本文主要是介绍Observability:使用适用于 Python 应用程序的 OpenTelemetry 进行自动检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Bahubali Shetti

DevOps 和 SRE 团队正在改变软件开发的流程。 虽然 DevOps 工程师专注于高效的软件应用程序和服务交付,但 SRE 团队是确保可靠性、可扩展性和性能的关键。 这些团队必须依赖全栈可观察性解决方案,使他们能够管理和监控系统,并确保问题在影响业务之前得到解决。
整个现代分布式应用程序堆栈的可观察性需要通常以仪表板的形式收集、处理和关联数据。 摄取所有系统数据需要跨堆栈、框架和提供程序安装代理,对于必须处理版本更改、兼容性问题和不随系统变化而扩展的专有代码的团队来说,这个过程可能具有挑战性且耗时。
得益于 OpenTelemetry (OTel),DevOps 和 SRE 团队现在拥有一种收集和发送数据的标准方法,该方法不依赖于专有代码,并且拥有大型社区支持,减少了供应商锁定。
在之前的博客中,我们还回顾了如何使用 OpenTelemetry 演示并将其连接到 Elastic®,以及 Elastic 与 OpenTelemetry 和 Kubernetes 的一些功能。
在本博客中,我们将展示如何通过我们名为 Elastiflix 的应用程序的 Python 服务来使用 OpenTelemetry 的自动检测,这有助于以简单的方式突出显示自动检测。
这样做的好处是不需要 otel-collector! 此设置使你能够根据最适合你业务的时间表,缓慢而轻松地将应用程序迁移到使用 Elastic 的 OTel。
应用程序、先决条件和配置
我们在这个博客中使用的应用程序称为 Elastiflix,一个电影流应用程序。 它由多个用 .NET、NodeJS、Go 和 Python 编写的微服务组成。
在我们检测示例应用程序之前,我们首先需要了解 Elastic 如何接收遥测数据。
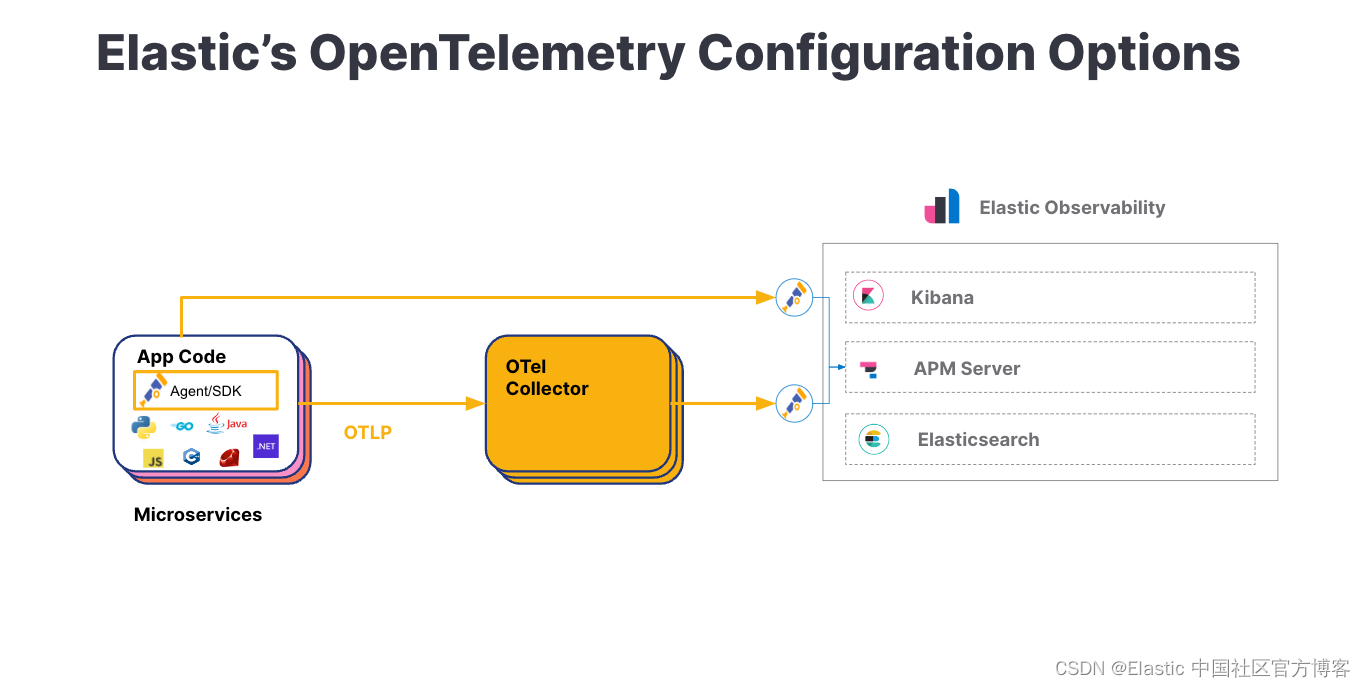
Elastic Observability 的所有 APM 功能均可通过 OTel 数据使用。 其中一些包括:
- 服务地图 - service maps
