本文主要是介绍基于“Galera+MariaDB”搭建多主数据库集群的实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、什么是多主数据库集群
多主数据库集群是一种数据库集群架构,每个节点都可以接收写入操作和读取操作,并且通过心跳机制同步数据,保证数据一致性和高可用性。因多主数据库集群每个节点都可以承担读写操作,因此它可以充分利用各个节点的服务器资源,不存在主备数据库集群那样,备库只承担备份复制而不承担业务请求,使得备库所在的服务器资源处于近乎“闲置”的状态。
2、多主数据库集群和主备数据库集群的优缺点对比
主备数据库和多活数据库是两种常见的数据库架构,它们各有优缺点。
主备数据库的优点:
- 简单:主备数据库架构相对简单,易于理解和实现;
- 成本较低:主备数据库架构的成本相对较低,因为只需要两台数据库服务器,一台为主服务器,一台为备用服务器;
- 数据安全:主备数据库架构可以保证数据的安全性,因为数据会定期从主服务器复制到备用服务器。
主备数据库的缺点:
- 可用性:如果主服务器出现故障,备用服务器需要接管主服务器的任务,这可能会导致一定的延迟;
- 性能:由于主备数据库架构只有一台主服务器,如果主服务器出现故障,所有读写请求都需要转移到备用服务器上,这可能会导致性能下降。
多活数据库的优点:
- 高可用性:多活数据库架构可以保证高可用性,因为多个节点都可以处理读写请求;
- 负载均衡:多活数据库架构可以实现负载均衡,将读写请求分散到多个节点上,提高性能;
- 容错性:如果某个节点出现故障,其他节点可以继续提供服务,保证系统的可用性。
多活数据库的缺点:
- 复杂性:多活数据库架构相对复杂,需要解决数据一致性、冲突处理等问题;
- 成本较高:多活数据库架构需要更多的数据库服务器和网络设备,成本相对较高;
- 数据一致性:在多活数据库架构中,数据一致性是一个重要的问题,需要采用各种技术手段来保证。
3、基于“Galera+MariaDB”搭建多主数据库集群示例
3.1、实验拓扑
本文将演示“Galera+MariaDB”多活数据库集群搭建的简单实例,拓扑如下:

在设计“Galera+MariaDB”这样的技术组合时,为防止上线后在运行过程中出现节点和节点之间数据不一致(脑裂)情况的发生,根据Galera的官方文档,通常建议节点数应当设计为奇数个数据库节点,但如果因为实际的环境或者成本受限等原因无法部署奇数个数据库节点时,就可以考虑单独部署一个Galera Arbitrator节点。
