本文主要是介绍knn 邻居数量k的选取_k个最近邻居和k表示聚类有什么区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
knn 邻居数量k的选取
Are you confused with the k-Nearest Neighbor (k-NN) and k-means clustering? Let’s try to understand the difference between k-NN and k-means in simple words with examples.
重新您与k近邻(K-NN)和K-means聚类困惑? 让我们尝试通过示例简单地理解k-NN和k-means之间的区别。
Let me introduce some major differences between them before going to the examples. Don’t worry, I won’t talk much !!
在介绍示例之前,让我介绍它们之间的一些主要区别。 别担心,我不会说太多!
k-NN is a supervised machine learning while k-means clustering is an unsupervised machine learning. Yes! You thought it correct, the dataset must be labeled if you want to use k-NN.
k-NN是有监督的机器学习,而k-means聚类是无监督的机器学习。 是! 您认为正确,如果要使用k-NN,则必须标记数据集。
k-NN is versatile; it can be used for the classification and the regression problems as well. However, it is more widely used in classification problems in the industry. k-means is used for the clustering. But what is clustering?
k-NN是通用的; 它也可以用于分类和回归问题。 但是,它更广泛地用于行业中的分类问题。 k均值用于聚类。 但是什么是集群?
Clustering is simply grouping the samples of the dataset in such a way that objects in the same group are more similar to each other than to those in other groups.
聚类只是将数据集的样本进行分组,以使同一组中的对象彼此之间的相似性高于其他组中的对象。
You can try to group the following into two: monkey, dog, apple, orange, tiger, and banana for better understanding! I am sure you did it right. Let’s move on.
您可以尝试将以下内容分为两类:猴子,狗,苹果,橙子,老虎和香蕉,以更好地理解! 我相信你做对了。 让我们继续前进。
k-NN is a lazy learning and non-parametric algorithm, i.e. it has no training phase (machine learning without training phase! Sounds weird!!) and no prediction power (again!!). It memorizes the data set (call it training if you want) and when a new test sample appears, it calculates(or selects) the label. Unlike k-NN, k-means has a model fitting and prediction power, which makes it an eager learner. In the training phase, the objective function is minimized, and the trained model predicts the label for test samples.
k-NN是一种惰性学习和非参数算法,即它没有训练阶段(机器学习没有训练阶段!听起来很奇怪! )并且没有预测能力(再次! )。 它存储数据集(如果需要,可将其称为训练),并在出现新的测试样品时计算(或选择)标签。 与k-NN不同,k-means具有模型拟合和预测能力,这使其成为了一个渴望学习的人。 在训练阶段,目标函数被最小化,并且训练后的模型可以预测测试样本的标签。
Enough talk, let’s see the examples.
足够多的讨论,让我们看看示例。
KNN分类: (KNN for classification:)
We have a dataset of the houses in Kaiserslautern city with the floor area, distance from the city center, and whether it is costly or not (Something being costly is a subjective thing, though!). Here, we have two classes, class 1: Costly and class 2: Affordable.
我们拥有凯撒斯劳滕(Kaiserslautern)市房屋的数据集,其中包括建筑面积,距市中心的距离以及是否昂贵(尽管昂贵是主观的事情!) 。 在这里,我们有两个类,第1类:昂贵,而第2类:负担得起。
In the scatter plot below, red dots show expensive and blue dots show affordable houses. Now we want to know whether a house with a 190 m² area and 6 km away from the city center (green dot in the figure) is expensive or affordable based on the given dataset. In simple words, we want to predict the class of the new data sample.