- 服务详细信息(延迟、吞吐量、失败的 transactions)
- 服务之间的依赖关系、分布式追踪
- Transactions(跟踪)
- 机器学习 (ML) 相关性
- 日志相关性
除了 Elastic 的 APM 和遥测数据的统一视图之外,你还可以使用 Elastic 强大的机器学习功能来减少分析,并发出警报以帮助降低 MTTR。
先决条件
- Elastic Cloud 帐户 — 立即注册
- 克隆 Elastiflix 演示应用程序,或您自己的 Python 应用程序
- 对 Docker 的基本了解 — 可能安装 Docker Desktop
- 对 Python 有基本的了解
查看示例源代码
完整的源代码,包括本博客中使用的 Dockerfile,可以在 GitHub 上找到。 该存储库还包含相同的应用程序,但没有检测。 这使你可以比较每个文件并查看差异。
以下步骤将向你展示如何实现此应用程序并在命令行或 Docker 中运行它。 如果你对更完整的 OTel 示例感兴趣,请查看此处的 docker-compose 文件,它将显示完整的项目。
分步指南
步骤 0:登录您的 Elastic Cloud 帐户
本博客假设你有 Elastic Cloud 帐户 - 如果没有,请按照说明开始使用 Elastic Cloud。
步骤 1:为 Python 服务配置自动检测
我们将通过 Elastiflix 演示应用程序中的 Python 服务使用自动检测。
我们将使用 Elastiflix 的以下服务:
Elastiflix/python-favorite-otel-auto根据 Python 文档的 OpenTelemetry 自动检测部分,你只需使用 pip install 安装适当的 Python 包即可。
>pip install opentelemetry-distro \opentelemetry-exporter-otlp>opentelemetry-bootstrap -a install如果你在命令行上运行 Python 服务,则可以使用以下命令:
opentelemetry-instrument python main.py对于我们的应用程序,我们将其作为 Dockerfile 的一部分来执行。
Dockerfile
FROM python:3.9-slim as base# get packages
