本文主要是介绍从ASCII码到Unicode,最终选择UTF-8编码的趣事【学习笔记】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://www.bilibili.com/video/BV1h7411V7Xw?from=search&seid=6458930640632168365
上面链接位B站视频链接,讲的是字符串编码,是我所看到的讲解最好的一个,希望对你有帮助。
上一张图:

以下位对上图的一种解释。
在计算机中,基本的存储单位为位:bit 一个位可以表示两种数字0和1,一个字节(Byte)= 8位(bit)
可以表示成256种组合
如何把数字汉字等字符存储在计算机中,工程师们发明了一种ASCII 码,上个实际60年代,美国人制造出来一种编码方式,将英文字符与字节做了统一的规定,ascii中包含字母、数字、符号共计128个。
需要注意的是Ucicode只是一个字符集,它只规定了符号的二进制代码,却没有给出这个二进制代码应该如何对应进行存储,具体该使用几个字节来存储一个字符,因此,Unicode不适于直接用来编码存储字符,为此,人们设计了utf-8的编码, 它是在互联网上广泛使用的一种unicode编码实现方式,使用它可以使用1-4个字节表示一种字符,根据不同的符号变化长度,目前多数语言都支持uft-8编码,它是一种最通行的编码方式。
5.早期的程序设计语言中都使用ASCII码每一个字节来保存一个字符,一个字符对应一个字节,后来,由于多种语言的出现,使用的编码方式有所改变,字符和字节就不是一一对应的关系了,
例如:一个汉字当以utf-8编码方式存储时,它占3个字节;
print(str1.encode(encoding = 'utf-8')) b'\xe6\x88\x91' print(len(str1.encode(encoding = 'utf-8'))) 3
一个汉字当以gb2312或gbk编码方式存储时,它占2个字节。
print(str1.encode(encoding = 'gbk')) b'\xce\xd2' print(len(str1.encode(encoding = 'gbk'))) 2
print(str1.encode(encoding = 'gb2312')) b'\xce\xd2' print(len(str1.encode(encoding = 'gb2312'))) 2
Python中默认是以字符来进行存储的,因此,汉字和字母具有相同的地位:在计算字符长度时,一个字母和一个汉字的字符长度都为1。
--------------------------------------------------------
理解2:(这个貌似没有上一种好理解)
视频链接地址:字母,符号和神奇的Unicode
希望感兴趣的可以看一下。
整理的不是很详细,仅供参考。
今天在看视频的时候,发现一个国外的讲解关于UTF-8的这样的一个发展。
在早期的20世纪60年代,人们通过一些电传设备,一边发送了一些数字,另一边会出现同一个字母,但在20世纪60年代中期,需要有一个标准以使其规范,美国采用了ASCII码,这是美国信息交换标准代码,它是一个7位的二进制系统(应该是8位,第1位是0),你输入的每个英文字母,都可以转换成7个二进制数并通过网络发送,这意味着您可以拥有0-127之间的数字,它的前32位表示的是一些空格,回车之类的字符,在后面他们又添加了一些数字,标点符号等,很聪明的一件事是用65来表示’A‘。用二进制表示就是0100 0001,并且也出现了用97表示的小写的字母‘a’,而进制表示就是0110 0001。
随着时间的推移,事情发生了一些变化,全世界各个国家使用的语言的符号不一样,ASCII码不够用了,后来就出现了Unicode编码,Unicode现在有一个超过十万个字符的列表,涵盖了你可能用任何语言书写的所有内容,有英文字母,中文,阿拉伯字母字符,最后得到的是10万多个数字分配的10万多个字符。
与三个问题需要注意:1.你必须摆脱英文文本中所有的0。2许多旧计算机系统对理解连续的8个0,会输出一个null,当连续发送8个0的时候,它就会终止接收,所以不能在任何地方连续使用8个0。3必须考虑向后兼容,您必须能够使用Unicode文本将其放入只能理解基本的ASCII的内容中,并且或多或少的为英文文本工作
utf-8解决了这些所有的问题,它首先采用ASCII,如果你有128以下的东西,那可以表示用7位二进制数来表示,如果需要更多的表示我就就先写出110,这意味着这是一个新字符的开头,这个字符长度为2个字节,一个字节为8位,而后我们将用10作为延续,在左右的空白的地方可以补充01。
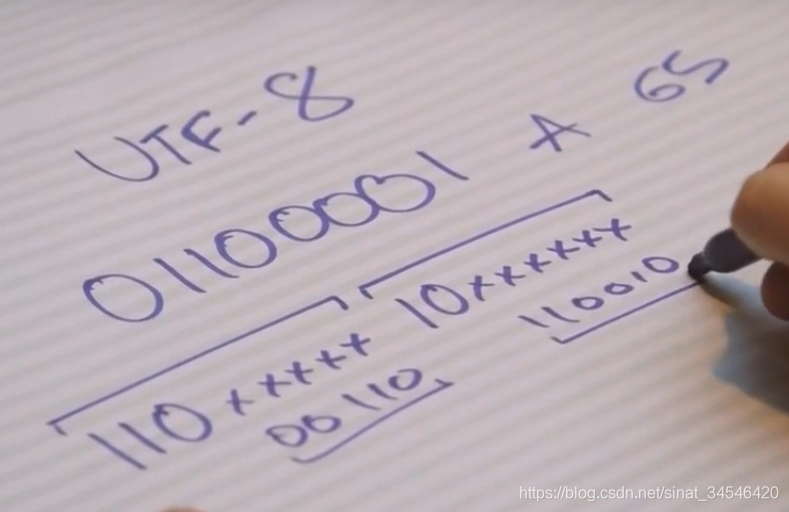

这篇关于从ASCII码到Unicode,最终选择UTF-8编码的趣事【学习笔记】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