在下面的散点图中,红点表示昂贵,蓝点表示负担得起的房屋。 现在,根据给定的数据集,我们想知道面积为190平方米,距市中心6公里(图中的绿色点)的房屋是昂贵的还是负担得起的。 简而言之,我们要预测新数据样本的类别。
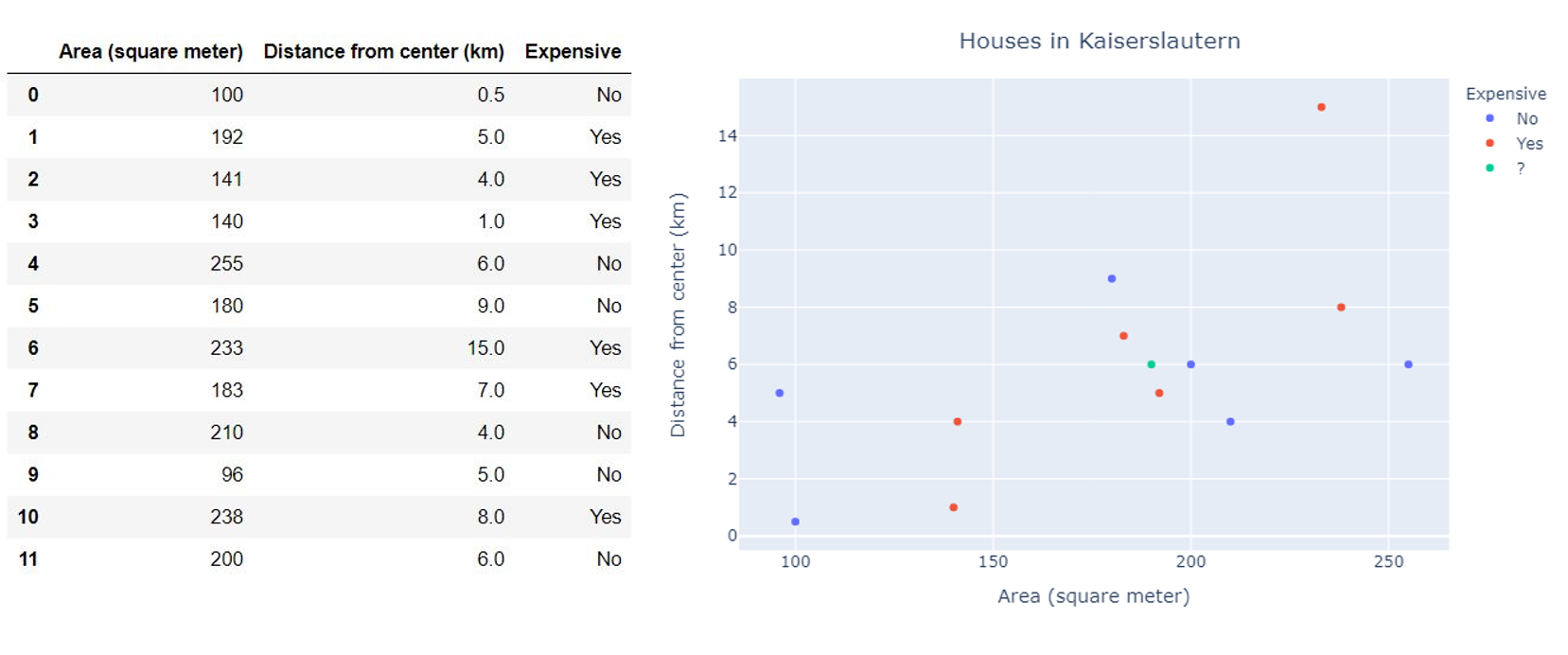
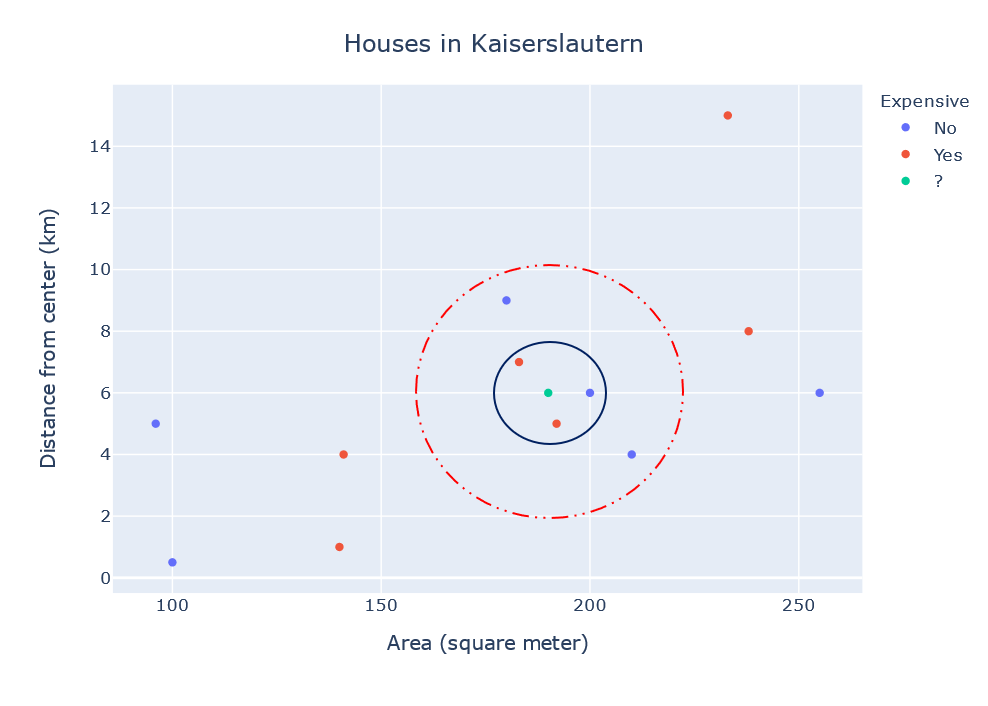
If we set k=3, then k-NN will find 3 nearest data points (neighbors) as shown in the solid blue circle in the figure and labels the test point according to the majority votes. In our case, the house will be labeled as ‘Costly’.!! Pause !!Think about setting k=2!Yes, k must be an odd number to avoid an equal number of votes!