COPY requirements.txt .
RUN pip install -r requirements.txt
WORKDIR /favoriteservice#install opentelemetry packages
RUN pip install opentelemetry-distro \opentelemetry-exporter-otlpRUN opentelemetry-bootstrap -a install# Add the application
COPY . .EXPOSE 5000
ENTRYPOINT [ "opentelemetry-instrument", "python", "main.py"]步骤 2:使用环境变量运行 Docker 镜像
按照 OTEL Python文档中的规定,我们将使用环境变量并传入配置值以使其能够与 Elastic Observability 的 APM 服务器连接。
由于 Elastic 本身接受 OTLP,因此我们只需要提供 OTEL Exporter 需要发送数据的端点和身份验证,以及一些其他环境变量。
获取 Elastic Cloud 变量
你可以从路径 /app/home#/tutorial/apm 下的 Kibana® 复制端点和令牌。

你将需要复制以下环境变量:
OTEL_EXPORTER_OTLP_ENDPOINT
OTEL_EXPORTER_OTLP_HEADERS构建镜像
docker build -t python-otel-auto-image .运行镜像
docker run \ -e OTEL_EXPORTER_OTLP_ENDPOINT="<REPLACE WITH OTEL_EXPORTER_OTLP_ENDPOINT>" \-e OTEL_EXPORTER_OTLP_HEADERS="Authorization=Bearer%20<REPLACE WITH TOKEN>" \-e OTEL_RESOURCE_ATTRIBUTES="service.version=1.0,deployment.environment=production" \-e OTEL_SERVICE_NAME="python-favorite-otel-auto" \-p 5001:5001 \python-otel-auto-image重要提示:请注意,“OTEL_EXPORTER_OTLP_HEADERS” 变量在 Bearer 转义为 “%20” 之后有空格 —— 这是 Python 的要求。
