创了目标检测领域的一个新框架,后面很多论文都基于CorerNet的研究拓展出新的角点目标检测
来源:晓飞的算法工程笔记 公众号
论文: CornerNet: Detecting Objects as Paired Keypoints

- 论文地址:https://arxiv.org/abs/1808.01244
- 论文代码:https://github.com/princeton-vl/CornerNet
Introduction
目标检测算法大都与anchor box脱不开关系,论文认为使用anchor box有两个缺点:1) 需要在特征图上平铺大量的anchor box避免漏检,但最后只使用很小一部分的anchor box,造成正负样本不平衡且拖慢训练。 2) anchor box的引入带来了额外的超参数和特别的网络设计,使得模型训练变复杂。
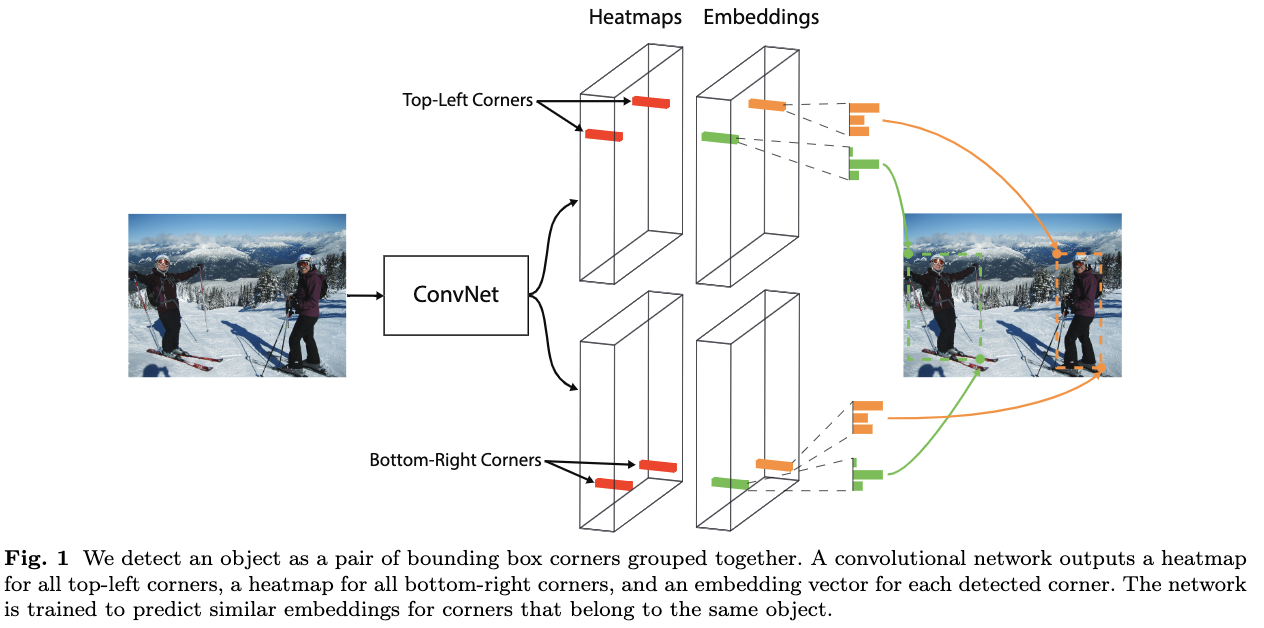
基于上面的考虑,论文提出了CornerNet,将目标检测定义为左上角点和右下角点的检测。网络结构如图1所示,通过卷积网络预测出左上角点和右下角点的热图,然后将两组热图组合输出预测框,彻底去除了anchor box的需要。论文通过实验也表明CornerNet与当前的主流算法有相当的性能,开创了目标检测的新范式。
CornerNet
Overview
CornerNet中通过检测目标的左上角点和右下角点进行目标检测,卷积网络预测两组热图(heatmap)来表示不同类别目标的角点位置,分别对应左上角点和右下角点。为了将左上角点和左下角点进行对应,为每个角点预测一个embedding向量,属于同一个目标的两个角点的距离会非常小。另外还增加了偏移量(offset)的预测,对角点的位置进行小幅度的调整。
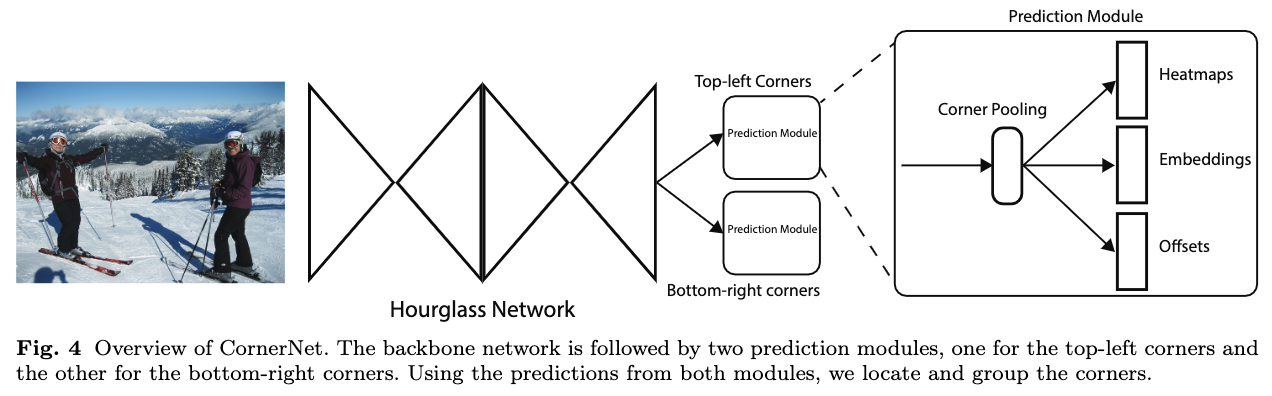
CornerNet的结构如图4所示,使用hourglass网络作为主干网络,通过独立的两个预测模块输出两组结果,分别对应左上角点和右下角点,每个预测模块通过corner池化输出用于最终预测的热图、embedding向量和偏移。
Detecting Corners