Galera Arbitrator本身不参与复制,但它和其他节点一样也会接受数据,Galera Arbitrator是集群中的一份子,因此它被视为仲裁节点,可以参与投票。
3.2、搭建方式的实现
3.2.1、Galera+MariaDB节点1部署步骤(OpenEuler22.03LTS)
(1)配置好OpenEuler22.03LTS的官方源或者镜像源,并关闭SELinux,通过命令“yum install mariadb-server mariadb-server-galera galera”安装基础软件;
(2)输入命令“systemctl start mariadb”启动MariaDB数据库;
(3)通过“mysql_secure_installation”命令对该节点的MariaDB数据库进行初始化;
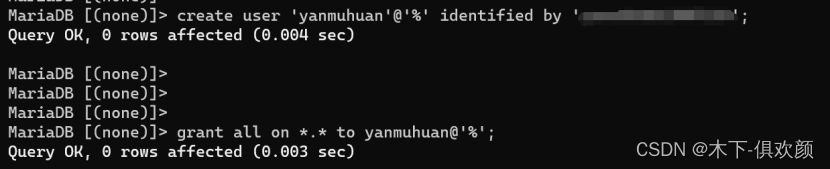
(4)根据实际的业务系统情况创建用户,并授予相应的权限,在本实验环境下,我们创建一个名为“yanmuhuan”的用户,并赋予所有的权限和允许远程访问;
(5)输入命令“systemctl stop mariadb”停止MariaDB数据库;
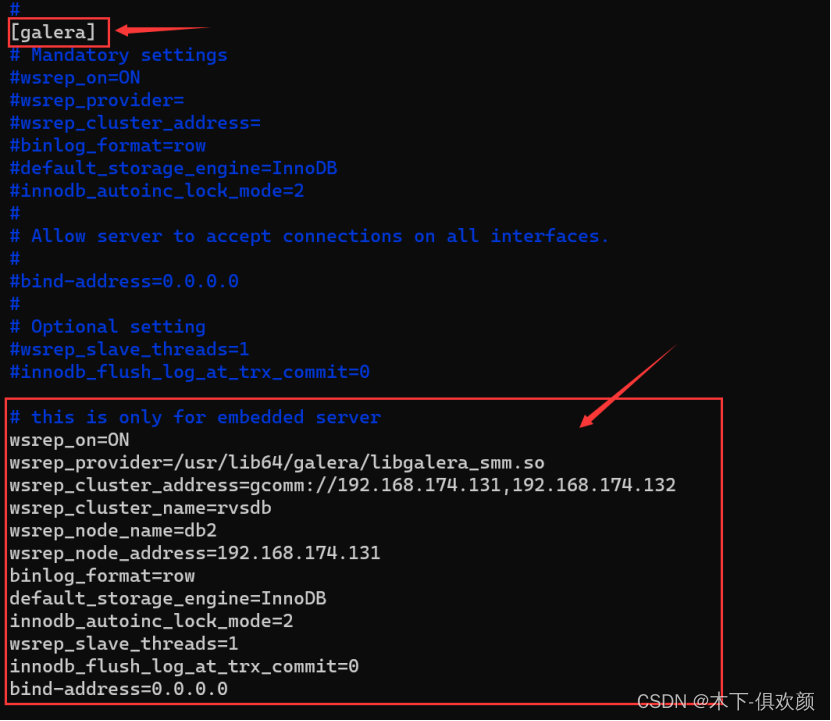
(6)输入命令“vim /etc/my.cnf.d/mariadb-server.cnf”,修改mariadb-server.cnf文件,在“[galera]”下,添加如下内容:
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.174.131,192.168.174.132
wsrep_cluster_name=rvsdb
wsrep_node_name=db2
wsrep_node_address=192.168.174.131
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
wsrep_slave_threads=1
innodb_flush_log_at_trx_commit=0
bind-address=0.0.0.0
需要注意的是,以上配置参数中,我们需要关注以下几个参数的含义:
- wsrep_cluster_address:集群所包含的节点IP地址;
- wsrep_cluster_name:集群名称,集群创建时可任取,但创建完成后要求成员节点的该参数一致;
- wsrep_node_name:节点名称,集群内不同节点的节点名称应当不同;