如果我们设置k = 3,则k-NN将找到3个最接近的数据点(邻居),如图中的实心蓝色圆圈所示,并根据多数选票标记测试点。 在我们的案例中,这所房子将被标记为“成本高”。 !! 暂停! 想想设置k = 2!是的, k必须是一个奇数以避免投票数相等!
Let’s set k=5 for the same test sample. Now the majority class in 5 nearest neighbors is ‘Affordable’ (dotted red circle)! You got the point, right? The answer varies according to the value of k. The best choice of k depends on the dataset.
让我们为相同的测试样本设置k = 5。 现在,在5个最近的邻居中,多数阶层是“负担得起的”(红色圆圈)! 你明白了吧? 答案根据k的值而变化。 k的最佳选择取决于数据集。
K表示聚类: (K means clustering:)
We have a similar dataset with more samples, but there is no label. It consists of only distance from the city center and the floor area of houses.
我们有一个具有更多样本的相似数据集,但没有标签。 它仅包括距市中心和房屋建筑面积的距离。
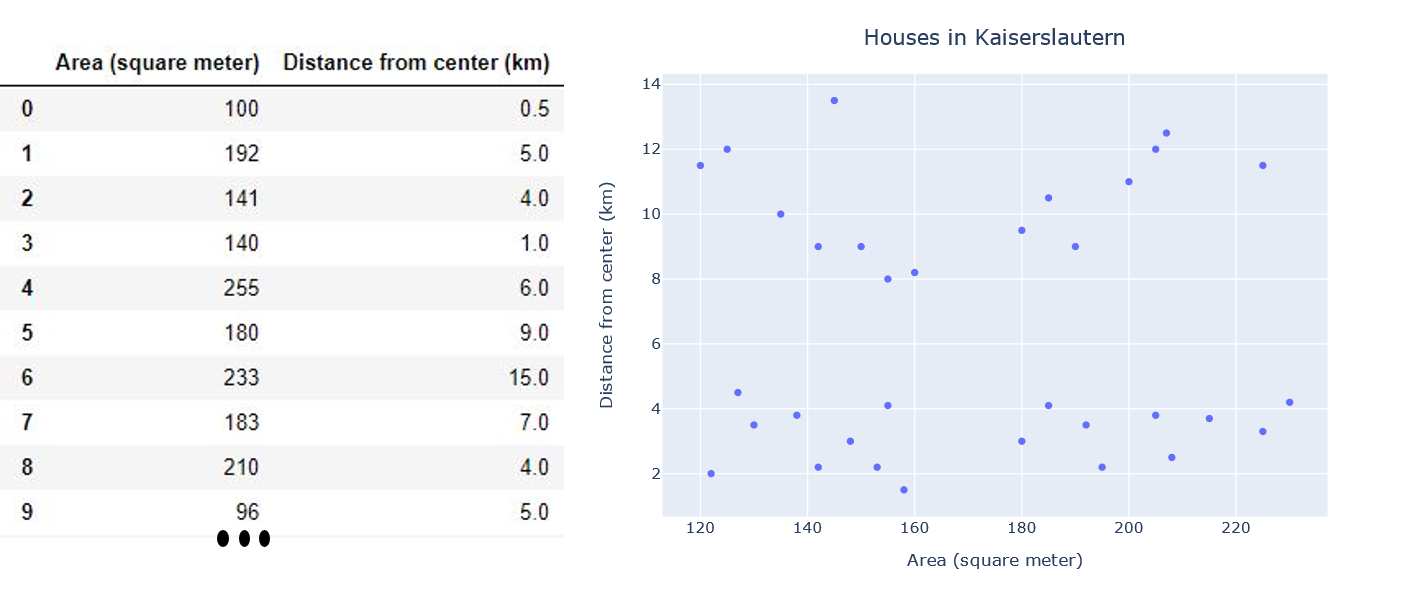
Let’s try to group the dataset into k=2 groups using k-means. The algorithm will initiate 2 centroids for 2 clusters. In each iteration of the training phase, centroids will move in such a way that the sum of the squared distance between data points and the cluster’s centroid is at the minimum. That’s it. The model is ready.