预测的热图的大小为 C × H × W C\times H\times W C×H×W, C C C为类别数量,不包含背景类。每个GT的角点仅对应一个正样本点,其它的点均为负样本点,但在训练时不会等同地惩罚负样本点,而是减少正样本点半径内的负样本点的惩罚力度。这样做的原因主要在于,靠近正样本点的负样本点能够产生有足够高IoU的预测框,如图5所示。
半径的大小根据目标的大小来设定,保证产生的预测框能至少满足IoU大于 t t t。在设定半径后,根据二维高斯核 e − x 2 + y 2 2 σ 2 e^{-\frac{x^2+y^2}{2\sigma^2}} e−2σ2x2+y2进行惩罚衰减, x x x和 y y y为相对正样本点的距离, σ \sigma σ为半径的1/3。定义 p c i j p_{cij} pcij为位置 ( i , j ) (i,j) (i,j)关于类别 c c c的预测分数, y c i j y_{cij} ycij为根据高斯核得出的分数,论文设计了一个focal loss的变种:

由于池化层的存在,原图位置 ( x , y ) (x,y) (x,y)在特征图上通常会被映射到 ( ⌊ x n ⌋ , ⌊ y n ⌋ ) (\lfloor\frac{x}{n}\rfloor, \lfloor\frac{y}{n}\rfloor) (⌊nx⌋,⌊ny⌋), n n n为下采样因子。在将热图中的点映射回原图时,由于池化的原因可能会有精度的损失,这会极大地影响小目标的IoU计算。为了解决这个问题,论文提出了偏移预测,在将热图位置映射到原图前,小幅调整角点的位置:
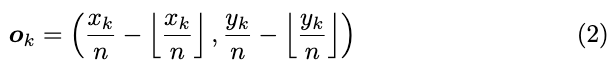
o k o_k ok为偏移值, x x x和 y y y为角点 k k k的坐标。需要注意的是,网络对左上角点和右下角点分别预测一组偏移值,偏移值在类别间共用。在训练时,对正样本点添加smooth L1损失来训练角点的偏移值:
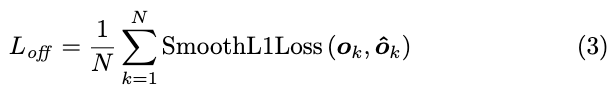
Grouping Corners
当图片中存在多个目标时,需要区分预测的左上角点和右下角点的对应关系,然后组成完整的预测框。这里论文参考了人体姿态估计的策略,每个角点预测一个一维的embedding向量,根据向量间的距离进行对应关系的判断。定义 e t k e_{t_k} etk目标 k k k左上角点的embedding向量, e b k e_{b_k} ebk为右下角的embedding向量,使用pull损失和push损失来分别组合以及分离角点:
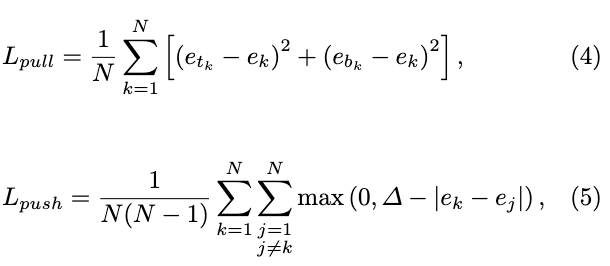
e k e_k ek为 e t k e_{t_k} etk和 e b k e_{b_k} ebk的平均值, Δ = 1 \Delta=1 Δ=1,这里的pull损失和push损失跟偏移一样,仅对正样本点使用。
Corner Pooling