- wsrep_node_address:本节点IP地址
- default_storage_engine:MariaDB默认使用的数据库引擎,都使用InnoDB,因为Galera只支持InnoDB引擎;
- bind-address:本节点允许被哪些IP网段访问。
(7)输入命令“galera_new_cluster”命令,将本节点作为多活数据库集群的主节点启动galera集群进程和MariaDB数据库进程。

3.2.2、Galera+MariaDB节点2部署步骤(OpenEuler22.03LTS)
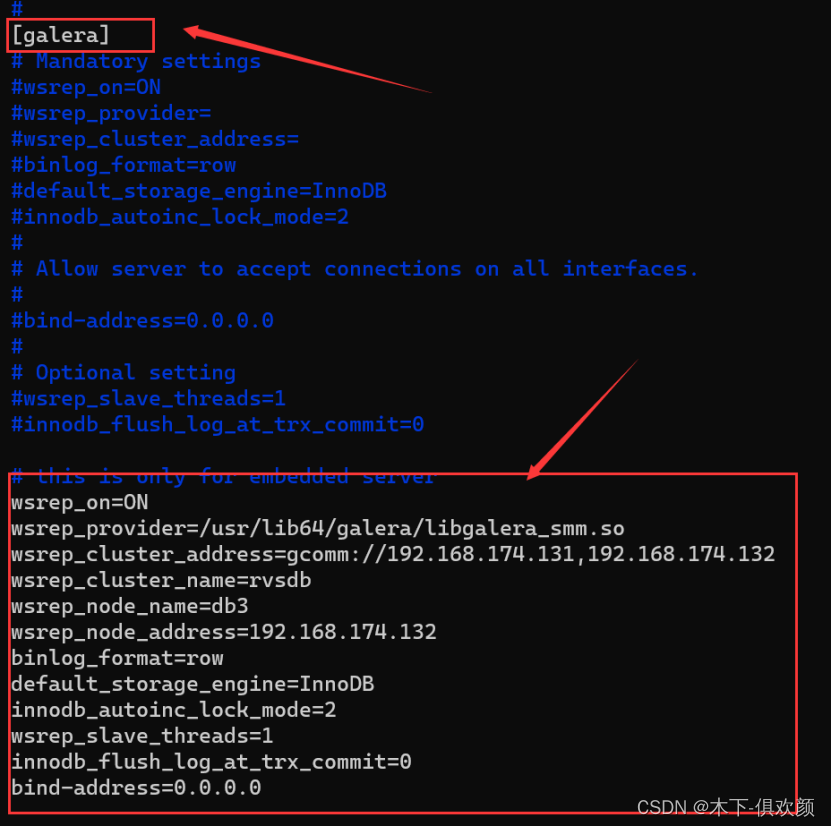
此节点配置方式基本与节点1一致,只是/etc/my.cnf.d/mariadb-server.cnf这个配置文件需要根据实际情况做成如下修改:
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.174.131,192.168.174.132
wsrep_cluster_name=rvsdb
wsrep_node_name=db3
wsrep_node_address=192.168.174.132
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
wsrep_slave_threads=1
innodb_flush_log_at_trx_commit=0
bind-address=0.0.0.0
最后启动数据库时,通过正常的“systemctl start mariadb”启动数据库,而不用“galera_new_cluster”命令。
3.2.3、Galera Arbitrator节点部署步骤(debian12)
在debian12系统中,Galera Arbitrator需要单独安装,而OpenEuler和CentOS等红帽系Linux中,Galera Arbitrator则已经集成在galera的rpm标准软件中,无须单独安装。
(1)输入命令“apt install galera-arbitrator-4”安装Galera Arbitrator;

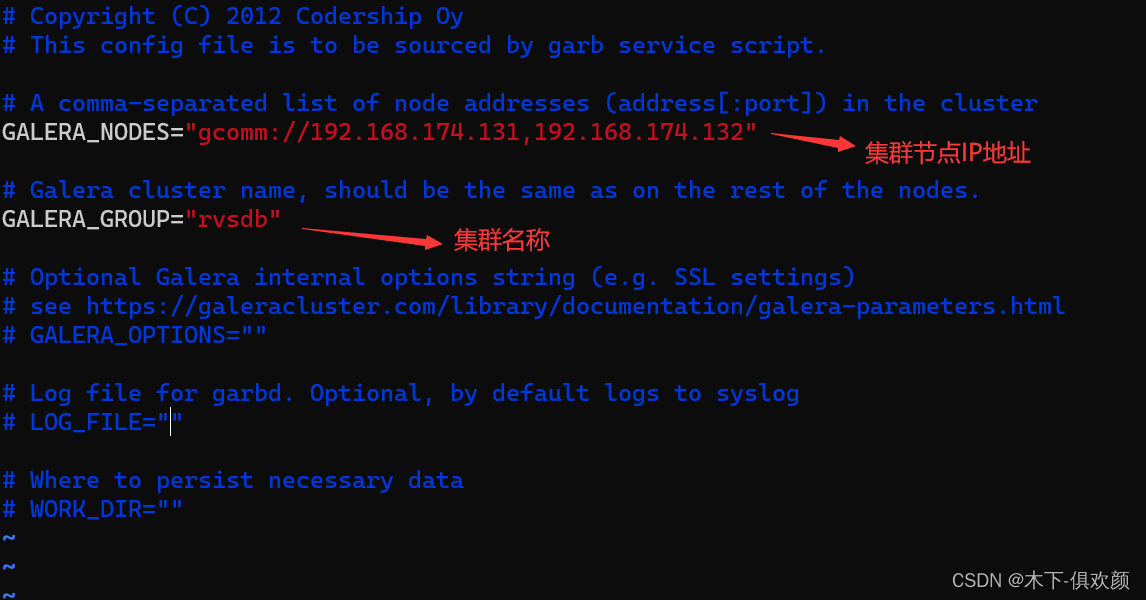
(2)输入命令“vim /etc/default/garb”修改Galera Arbitrator的配置文件,内容如下;
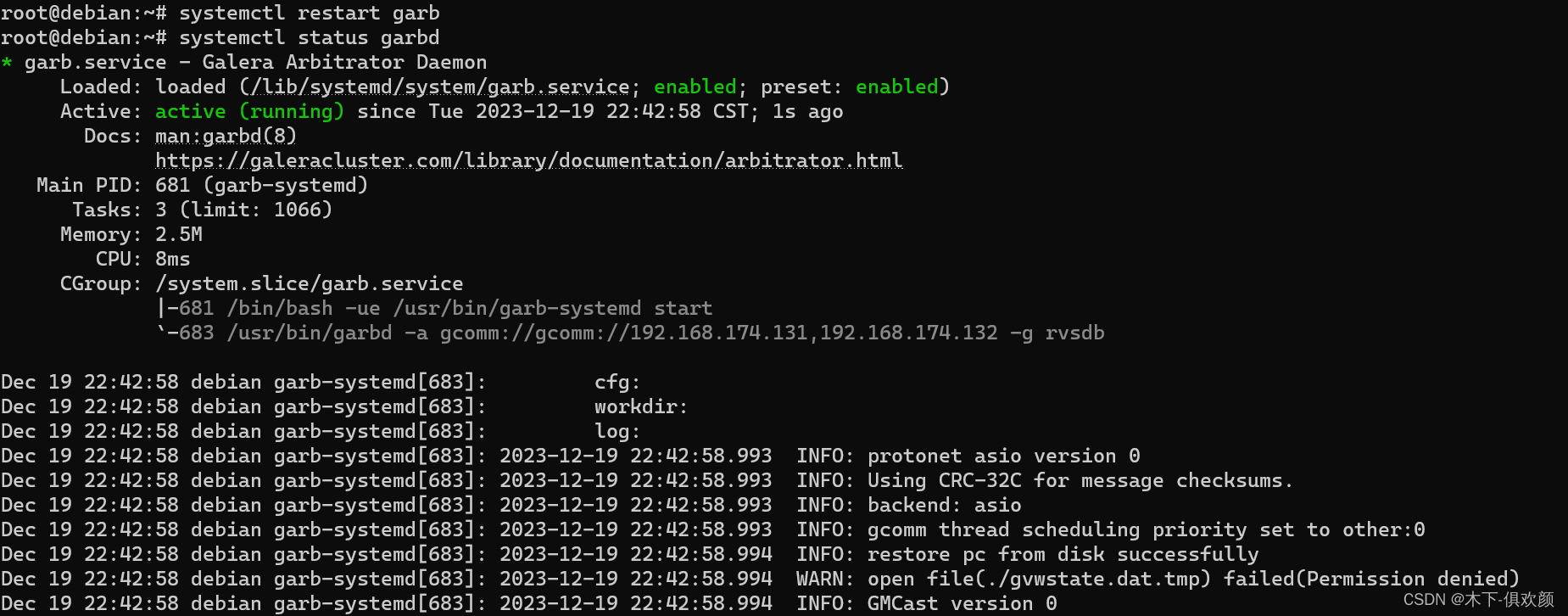