让我们尝试使用k均值将数据集分组为k = 2组。 该算法将为2个簇初始化2个质心。 在训练阶段的每次迭代中,质心将以这样的方式移动,即数据点和群集质心之间的平方距离之和最小。 而已。 模型已准备就绪。
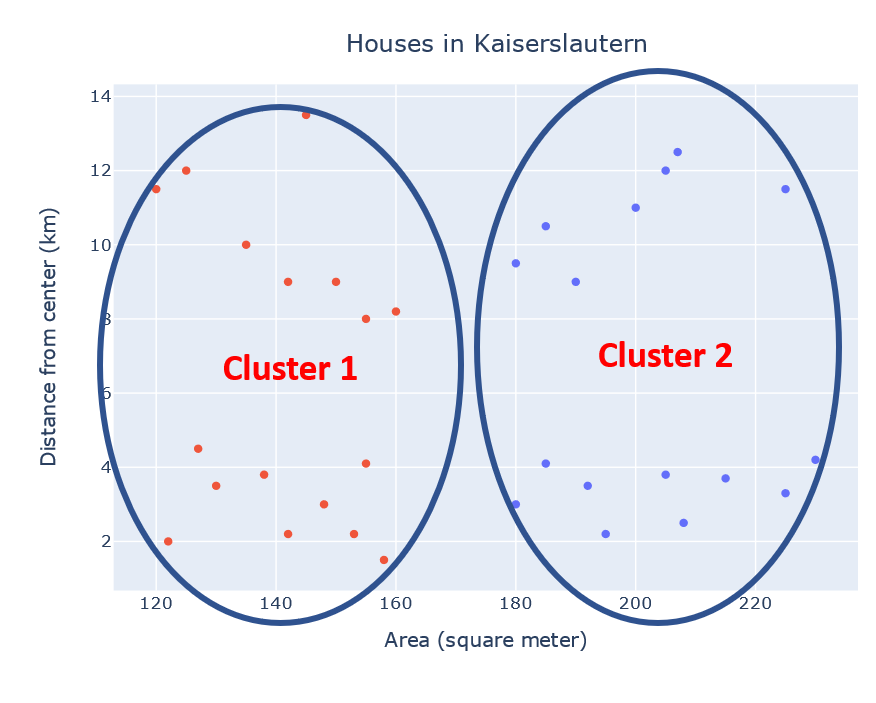
We have to check if having two clusters in our dataset makes any sense or not. I would say the cluster in the left shows affordable houses and the cluster in the right shows expensive houses. Wait a minute !!The interpretation I made is OK, but I am not satisfied with it. Let’s set k=4 for the same dataset.