角点的位置一般都没有目标信息,为了判断像素是否为左上角点,需要向右水平查找目标的最高点以及向下垂直查找目标的最左点。基于这样的先验知识,论文提出corner pooling来定位角点。
假设需要确定位置 ( i , j ) (i,j) (i,j)是否为左上角点,首先定义 f t f_t ft和 f l f_l fl为左上corner pooling的输入特征图, f t i , j f_{t_{i,j}} fti,j和 f l i , j f_{l_{i,j}} fli,j为输入特征图在位置 ( i , j ) (i,j) (i,j)上的特征向量。特征图大小为 H × W H\times W H×W,corner pooling首先对 f t f_t ft中 ( i , j ) (i,j) (i,j)到 ( i , H ) (i,H) (i,H)的特征向量进行最大池化输出向量 t i j t_{ij} tij,同样对 f l f_l fl中 ( i , j ) (i,j) (i,j)到 ( W , j ) (W,j) (W,j)的特征向量也进行最大池化输出向量 l i j l_{ij} lij,最后将 t i j t_{ij} tij和 l i j l_{ij} lij相加。完整的计算可表示为:
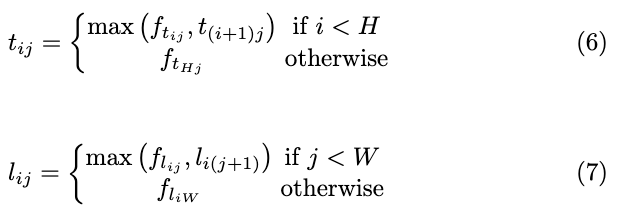
公式6和公式7采用element-wise最大池化。
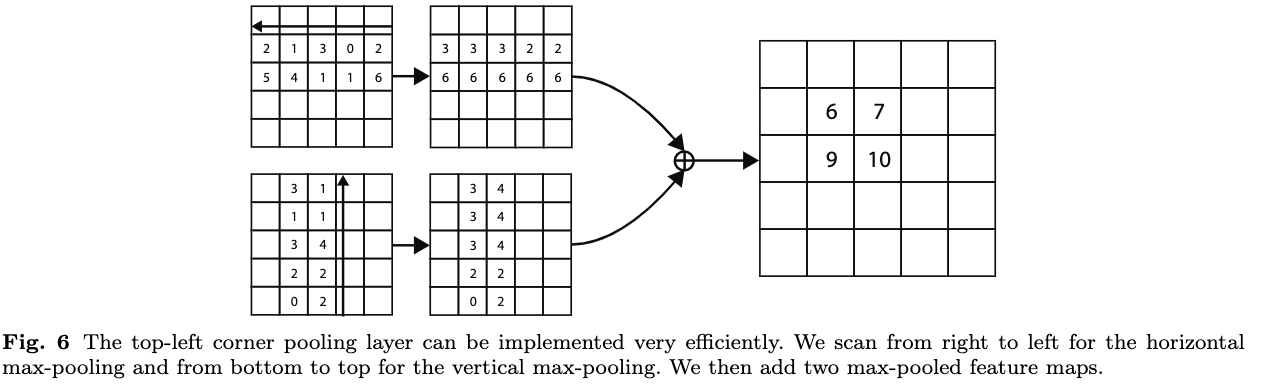