(3)输入命令“systemctl restart garb”启动Galera Arbitrator;
(4)通过命令“systemctl status grab”,正常的Galera Arbitrator进程结果,如下:
(5)输入命令“garbd -a gcomm://192.168.174.132:4567 -g rvsdb -d”加入集群;

(6)任意节点登录MariaDB,通过“show status like 'wsrep_%”命令,找到wsrep_cluster_size参数,可看到节点数为3(2个MariaDB+1个Galera Arbitrator);

(7)在任意数据库节点对数据库进行读写操作(增删改),发现所有节点的数据内容变动是同步的。
3.2.4、知识补充:debian12下部署Galera+MariaDB节点与OpenEuler下部署的差别
(1)debian下部署Galera+MariaDB节点的命令为:“apt-get install galera mariadb-server”,这意味着在debian系Linux软件仓库中的MariaDB已经集成了Galera,并不会像OpenEuler等红帽系Linux中需要部署单独的“mariadb-server-galera”版本;
(2)针对于debian下Galera的配置文件,需要在/etc/mysql/conf.d/目录下添加单独的“galera.cnf”(名字可以任意)文件,并添加和红帽系Linux一样,例如以下格式的内容,具体参数根据实际情况修改:
[galera]
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.174.129,192.168.174.130
wsrep_cluster_name=rvsdb
wsrep_node_name=db1
wsrep_node_address=192.168.174.129
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
wsrep_slave_threads=1
innodb_flush_log_at_trx_commit=0
bind-address=0.0.0.0
(3)其余步骤与OpenEuler或CentOS等Linux系统一致。
3.3、结果测试
任意节点登录MariaDB数据库,输入命令“show status like 'wsrep_%';”可查看相应的集群状态。