我们必须检查数据集中是否有两个聚类是否有意义。 我要说的是,左边的集群显示的是负担得起的房子,右边的集群显示的是昂贵的房子。 等一下 !! 我所作的解释还可以,但我对此并不满意。 让我们为相同的数据集设置k = 4。
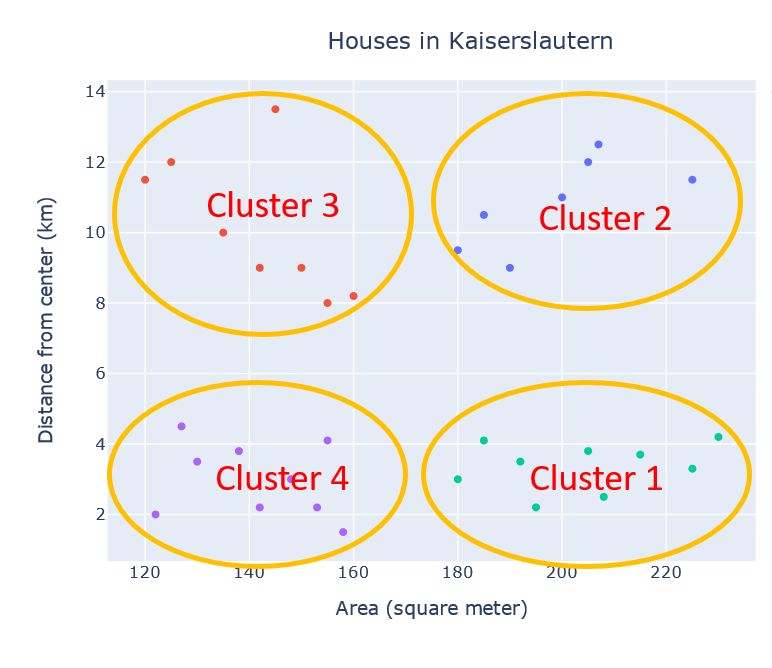
Now we have four groups, you can call them cluster 1: ‘near & large’, cluster 2: ‘far & large’, cluster 3: ‘far & small’, cluster 4: ‘near & small’. You can try to extract some meaning from these clusters. I think houses in cluster 1 are super expensive and noisy while cluster 2 shows affordable and calm houses. cluster 3 shows cheap and calm houses and the houses in cluster 4 are affordable but noisy. You can try to cluster them into different values of k and see if it makes any logic.
现在我们有四个组,您可以将它们称为群集1:“近而大”,群集2:“远而大”,群集3:“远而小”,群集4:“近而小” 。 您可以尝试从这些群集中提取一些含义。 我认为第1组的房屋价格昂贵且嘈杂,而第2组的房屋价格合理且安静。 第3组显示便宜且平静的房屋,第4组中的房屋负担得起,但嘈杂。 您可以尝试将它们聚类为k的不同值,看看它是否构成逻辑。
The Elbow method can be used to choose the value of k. However, this method only suggests the range of the k and you have to choose the value of k according to your dataset. We have a new house with an area of 165 m² and a distance from the city center 6 km. Now model can calculate the distance of the new test point from all four centroids of four clusters and predict in which cluster the new house fits well.
肘法可用于选择k的值。 但是,此方法仅建议k的范围,您必须根据数据集选择k的值。 我们有一所新房子,面积为165平方米,距市中心6公里。 现在,模型可以从四个群集的所有四个质心计算新测试点的距离,并预测新房子适合哪个群集。
回归的KNN: (KNN for regression:)
Consider the same dataset we discussed in the k-NN for classification. Instead of classifying the new data sample, we want to calculate the price of the house.
Çonsider相同的数据集,我们在第k-NN分类讨论。 我们不想对新的数据样本进行分类,而是要计算房屋的价格。
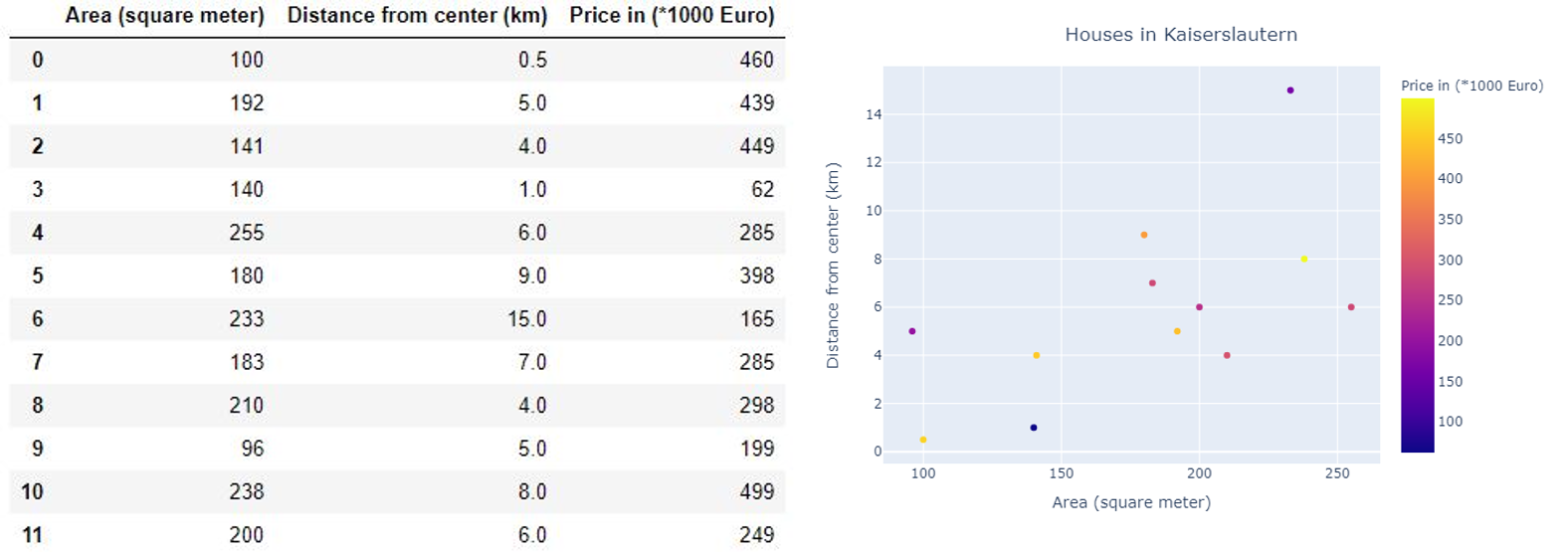
You are right! Labels of the main dataset must be the price of the house instead of classes.
