本文主要是介绍caffe保存训练日志并绘制loss,acc曲线,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境windows10 x64+caffe
1、导出训练日志到log文件
start.bat是我训练网络使用的 批处理文件

start.bat的内容是:

因为我把caffe加到了系统path中,所以这里直接写caffe train。后面的--solver 是训练用到的协议文件,定义一些参数,如指定网络定义文件,指定学习率,模型保存位置,学习衰减参数,以及优化算法等。最后的这个 >log/train.log 2>&1就是将训练日志保存到log文件夹下的train.log文件中,2>&1就是用来将标准错误2重定向到标准输出1中的。此处&就是为了让bat将1解释成标准输出而不是文件1。
双击start.bat就会开始训练网络,并生成日志文件:train.log

2、利用caffe自带的工具可视化log日志
如图所示,在caffe根目录下的tools/extra文件夹下,有几个文件是用来可视化log日志的:
extract_seconds.py , parse_log.py ,parse_log.sh ,plot_training_log.py.example

将其复制到log文件夹下,并将plot_training_log.py.example的后缀example删除

然后在这个文件夹下打开一个终端,输入 python parse_log.py train.log ./ 命令,在log文件夹下生成train.log.test和train.log.test文件,用于后续画图:

接下来需要修改plot_training_log.py的几处代码:
(1)在这个文件中不调用parse_log.sh文件,因为上一步已经单独调用了parse_log.py生成了.train和.test文件,如果在这里调用会出现生成的train.log.train和train.log.test两个文件中只有一行,sh脚本的具体代码我没看,但是这里我注释掉不调用。

(2)修改两处,#改为N,下一行的split()改为split(',')

原因:因为使用parsh_log.py生成的文件形式是下图中这样的:
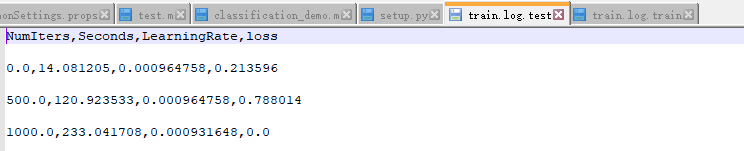

第一行是以NumIters开头,所以在读取数据时这一行要跳过,判断规则就是如果一行的第一个字母是N就跳过。这样就会只读取后面的数字行。
(3)修改如下数据

修改完这些地方之后,在命令行中输入命令:python plot_training_log.py 0 test_learn_rate.png train.log
这里有三个参数:
0 表示上图中 train和test都有四个值(Iters,Seconds,Learning rate, loss),组合就会出现8种(一行是一种)图的类型如下:
['Test learning rate vs. Iters','Test learning rate vs. Seconds','Test loss vs. Iters', 'Test loss vs. Seconds','Train learning rate vs. Iters', 'Train learning rate vs. Seconds', 'Train loss vs. Iters', 'Train loss vs. Seconds']这个0就表示索引为0的图类型:'Test learning rate vs. Iters'
test_learn_rate.png 表示要绘制的图保存的名字
train.log 就是前面log日志文件
运行画图命令之后,输出的图片为测试的学习率和迭代次数之间的图。想画其他变量之间的关系图就把参数0修改为其他的即可。

2 testloss/iters

4 train_learning_rate/iters

6 train_loss/iter

这篇关于caffe保存训练日志并绘制loss,acc曲线的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