其中,应当着重关注以下参数:
- wsrep_cluster_state_uuid:集群UUID,集群中所有节点此参数相同;
- wsrep_cluster_size:集群节点数量;
- wsrep_connected:本节点与集群通信状态。
其他参数不代表不重要,可以具体查阅相应资料。
4、注意事项
4.1、Galera+MariaDB节点和节点之间的Galera版本和MariaDB要严格匹配
Galera+MariaDB节点和节点之间的Galera版本和MariaDB要严格匹配,否则将出现节点因为版本不匹配的问题无法加入集群,根据实际的实验现场来看,建议节点和节点的Linux操作系统、MariaDB和Galera版本完全一致。而Galera Arbitrator和Galera+MariaDB节点之间的版本匹配则不是这么严格。
4.2、对集群关机维护与重启的标准操作
若要对集群服务器进行关机维护,集群应先停止对外服务,确认数据库没有来自对外的读写操作后进行关机,并应记好关机顺序,维护完成后按关机顺序的相反顺序进行开机,并启动数据库进程,例如,关机顺序为A>B>C,那么开机顺序则为C>B>A,且开机时的C应执行“galera_new_cluster”,后面启动的节点用“systemctl start mariadb”正常启动数据库。
若忘记关机顺序,则在启动之前,应通过命令“cat /var/lib/mysql/grastate.dat”查看“safe_to_bootstrap”字段的数值,若发现有节点的数值为“1”,则首先通过“galera_new_cluster”启动该节点,其他节点用“systemctl start mariadb”正常启动。
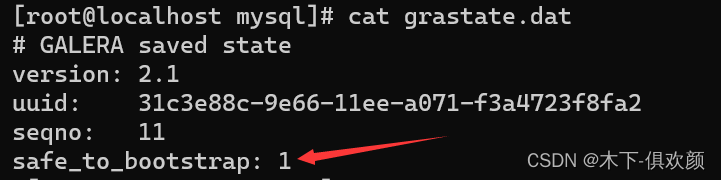
若所有节点的/var/lib/mysql/grastate.dat文件里,safe_to_bootstrap字段都为0,则可以根据实际情况选择一个节点手动将该数值修改为1,而后通过“galera_new_cluster”启动该节点,其他节点用“systemctl start mariadb”正常启动,此方法也是当节点之间数据不一致(脑裂)发生时,强制启动数据库集群恢复业务的方法,但这种方法很可能会造成部分数据的丢失。

这篇关于基于“Galera+MariaDB”搭建多主数据库集群的实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






