本文主要是介绍分库分表下非拆分键的查询方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分库分表下非拆分键的查询方案
在现有的互联网业务模式下,数据库分库分表已经成为解决数据库瓶颈的一个普遍的解决方案。但是分库分表在带来解决方案的同时,也产生了一些新的问题。
一、分库分表带来的问题
1.事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2.复杂查询
分库分表后将无法进行join操作,查询禁止不带切分的维度的查询,即使中间件可以支持这种查询,可以在内存中组装,但是这种需求往往不应该在在线库查询,或者可以通过其他方法转换到切分的维度来实现。
在订单数据的分库分表场景,按照订单id取模虽然很好地满足了订单数据均匀地保存在数据库中,但在买家查看自己订单的业务场景中,就出现了全表扫描的情况,而且买家查看自己订单的请求是非常频繁的,必然给数据库带来扩展和性能的问题,有违“尽量减少事务边界”这一原则,这就需要有基于非拆分键的查询的方案。
二、非拆分键的查询
基于订单数据的分库分表场景,按照订单id取模虽然很好地满足了订单数据均匀地保存在数据库中,但在买家查看自己订单的业务场景中,就出现了全表扫描的情况,而且买家查看自己订单的请求是非常频繁的,必然给数据库带来扩展和性能的问题,有违“尽量减少事务边界”这一原则。
1.异构索引
针对这类场景问题,最常用的是采用“异构索引表”的方式解决,即采用异步机制将原表的每一次创建或更新,都换另一个维度保存一份完整的数据表或索引表,拿空间换时间。
也就是应用在穿件或更新一条订单ID为分库分表键的订单数据时,也会再保存一份按照买家ID为分库分表键的订单索引数据,其结果就是同一买家的所有订单索引表都保存在同一数据库中,这就是给订单创建了异构索引表。
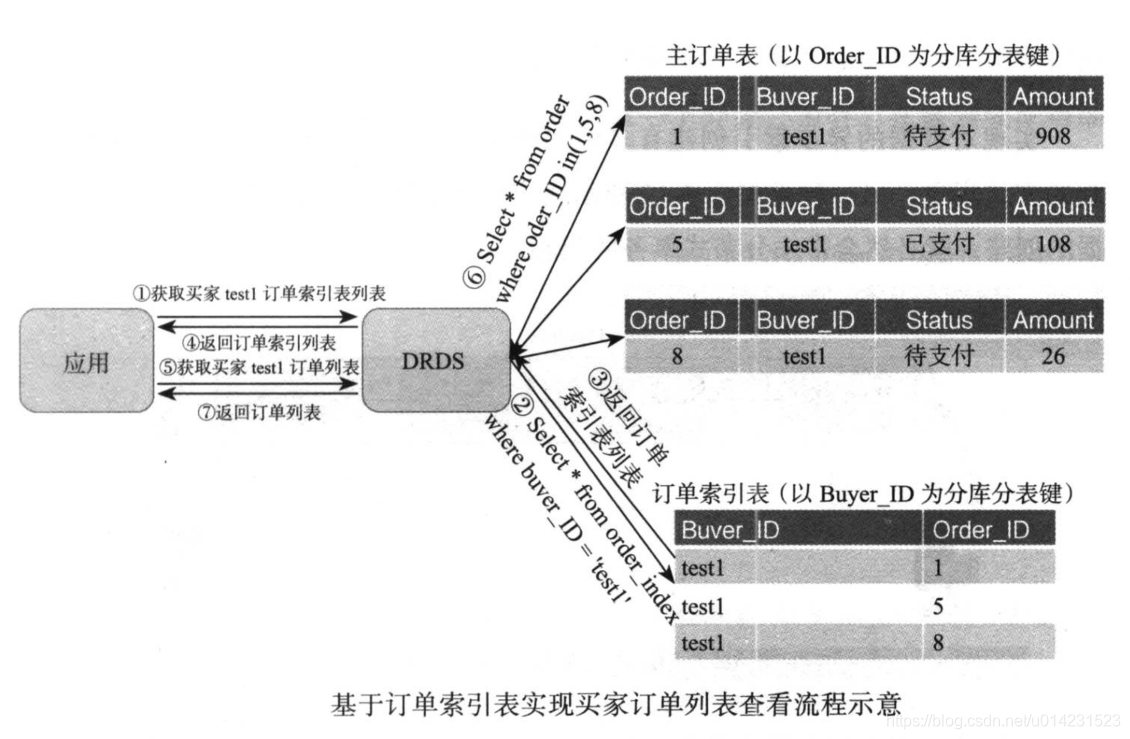
这时再来看看买家test1在获取订单信息进行页面展示时,应用对于数据库的访问流程就发生了如下图的变化。
在有了订单索引表后
- 首先到订单索引表中搜索出test1的所有订单索引表(步骤1)
- 因为步骤2的sql请求中带了以buyer_id的分库分表键,所以一次是效率最高的单库访问,
- 获取到了买家test1的所有订单索引表列表并由DRDS返回到前端应用(步骤3和4)
- 应用在拿到返回的索引列表后,获取到订单id列表(1,5,8)
- 再发送一次获取真正订单列表的请求(步骤5)
