本文主要是介绍Linux NVMe Driver学习笔记之7:Identify初始化及命令提交过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇文章紧接上回分解,在nvme_probe函数的最后一步调用nvme_reset_work进行reset操作,nvme_reset_work的主要工作可以概括如下几个步骤:
进入nvme_reset_work函数后先检查NVME_CTRL_RESETTING标志,来确保nvme_reset_work不会被重复进入。
调用nvme_pci_enable
调用nvme_configure_admin_queue
调用nvme_init_queue
调用nvme_alloc_admin_tags
调用nvme_init_identify
调用nvme_setup_io_queues
调用nvme_start_queues/nvme_dev_add之后,接着调用nvme_queue_scan
上篇文章中,我们解析了nvme_init_queue和nvme_alloc_admin_tags的内容,本文我们接着介绍nvme_reset_work中的其他函数。
我们来看看nvme_init_identify的内容:
int nvme_init_identify(struct nvme_ctrl *ctrl)
{
struct nvme_id_ctrl *id;
u64 cap;
int ret, page_shift;
u32 max_hw_sectors;
// 读取NVMe协议的版本号
ret = ctrl->ops->reg_read32(ctrl, NVME_REG_VS, &ctrl->vs);
if (ret) {
dev_err(ctrl->device, "Reading VS failed (%d)\n", ret);
return ret;
}
// 读取NVMe controller寄存器CAP值
ret = ctrl->ops->reg_read64(ctrl, NVME_REG_CAP, &cap);
if (ret) {
dev_err(ctrl->device, "Reading CAP failed (%d)\n", ret);
return ret;
}
page_shift = NVME_CAP_MPSMIN(cap) + 12;
// NVMe 1.1之后,支持subsystem Reset
if (ctrl->vs >= NVME_VS(1, 1, 0))
ctrl->subsystem = NVME_CAP_NSSRC(cap);
ret = nvme_identify_ctrl(ctrl, &id); //读取identify data
if (ret) {
dev_err(ctrl->device, "Identify Controller failed (%d)\n", ret);
return -EIO;
}
ctrl->vid = le16_to_cpu(id->vid);
ctrl->oncs = le16_to_cpup(&id->oncs);
atomic_set(&ctrl->abort_limit, id->acl + 1);
ctrl->vwc = id->vwc;
ctrl->cntlid = le16_to_cpup(&id->cntlid);
memcpy(ctrl->serial, id->sn, sizeof(id->sn));
memcpy(ctrl->model, id->mn, sizeof(id->mn));
memcpy(ctrl->firmware_rev, id->fr, sizeof(id->fr));
if (id->mdts)
max_hw_sectors = 1 << (id->mdts + page_shift - 9);
else
max_hw_sectors = UINT_MAX;
ctrl->max_hw_sectors =
min_not_zero(ctrl->max_hw_sectors, max_hw_sectors);
nvme_set_queue_limits(ctrl, ctrl->admin_q);
ctrl->sgls = le32_to_cpu(id->sgls);
ctrl->kas = le16_to_cpu(id->kas);
if (ctrl->ops->is_fabrics) {
.... // NVMe over fabrics内容省略
}
} else {
ctrl->cntlid = le16_to_cpu(id->cntlid);
}
kfree(id);
return ret;
}
从上面的code来看,主要做了两部分的工作:
-
调用nvme_identify_ctrl读取identify data.
-
调用nvme_set_queue_limits设置queue write cache的大小.
先看一下nvme_identify_ctrl的代码:
int nvme_identify_ctrl(struct nvme_ctrl *dev, struct nvme_id_ctrl **id)
{
struct nvme_command c = { };
int error;
/* gcc-4.4.4 (at least) has issues with initializers and anon unions */
c.identify.opcode = nvme_admin_identify;
c.identify.cns = cpu_to_le32(NVME_ID_CNS_CTRL);
*id = kmalloc(sizeof(struct nvme_id_ctrl), GFP_KERNEL);
if (!*id)
return -ENOMEM;
error = nvme_submit_sync_cmd(dev->admin_q, &c, *id,
sizeof(struct nvme_id_ctrl));
if (error)
kfree(*id);
return error;
}
首先,nvme_identify_ctrl函数先建立identify Command(opcode=0x6),
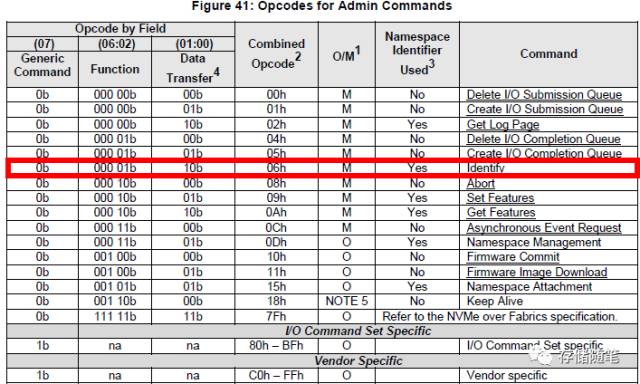
Identify Command下发后返回的是4KB的Identify Data Structure, 这个data structure可以描述controller,也可以描述namespace, 具体是描述什么要取决于CNS(Controller or Namespace Structure) byte.
