本文主要是介绍SQL Server 查询处理过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
查询处理--由 SQL Server 中的关系引擎执行,它获取编写的 T-SQL 语句并将其转换为可以向存储引擎发出请求并检索所需结果的过程。
SQL Server 需要四个步骤来处理查询:分析、代化、优化和执行。
前三个步骤都由关系引擎执行;第三步输出的是优化计划,在此期间,将调用存储引擎以检索将成为正在执行的查询结果数据。
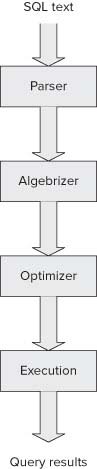
解析在分析阶段,SQL Server 对源代码(T-SQL 语句)执行基本检查。此分析查找无效的 SQL 语法,例如不正确地使用保留字、列名和表名等。 如果解析完成且没有错误,它将生成一个解析树,该树将传递到查询处理的下一阶段,即绑定。解析树是查询的内部表示形式。如果分析检测到任何错误,进程将停止并返回错误。
代化阶段也称为绑定阶段。在早期版本的 SQL Server 中,此阶段称为规范化。在代化过程中,SQL Server 对分析树执行多个操作,然后生成传递查询树给查询优化器。 代化期间执行的步骤遵循以下模型:
- 步骤 1:名称解析 — 确认所有对象都存在并在用户的安全上下文中可见。这是检查表和列名称以确保它们存在并且用户有权访问它们的位置。
- 步骤 2:类型派生 — 确定解析树中每个节点最终类型
- 步骤 3:聚合绑定 — 确定在何处进行任何聚合
- 步骤 4: 组绑定 — 将任何聚合绑定到相应的选择列表
在此阶段检测到语法错误。如果遇到语法错误,优化过程将停止,并将错误返回给用户。
喜欢的话,请收藏 | 关注!
万一有趣的事还在后头呢!
这篇关于SQL Server 查询处理过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