在实现时,公式6和公式7可以如图6那样进行整张特征图的高效计算,有点类似动态规划。对于左上角点的corner pooling,对输入特征图分别进行从右往左和从下往上的预先计算,每个位置只需要跟上一个位置的输出进行element-wise最大池化即可,最后直接将两个特征图相加即可。
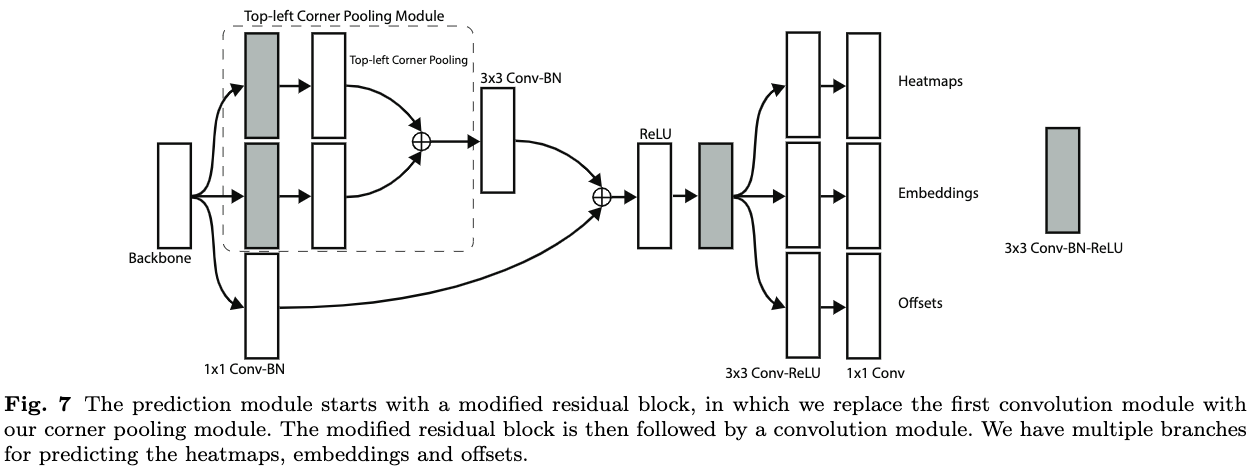
完整的预测模块结构如图7所示,实际上是个改进版residual block,将 3 × 3 3\times 3 3×3卷积模块替换为corner pooling模块,最后输出热图、embedding向量和偏移。
Hourglass Network
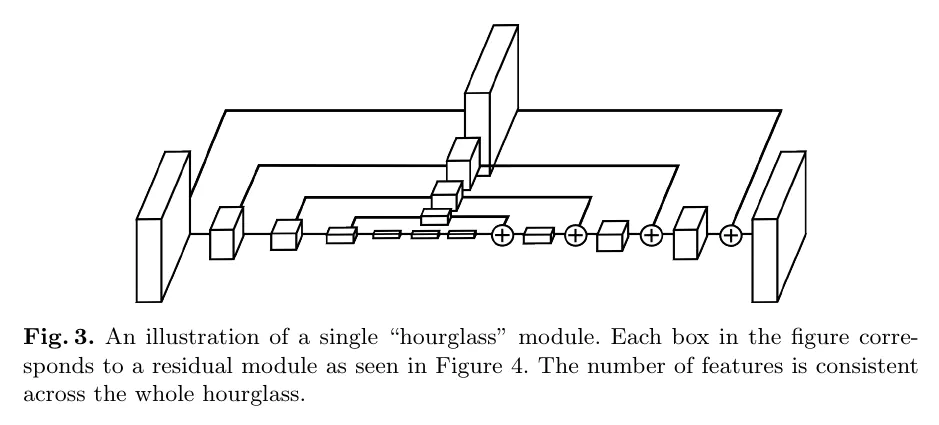
CornerNet使用hourglass网络作为主干网络,这是用于人体姿态估计任务中的网络。Hourglass模块如图3所示,先对下采样特征,然后再上采样恢复,同时加入多个短路连接来保证恢复特征的细节。论文采用的hourglass网络包含两个hourglass模块,并做了以下改进:
- 替换负责下采样的最大池化层为stride=2的卷积
- 共下采样五次并逐步增加维度(256, 384, 384, 384, 512)
- 上采样使用两个residual模块+最近邻上采样
- 短路连接包含2个residual模块
- 在网络的开头,使用4个stride=2、channel=128的 7 × 7 7\times 7 7×7卷积模块以及1个stride=2、channel=256维度的residual模块进行处理
- 原版的hourglass网络会对每个hourglass模块添加一个损失函数进行有监督学习,而论文发现这对性能有影响,没有采用这种方法
Experiments