你是对的! 主数据集的标签必须是房屋的价格,而不是类别的价格。
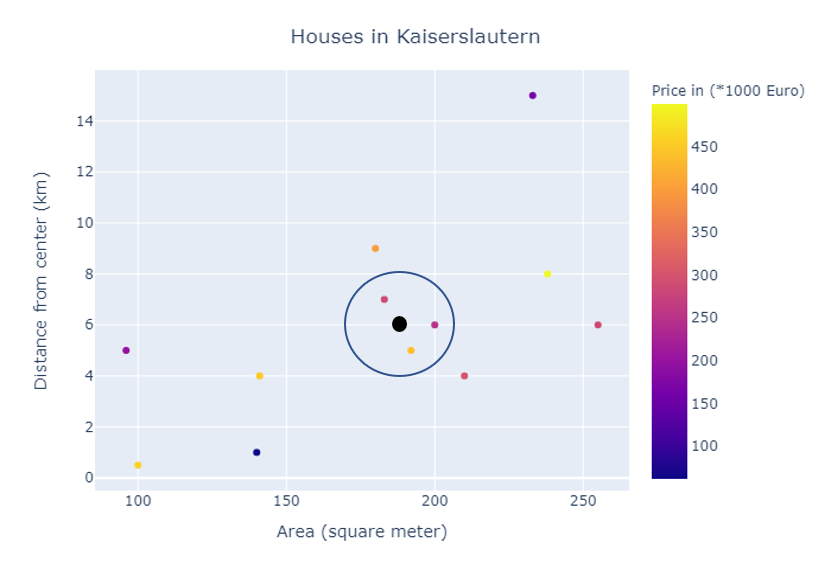
To calculate the price of the test sample, the algorithm will find k number of nearest neighbors the same as in classification but instead of voting for the majority, it will find the weighted mean of the prices of neighbors according to their distances from the test sample.
为了计算测试样本的价格,该算法将找到k个最接近的邻居,其数量与分类中的相同,但无需投票赞成多数,而是根据邻居与测试样本的距离找到加权价格的平均值。
In the figure, the black dot shows the test sample and the other three dots in the blue circle are nearest neighbors. The predicted price of the test sample will be the weighted mean of the prices of three dots in the blue circle.
在图中,黑点表示测试样品,蓝色圆圈中的其他三个点是最近的邻居。 测试样本的预测价格将是蓝色圆圈中三个点的价格的加权平均值。
Remember, the meaning of the k in k-NN and k-means is totally different.
请记住,k在k-NN和k-means中的含义完全不同。
All in all, k-NN chooses k nearest neighbors to vote for majority in classification problems and calculates weighted mean of labels in regression problems. While k-Means groups the dataset into k number of groups.
总而言之,在分类问题中,k-NN选择k个最近的邻居对多数票进行投票,并在回归问题中计算标签的加权平均值。 虽然k均值将数据集分为k个组。
翻译自: https://medium.com/swlh/what-is-the-difference-between-k-nearest-neighbors-and-k-means-clustering-21343f00b35d
knn 邻居数量k的选取
相关文章:
这篇关于knn 邻居数量k的选取_k个最近邻居和k表示聚类有什么区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