你现在可以发出一些请求来生成跟踪数据。 请注意,这些请求预计会返回错误,因为此服务依赖于你当前未运行的 Redis 连接。 如前所述,你可以在此处找到使用 docker-compose 的更完整示例。
curl localhost:5000/favorites# or alternatively issue a request every secondwhile true; do curl "localhost:5000/favorites"; sleep 1; done;步骤 3:探索 Elastic APM 中的跟踪、指标和日志
浏览 Elastic APM 中的服务部分,你将看到显示的 Python 服务。
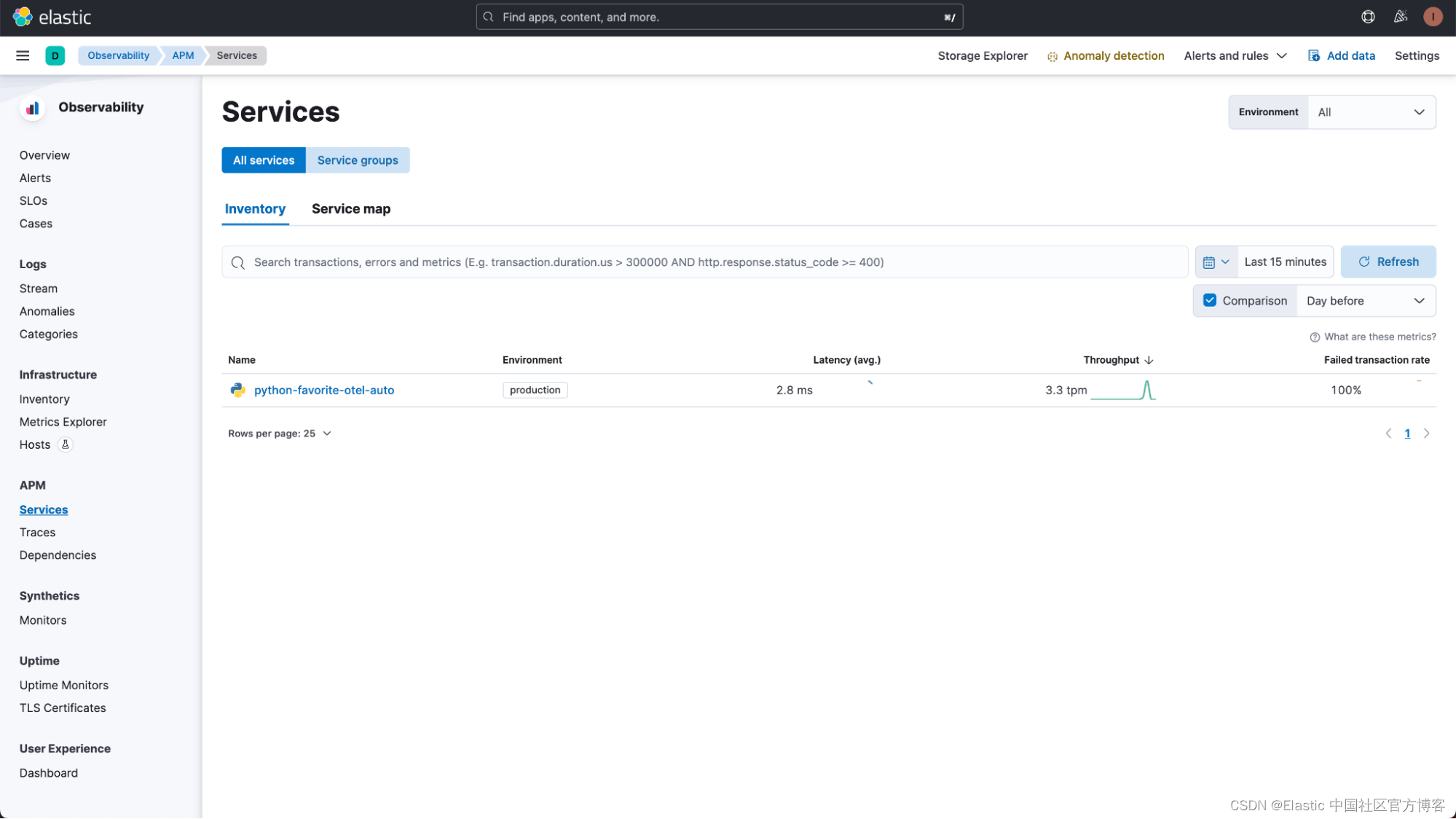
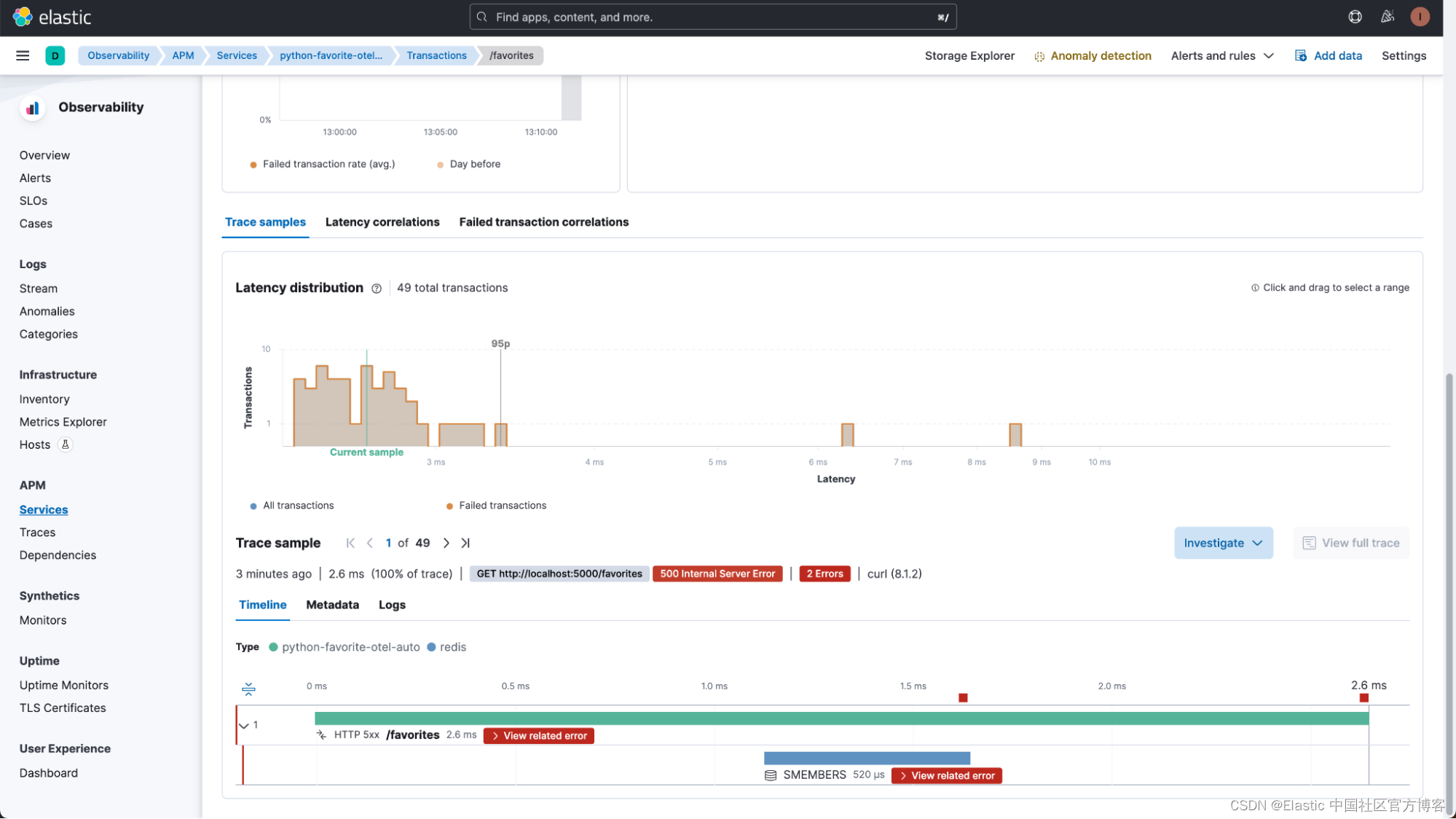
单击 python-favorite-otel-auto 服务,你可以看到它正在使用 OpenTelemetry 摄取遥测数据。
在这篇博客中,我们讨论了以下内容:
- 如何使用 OpenTelemetry 自动检测 Python
- 使用 Dockerfile 中的标准命令,可以高效地完成自动检测,无需在多个位置添加代码
由于 Elastic 可以支持多种摄取数据的方法,无论是使用开源 OpenTelemetry 的自动检测还是使用其本机 APM 代理进行手动检测,你都可以先关注一些应用程序,然后稍后使用 OpenTelemertry 以最适合你的业务需求的方式在你的应用程序中展开。
原文:Auto-instrumentation of Python applications with OpenTelemetry | Elastic Blog
这篇关于Observability:使用适用于 Python 应用程序的 OpenTelemetry 进行自动检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