对比corner pooling的效果。

对比负样本点惩罚衰减的效果。

对比hourglass网络与corner检测搭配的效果

对比热图和偏移预测的效果。
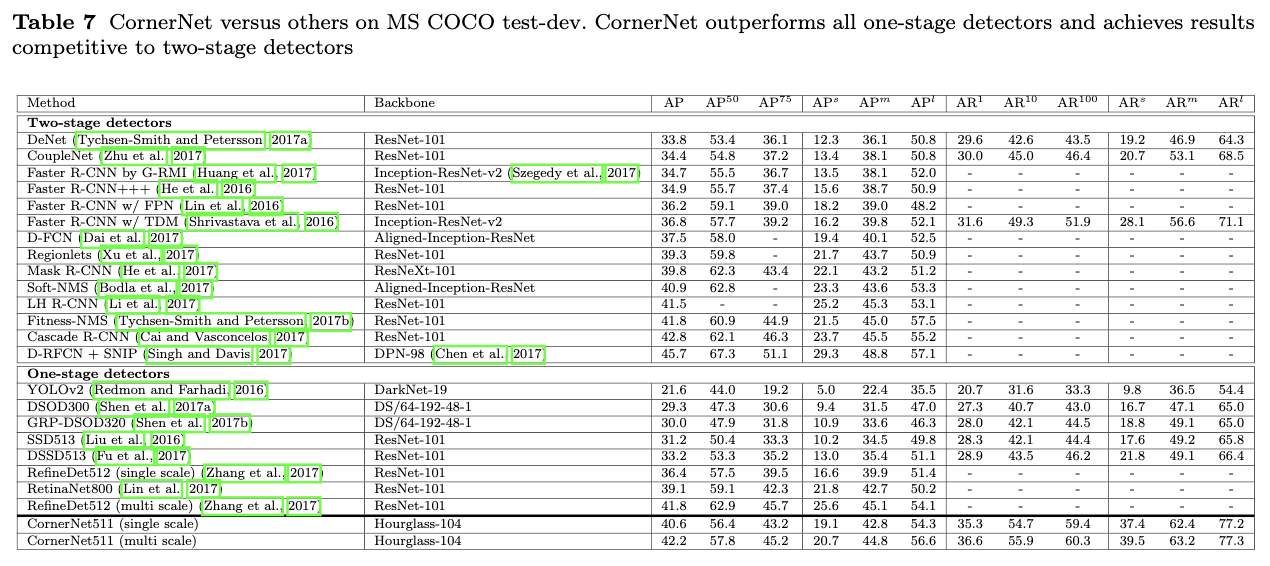
与其它各种类型的检测网络进行对比。
CONCLUSION
论文提出了CornerNet,通过检测角点对的方式进行目标检测,与当前的SOTA检测模型有相当的性能。CornerNet借鉴人体姿态估计的方法,开创了目标检测领域的一个新框架,后面很多论文都基于CorerNet的研究拓展出新的角点目标检测。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

这篇关于CornerNet:经典keypoint-based方法,通过定位角点进行目标检测 | ECCV2018的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




