本文主要是介绍Spring中你一定要知道的@PostConstruct/@PreDestroy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 功能
- 源码
- 解析
- 执行
功能
Spring中存在很多回调,但是执行他们的时机都不相同,也许大家用的最多的是InitializingBean.afterPropertiesSet,这个方法的作用如名称一样,是bean初始化后执行的一个回调操作,而@PostConstruct是initMethod,初始化回调方法,它是在afterPropertiesSet之前执行的,并且可以有多个@PostConstruct和@PreDestory,所以它的功能会更强大一点。
但需要注意的是,多个@PostConstruct方法的顺序是:父类内从先到后,然后子类内从先到后,多个@PreDestory方法的顺序是:子类内从先到后,父类内从先到后。
另外一个点:这里我说它是initMethod是因为Spring本身对这个方法解析后的命名就叫initMethod,保存在InitDestroyAnnotationBeanPostProcessor中,真正意义上的initMethod是保存在BeanDefinition里的,并且只有一个,所以这个要区分一下。
如下示例:
@Component
public class CustomConfig7 {@PostConstructpublic void t() {System.out.println("customConfig7 init");}@PostConstructpublic void t2() {System.out.println("customConfig7 init2");}@PreDestroypublic void d() {System.out.println("customConfig7 destroy");}@PreDestroypublic void d2() {System.out.println("customConfig7 destroy2");}
}源码
它的解析和执行过程比较简单,很快就可以看完。
解析
位置:org.springframework.context.annotation.CommonAnnotationBeanPostProcessor#postProcessMergedBeanDefinition

这里它是调用了父类的方法postProcessMergedBeanDefinition进行解析的, 下面findResourceMetadata是依赖注入的注入点解析。
private LifecycleMetadata findLifecycleMetadata(Class<?> clazz) {// lifecycleMetadataCache 初始化时赋了初始值,所以这里不会走if (this.lifecycleMetadataCache == null) {return buildLifecycleMetadata(clazz);}// 从缓存种获取// 双重判断LifecycleMetadata metadata = this.lifecycleMetadataCache.get(clazz);if (metadata == null) {synchronized (this.lifecycleMetadataCache) {metadata = this.lifecycleMetadataCache.get(clazz);if (metadata == null) {// 解析classmetadata = buildLifecycleMetadata(clazz);this.lifecycleMetadataCache.put(clazz, metadata);}return metadata;}}return metadata;}这里会看到synchronized,Spring创建bean,也就是bean的生命周期这个过程时单线程的,但它这里加了锁,这个问题,作为底层框架要保证线程安全,因为在业务场景下,并不都是单线程的,比如:
你定义了一个bean,简称A,同时你实现了接口InitializingBean,在回调方法时,你开启了一个线程B,这个线程B可能做数据查询,数据缓存等,那么他需要redis,datasource,sqlSession这些,那么它也是从beanFactory获取bean,这时Spring也在getBean,线程B和Spring就已经并行了,就是应用本身是多线程的,作为底层的框架需要保证线程安全。
那接下来,我们看一下构建方法:
位置:org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor#buildLifecycleMetadata
private LifecycleMetadata buildLifecycleMetadata(final Class<?> clazz) {// 进行过滤// initAnnotationType -> @PostConstruct// destroyAnnotationType -> @PreDestroyif (!AnnotationUtils.isCandidateClass(clazz, Arrays.asList(this.initAnnotationType, this.destroyAnnotationType))) {return this.emptyLifecycleMetadata;}List<LifecycleElement> initMethods = new ArrayList<>();List<LifecycleElement> destroyMethods = new ArrayList<>();Class<?> targetClass = clazz;do {final List<LifecycleElement> currInitMethods = new ArrayList<>();final List<LifecycleElement> currDestroyMethods = new ArrayList<>();
// Spring的反射工具,解析并遍历class里的方法ReflectionUtils.doWithLocalMethods(targetClass, method -> {// 如果方法含有注解:@PostConstruct,就添加到currInitMethodsif (this.initAnnotationType != null && method.isAnnotationPresent(this.initAnnotationType)) {LifecycleElement element = new LifecycleElement(method);currInitMethods.add(element);if (logger.isTraceEnabled()) {logger.trace("Found init method on class [" + clazz.getName() + "]: " + method);}}// 如果方法含有注解:@PreDestroy,就添加到currDestroyMethodsif (this.destroyAnnotationType != null && method.isAnnotationPresent(this.destroyAnnotationType)) {currDestroyMethods.add(new LifecycleElement(method));if (logger.isTraceEnabled()) {logger.trace("Found destroy method on class [" + clazz.getName() + "]: " + method);}}});initMethods.addAll(0, currInitMethods);destroyMethods.addAll(currDestroyMethods);// *** 注意 ***// 这里它获取了父类,所以这里只要父类有注解,也会被加进来targetClass = targetClass.getSuperclass();}while (targetClass != null && targetClass != Object.class);// 都没有注解就返回空对象,可以在一开始就已经过滤过了,所以这里都是有的return (initMethods.isEmpty() && destroyMethods.isEmpty() ? this.emptyLifecycleMetadata :new LifecycleMetadata(clazz, initMethods, destroyMethods));}
注意: 上面它是一个向上的循环,先顺序遍历当前类,再找父类,一直往上找,而有一点不一样:
initMethods.addAll(0, currInitMethods);
destroyMethods.addAll(currDestroyMethods);
initMethod每次都放第一个,所以,父类的@PostConstruct应该在子类之前执行,这个也和类的实例是一样的顺序。
destroyMethod是顺序放入,执行顺序应该是子类先执行;
这个执行顺序,这里只是根据它放入的顺序的一个猜测,最终顺序还得看它执行的过程。
执行
在初始化bean时,spring执行了一个后置处理器,而执行@PostConstruct/@PreDestroy就是在里面执行的
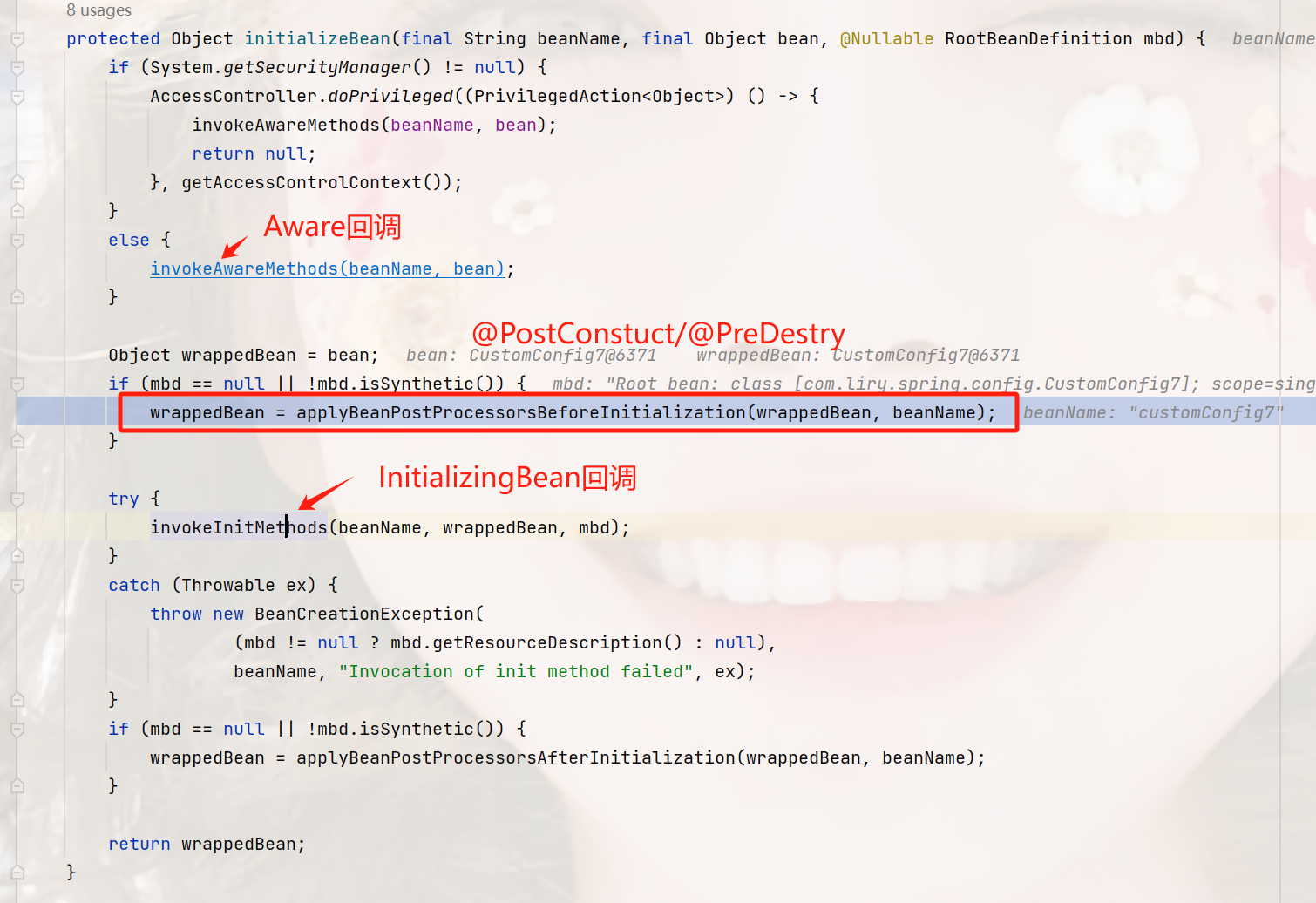
位置:org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor#postProcessBeforeInitialization
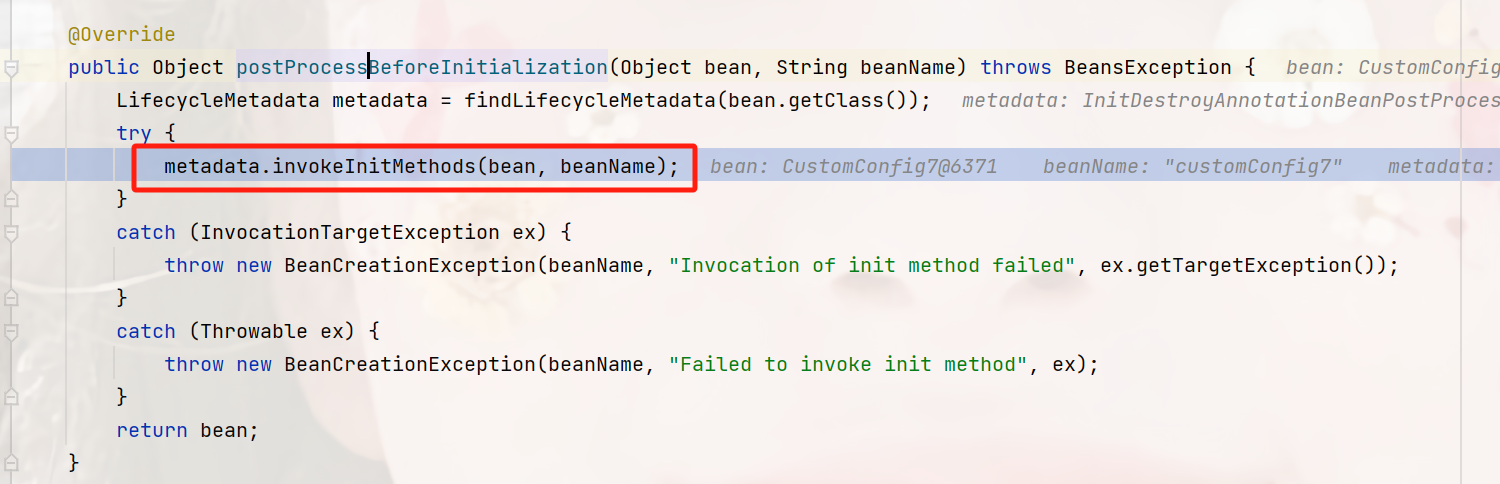
LifecycleMetadata是在解析时生成的对象,看一下它的属性:

它的执行如下,是通过遍历的方式,所以@PonstConstruct执行的顺序是先执行父类的,然后执行子类的。

至于@PreDestroy,它是在Spring容器关闭时执行的,有ApplicationContext触发,位置:
org.springframework.context.support.AbstractApplicationContext#doClose
同样最终执行的位置和@PostConstruct是同一个处理器,两个的代码几乎是一样的,都是直接遍历解析号的方法集,然后顺序执行,不过,这里先执行的是子类,然后才是父类的。

这篇关于Spring中你一定要知道的@PostConstruct/@PreDestroy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