-
CNS=0x00h,代表描述的是Namespace data structure;
-
CNS=0x01h,代表描述的是Controller data structure;
-
CNS=0x02h,代表描述的是Namespace list;
上面代码中,我们可以看到在赋值c.identify.cns时,采用了cpu_to_le32这样的函数,因为在nvme协议里规定的一些消息格式都是按照小端存储的,但是我们的主机可能是小端的x86,也可能是大端的arm或者其他类型,用了这样的函数就可以做到主机格式和小端之间的转换,让代码更好得跨平台,这也是Linux系统强大的地方。
c.identify.cns = cpu_to_le32(NVME_ID_CNS_CTRL);
nvme_identify_ctrl函数已经建立了Identify Command,驱动是怎么提交这个admin command呢?实际上,admin command的提交过程主要调用了nvme_submit_sync_cmd函数,但最终调用的函数是__nvme_submit_sync_cmd:
int __nvme_submit_sync_cmd(struct request_queue *q, struct nvme_command *cmd,
union nvme_result *result, void *buffer, unsigned bufflen,
unsigned timeout, int qid, int at_head, int flags)
{
struct request *req;
int ret;
req = nvme_alloc_request(q, cmd, flags, qid);
if (IS_ERR(req))
return PTR_ERR(req);
req->timeout = timeout ? timeout : ADMIN_TIMEOUT;
if (buffer && bufflen) {
ret = blk_rq_map_kern(q, req, buffer, bufflen, GFP_KERNEL);
if (ret)
goto out;
}
blk_execute_rq(req->q, NULL, req, at_head);
if (result)
*result = nvme_req(req)->result;
ret = req->errors;
out:
blk_mq_free_request(req);
return ret;
}
从上面的代码,可以看到nvme_submit_sync_cmd函数的执行过程主要有三步:
-
调用nvme_alloc_request函数,进一步调用blk_mq_alloc_request_hctx申请一个request_queue, 并完成相应的初始化;
-
如果buffer & bufflen不为0,则说明这次nvme admin命令需要传输数据,既然需要传输数据,就需要得到bio的支持, 那么就调用blk_rq_map_kern完成request queue与bio以及bio与内核空间buffer的关联。毕竟block layer并不认识内核空间或者用户空间,而只认识bio。
-
第三步是最后一步,也是最关键的一步。调用blk_excute_rq实现最终的命令发送。
我们先看看nvme_alloc_request的代码:
struct request *nvme_alloc_request(struct request_queue *q,
struct nvme_command *cmd, unsigned int flags, int qid)
{
struct request *req;
if (qid == NVME_QID_ANY) {
req = blk_mq_alloc_request(q, nvme_is_write(cmd), flags);
} else {
req = blk_mq_alloc_request_hctx(q, nvme_is_write(cmd), flags,
qid ? qid - 1 : 0);
}
if (IS_ERR(req))
return req;
req->cmd_type = REQ_TYPE_DRV_PRIV;
req->cmd_flags |= REQ_FAILFAST_DRIVER;
nvme_req(req)->cmd = cmd;
return req;
}
如上述代码显示,blk_mq_alloc_request_hctx申请一个request_queue并初始化之后,cmd参数,在这里也就是Identify command会传递给nvme_req。
我们再看看最关键的blk_excute_rq的代码:
int blk_execute_rq(struct request_queue *q, struct gendisk *bd_disk,
struct request *rq, int at_head)
{
DECLARE_COMPLETION_ONSTACK(wait);
char sense[SCSI_SENSE_BUFFERSIZE];
int err = 0;
unsigned long hang_check;
if (!rq->sense) {
memset(sense, 0, sizeof(sense));
rq->sense = sense;
rq->sense_len = 0;
}
rq->end_io_data = &wait;
blk_execute_rq_nowait(q, bd_disk, rq, at_head, blk_end_sync_rq);
/* Prevent hang_check timer from firing at us during very long I/O */
hang_check = sysctl_hung_task_timeout_secs;
if (hang_check)
while (!wait_for_completion_io_timeout(&wait, hang_check * (HZ/2)));
else
wait_for_completion_io(&wait);
if (rq->errors)
err = -EIO;
if (rq->sense == sense) {
rq->sense = NULL;
rq->sense_len = 0;
}
return err;
}
调用blk_execute_rq_nowait函数将request插入执行队列,调用wait_for_completion_io等待命令的完成。
这篇关于Linux NVMe Driver学习笔记之7:Identify初始化及命令提交过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