- 同样在步骤6的sql语句的条件中带了分库分表键order_id的列表值,所以DRDS可以精确地将此SQL请求发送到对应订单id的数据库中,而不会出现全表扫描的情况。最终通过两次访问效率最高的sql请求代替了之前的需要进行全表扫描的问题。
优化方案
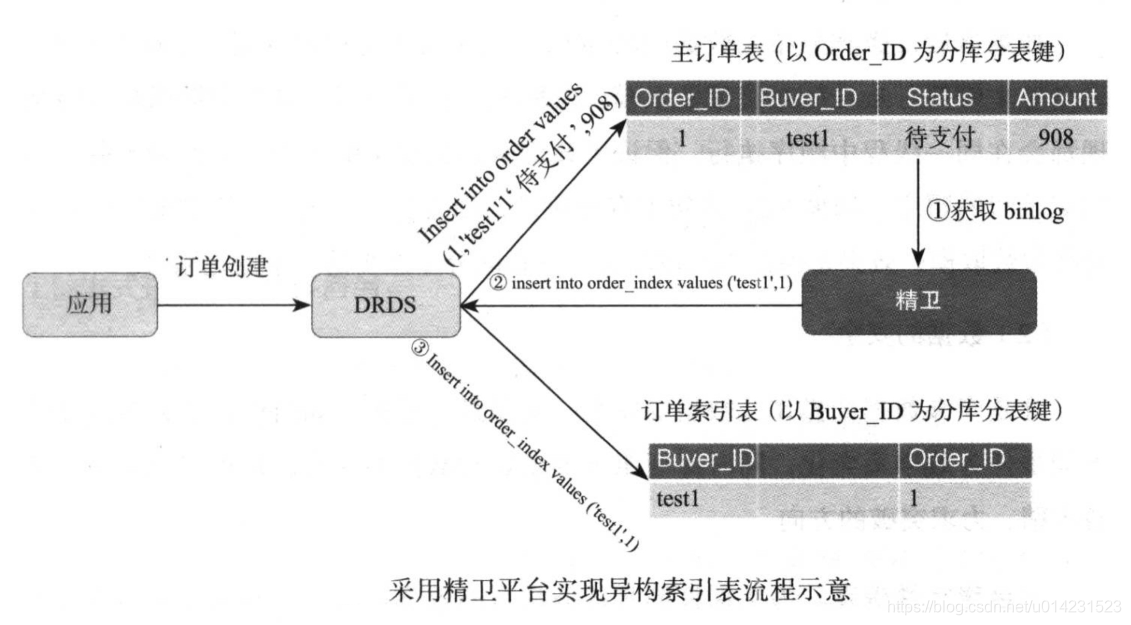
这里给大家介绍的是目前阿里内部使用的方式,命名为精卫(精卫填海)。精卫是一个基于Mysql的实时数据复制框架,也可以认为是一个Mysql的数据触发器+分发管道。
精卫通过抽取器(Extractor)获取到订单数据创建在Mysql数据库中产生的binlog日志,并转换为event对象,然后通过过滤器Filter(比如字段过滤、转换等)或基于接口自定义开发的过滤对event对象中的数据进行处理,最终对分发器Applier将结果转换为发给DRDS的sql语句。通过精卫实现异构索引数据的过程如图
2.RANGE_HASH 即复合索引
range_hash有以下特性
- 拆分键的类型必须是字符类型或数字类型
- 根据任一拆分键后 N 位计算哈希值,然后再按分库数去取余,完成路由计算。N 为函数第三个参数。例如:RANGE_HASH(COL1, COL2, N) ,计算时会优先选择 COL1,截取其后N位进行计算。 COL1 不存在时找 COL2。
- 适合于需要有两个拆分键,并且查询时仅有其中一个拆分键值的场景。
- 两个拆分键皆不能修改。
- 插入数据时如果发现两个拆分键指向不同的分库或分表时,插入会失败。
针对上一个例子,使用这个功能就可以解决问题。可以这样设计订单表,拆分键选择 user_id & order_id,在 order_id 中冗余 user_id 后 N 位。这样使用 RANGE_HASH(user_id, order_id, N) 功能即可以实现仅使用 user_id 或 order_id 条件就可以快速查询所需要的数据。因为同一个user_id的后N位是一样的,这样可以保证所有用户的订单都会保存在同一个表中,在查询时只需要根据路由信息找到这张表即可。
参考:
https://blog.csdn.net/u014231523/article/details/88096413
https://developer.aliyun.com/article/174556
这篇关于分库分表下非拆分键的查询方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






